
GPT-4 Versagt bei echten Aufgaben im Gesundheitswesen: Neuer HealthBench-Test deckt die Lücken auf

In Kürze Forscher stellten HealthBench vor, einen neuen Benchmark, der LLMs testet wie GPT-4 und Med-PaLM 2 zu realen medizinischen Aufgaben.
Große Sprachmodelle sind allgegenwärtig – von der Suche über die Kodierung bis hin zu patientenorientierten Gesundheitstools. Fast wöchentlich werden neue Systeme eingeführt, darunter Tools, die versprechen zur Automatisierung klinischer Arbeitsabläufe Aber kann man ihnen tatsächlich vertrauen, echte medizinische Entscheidungen zu treffen? Ein neuer Benchmark namens HealthBench sagt: Nein. Den Ergebnissen zufolge sind Modelle wie GPT-4 (Ab OpenAI) und Med-PaLM 2 (von Google DeepMind) erfüllen bei praktischen Aufgaben im Gesundheitswesen immer noch nicht die Anforderungen, insbesondere wenn es auf Genauigkeit und Sicherheit ankommt.
HealthBench unterscheidet sich von älteren Tests. Statt eng gefasster Quizze oder akademischer Fragenkataloge werden KI-Modelle mit realen Aufgaben konfrontiert. Dazu gehören die Auswahl von Behandlungen, das Stellen von Diagnosen und die Entscheidung über die nächsten Schritte eines Arztes. Dadurch werden die Ergebnisse relevanter für den möglichen Einsatz von KI in Krankenhäusern und Kliniken.
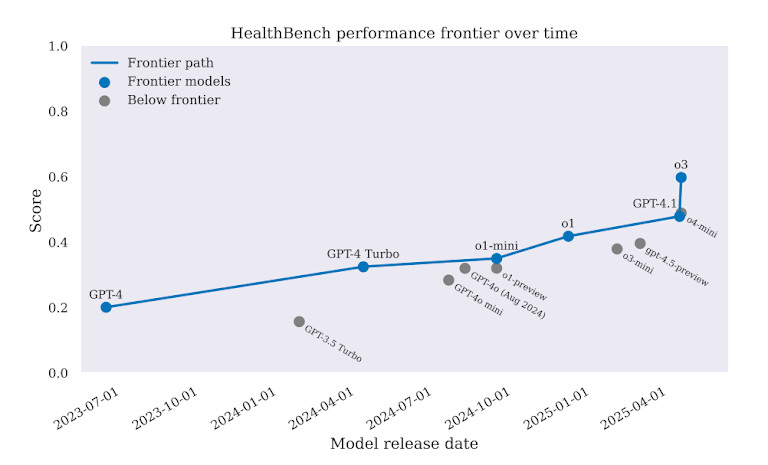
Über alle Aufgaben hinweg GPT-4 schnitten besser ab als frühere Modelle. Aber der Vorsprung reichte nicht aus, um den Einsatz in der Praxis zu rechtfertigen. In einigen Fällen GPT-4 wählte falsche Behandlungen. In anderen Fällen gab sie Ratschläge, die die Behandlung verzögern oder sogar den Schaden erhöhen konnten. Der Benchmark macht eines deutlich: KI mag intelligent klingen, aber in der Medizin reicht das nicht aus.
Echte Aufgaben, echte Misserfolge: Wo KI in der Medizin noch immer schwächelt
Einer der größten Beiträge von HealthBench ist die Art und Weise, wie es Modelle testet. Es umfasst 14 reale Aufgaben aus dem Gesundheitswesen in fünf Kategorien: Behandlungsplanung, Diagnose, Pflegekoordination, Medikamentenmanagement und Patientenkommunikation. Diese Fragen sind nicht frei erfunden. Sie basieren auf klinischen Leitlinien, offenen Datensätzen und von Experten verfassten Ressourcen, die die tatsächliche Funktionsweise des Gesundheitswesens widerspiegeln.
Bei vielen Aufgaben zeigten große Sprachmodelle konsistente Fehler. Zum Beispiel: GPT-4 Häufig scheiterten sie bei klinischen Entscheidungen, beispielsweise bei der Entscheidung, wann Antibiotika verschrieben werden sollten. In manchen Fällen wurden zu viele Antibiotika verschrieben. In anderen Fällen wurden wichtige Symptome übersehen. Solche Fehler sind nicht nur falsch – sie können in der Patientenversorgung echten Schaden anrichten.
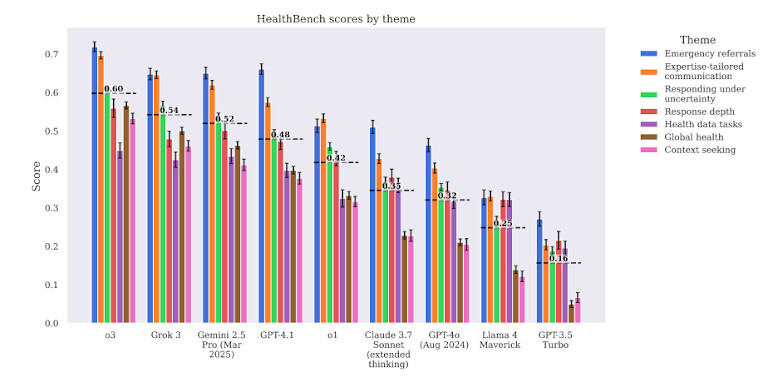
Die Modelle hatten auch mit komplexen klinischen Arbeitsabläufen zu kämpfen. So wurden sie beispielsweise gebeten, Folgemaßnahmen nach Laborergebnissen zu empfehlen. GPT-4 Die Beratung erfolgte allgemein oder unvollständig. Oft wurde der Kontext außer Acht gelassen, die Dringlichkeit nicht berücksichtigt oder es fehlte an klinischer Tiefe. Das macht die Vorgehensweise in Fällen gefährlich, in denen Zeit und Reihenfolge der Operationen entscheidend sind.
Bei medikamentenbezogenen Aufgaben sank die Genauigkeit weiter. Die Modelle verwechselten häufig Wechselwirkungen oder gaben veraltete Empfehlungen. Das ist besonders besorgniserregend, da Medikationsfehler bereits heute eine der Hauptursachen für vermeidbare Schäden im Gesundheitswesen sind.
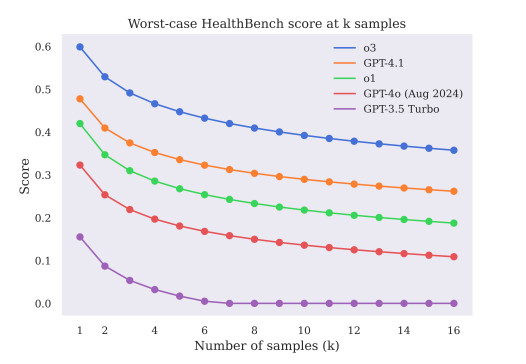
Selbst wenn die Modelle überzeugend klangen, lagen sie nicht immer richtig. Der Benchmark zeigte, dass Sprachfluss und Tonfall nicht der klinischen Korrektheit entsprachen. Dies ist eines der größten Risiken von KI im Gesundheitswesen – sie kann menschlich klingen, obwohl sie faktisch falsch ist.
Warum HealthBench wichtig ist: Echte Evaluation für echte Wirkung
Bisher verwendeten viele KI-basierte Gesundheitsbewertungen akademische Fragenkataloge wie MedQA- oder USMLE-Prüfungen. Diese Benchmarks halfen zwar, Wissen zu messen, prüften aber nicht, ob die Modelle wie Ärzte denken konnten. HealthBench ändert dies, indem es simuliert, was in der tatsächlichen Gesundheitsversorgung passiert.
Statt einzelner Fragen betrachtet HealthBench die gesamte Entscheidungskette – vom Lesen einer Symptomliste bis zur Empfehlung von Behandlungsschritten. Das vermittelt ein umfassenderes Bild davon, was KI leisten kann und was nicht. Beispielsweise wird getestet, ob ein Modell Diabetes über mehrere Besuche hinweg managen oder Labortrends im Laufe der Zeit verfolgen kann.
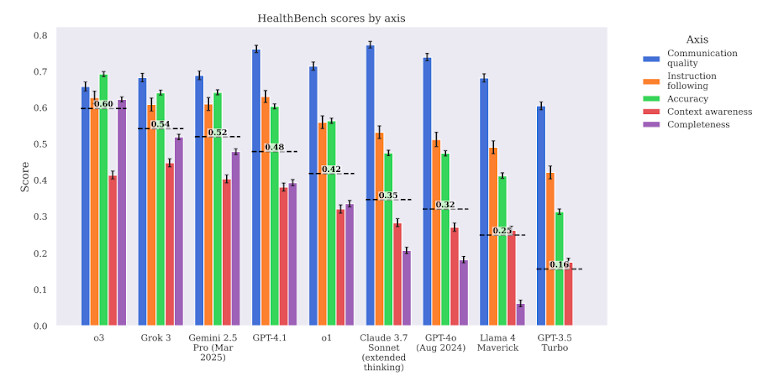
Der Benchmark bewertet Modelle nicht nur nach ihrer Genauigkeit, sondern auch nach mehreren Kriterien. Er prüft klinische Relevanz, Sicherheit und das Schadenspotenzial. Das bedeutet, dass es nicht ausreicht, eine Frage technisch richtig zu beantworten – die Antwort muss auch in realen Situationen sicher und nützlich sein.
Eine weitere Stärke von HealthBench ist die Transparenz. Das Team dahinter hat alle Eingabeaufforderungen, Bewertungskriterien und Anmerkungen veröffentlicht. So können andere Forscher neue Modelle testen, Bewertungen verbessern und auf der Arbeit aufbauen. Es ist ein offener Aufruf an die KI-Community: Wenn Sie behaupten, dass Ihr Modell im Gesundheitswesen nützlich ist, beweisen Sie es hier.
GPT-4 und Med-PaLM 2 noch nicht bereit für die Klinik
Trotz des jüngsten Hypes um GPT-4 und andere große Modelle, der Benchmark zeigt, dass sie immer noch schwere medizinische Fehler machen. Insgesamt GPT-4 Im Durchschnitt erreichte die Gruppe bei allen Aufgaben nur eine Richtigkeit von etwa 60–65 %. In wichtigen Bereichen wie Behandlungs- und Medikamentenentscheidungen lag die Punktzahl sogar noch niedriger.
Med-PaLM 2, ein auf medizinische Aufgaben optimiertes Modell, schnitt nicht viel besser ab. Es zeigte eine etwas höhere Genauigkeit beim grundlegenden medizinischen Erinnern, scheiterte jedoch beim mehrstufigen klinischen Denken. In mehreren Szenarien gab es Ratschläge, die kein zugelassener Arzt unterstützen würde. Dazu gehören die falsche Erkennung von Warnsymptomen und die Empfehlung nicht standardisierter Behandlungen.
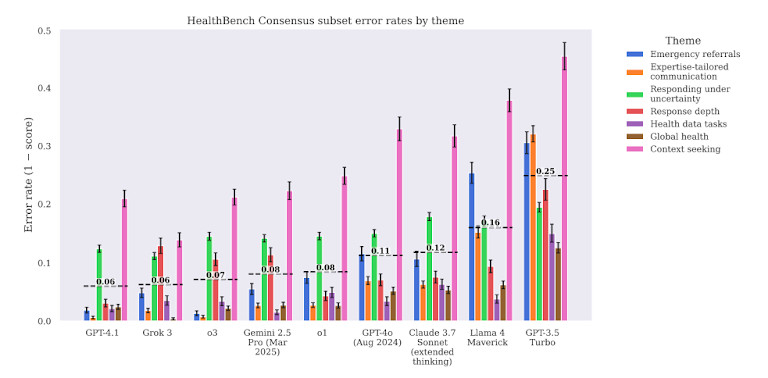
Der Bericht weist auch auf eine versteckte Gefahr hin: Selbstüberschätzung. Modelle wie GPT-4 geben oft falsche Antworten in einem selbstbewussten, flüssigen Ton. Das macht es für Nutzer – selbst geschulte Fachkräfte – schwierig, Fehler zu erkennen. Diese Diskrepanz zwischen sprachlicher Eleganz und medizinischer Präzision ist eines der Hauptrisiken beim Einsatz von KI im Gesundheitswesen ohne strenge Sicherheitsvorkehrungen.
Um es klar zu sagen: Klug zu klingen ist nicht dasselbe wie sicher zu sein.
Was sich ändern muss, bevor KI im Gesundheitswesen vertrauenswürdig ist
Die HealthBench-Ergebnisse sind nicht nur eine Warnung. Sie zeigen auch, was KI verbessern muss. Erstens müssen Modelle anhand realer klinischer Arbeitsabläufe trainiert und evaluiert werden, nicht nur anhand von Lehrbüchern oder Prüfungen. Das bedeutet, Ärzte einzubeziehen – nicht nur als Nutzer, sondern auch als Entwickler, Tester und Prüfer.
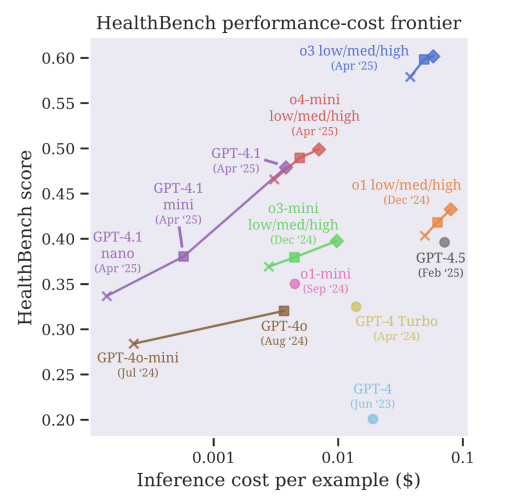
Zweitens sollten KI-Systeme so konzipiert sein, dass sie bei Unsicherheiten um Hilfe bitten. Derzeit raten Modelle oft, anstatt zu sagen: „Ich weiß es nicht.“ Das ist im Gesundheitswesen inakzeptabel. Eine falsche Antwort kann die Diagnose verzögern, das Risiko erhöhen oder das Vertrauen der Patienten zerstören. Zukünftige Systeme müssen lernen, Unsicherheiten zu kennzeichnen und komplexe Fälle an Menschen zu verweisen.
Drittens müssen Evaluationen wie HealthBench vor dem tatsächlichen Einsatz zum Standard werden. Das Bestehen eines akademischen Tests reicht nicht mehr aus. Modelle müssen beweisen, dass sie reale Entscheidungen sicher treffen können, sonst sollten sie aus dem klinischen Umfeld gänzlich herausgehalten werden.
Der Weg in die Zukunft: Verantwortungsvoller Umgang, kein Hype
HealthBench behauptet nicht, dass KI im Gesundheitswesen keine Zukunft hat. Vielmehr zeigt es, wo wir heute stehen – und wie weit die Entwicklung noch ist. Große Sprachmodelle können bei administrativen Aufgaben, der Zusammenfassung oder der Patientenkommunikation helfen. Doch derzeit sind sie noch nicht bereit, Ärzte in der klinischen Versorgung zu ersetzen oder auch nur zuverlässig zu unterstützen.
Verantwortungsvoller Einsatz bedeutet klare Grenzen. Er erfordert Transparenz bei der Bewertung, Partnerschaften mit medizinischem Fachpersonal und ständige Tests anhand realer medizinischer Anforderungen. Ohne diese Maßnahmen sind die Risiken zu hoch.
Die Entwickler von HealthBench laden die KI- und Gesundheitsbranche ein, es als neuen Standard zu übernehmen. Bei richtiger Umsetzung könnte es das Feld voranbringen – vom Hype zur echten, sicheren Wirkung.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
CandyBomb x UAI: Futures traden, um 200.000 UAI zu teilen!
Neue Spot-Margin-Handelspaare - KITE/USDT, MMT/USDT
Bitget Margin-Trading unterstützt künftig Cross-Margin-Trading und Kreditaufnahmen mit BGB.
STABLEUSDT jetzt für den Pre-Market-Futures-Trading eingeführt