
Vitalik: Klebstoff- und Coprozessor-Architektur, ein neues Konzept zur Steigerung von Effizienz und Sicherheit

Ein Kleber sollte so optimiert werden, dass er ein guter Kleber ist, und ein Coprozessor sollte so optimiert werden, dass er ein guter Coprozessor ist.
Kleber sollte darauf optimiert werden, ein guter Kleber zu sein, und Coprozessoren sollten darauf optimiert werden, gute Coprozessoren zu sein.
Originaltitel: „Glue and coprocessor architectures“
Autor: Vitalik Buterin, Gründer von Ethereum
Übersetzung: Deng Tong, Jinse Finance
Besonderer Dank gilt Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra und verschiedenen Flashbots-Mitwirkenden für ihr Feedback und ihre Kommentare.
Wenn man mit mittlerem Detailgrad irgendeine ressourcenintensive Berechnung in der modernen Welt analysiert, stößt man immer wieder auf ein Merkmal: Die Berechnung lässt sich in zwei Teile aufteilen:
- Eine relativ kleine Menge komplexer, aber nicht rechenintensiver „Business-Logik“;
- Eine große Menge intensiver, aber hochstrukturierter „teurer Arbeit“.
Diese beiden Berechnungsformen sollten am besten unterschiedlich behandelt werden: Erstere kann eine ineffizientere, aber sehr allgemeine Architektur erfordern; Letztere benötigt vielleicht eine weniger allgemeine, aber dafür sehr effiziente Architektur.
Welche Beispiele für diese unterschiedlichen Ansätze gibt es in der Praxis?
Lassen Sie uns zunächst die Umgebung betrachten, mit der ich am vertrautesten bin: die Ethereum Virtual Machine (EVM). Hier ist ein geth-Debug-Trace einer kürzlich von mir durchgeführten Ethereum-Transaktion: das Aktualisieren des IPFS-Hashes meines Blogs auf ENS. Diese Transaktion verbrauchte insgesamt 46.924 Gas und lässt sich wie folgt kategorisieren:
- Grundkosten: 21.000
- Call-Daten: 1.556
- EVM-Ausführung: 24.368
- SLOAD-Opcode: 6.400
- SSTORE-Opcode: 10.100
- LOG-Opcode: 2.149
- Sonstiges: 6.719

EVM-Trace des ENS-Hash-Updates. Die zweitletzte Spalte zeigt den Gasverbrauch.
Die Moral dieser Geschichte: Der Großteil der Ausführung (etwa 73 % nur EVM, etwa 85 %, wenn man die Grundkosten für Berechnungen einbezieht) konzentriert sich auf eine sehr kleine Anzahl strukturierter, teurer Operationen: Speicher-Lese-/Schreibzugriffe, Logs und Kryptografie (die Grundkosten beinhalten 3.000 für die Signaturprüfung, die EVM beinhaltet weitere 272 für das Hashing). Der Rest ist „Business-Logik“: das Verschieben von calldata-Bits, um die ID des zu setzenden Eintrags und den Hash zu extrahieren, usw. Bei Token-Transfers wäre dies das Addieren und Subtrahieren von Salden, bei fortgeschritteneren Anwendungen könnten es Schleifen sein usw.
In der EVM werden diese beiden Ausführungsformen unterschiedlich behandelt. Die High-Level-Business-Logik wird in einer höheren Programmiersprache wie Solidity geschrieben, die in die EVM kompiliert werden kann. Die teure Arbeit wird weiterhin durch EVM-OpCodes (wie SLOAD) ausgelöst, aber über 99 % der eigentlichen Berechnung werden in spezialisierten Modulen direkt im Client-Code (oder sogar in Bibliotheken) durchgeführt.
Um dieses Muster besser zu verstehen, betrachten wir ein weiteres Beispiel: mit torch in Python geschriebener KI-Code.
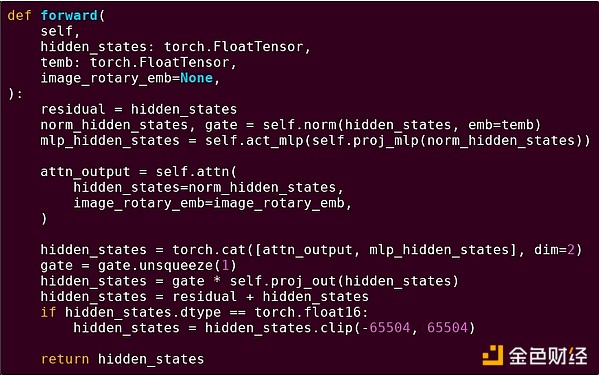
Forward-Pass eines Blocks eines Transformer-Modells
Was sehen wir hier? Wir sehen eine relativ kleine Menge an „Business-Logik“, geschrieben in Python, die die Struktur der auszuführenden Operationen beschreibt. In der Praxis gibt es noch eine weitere Art von Business-Logik, die Details wie das Einholen von Eingaben und das Verarbeiten von Ausgaben regelt. Wenn wir jedoch jede einzelne Operation (self.norm, torch.cat, +, *, die einzelnen Schritte innerhalb von self.attn usw.) betrachten, sehen wir Vektorisierung: dieselbe Operation wird parallel auf viele Werte angewendet. Wie im ersten Beispiel wird ein kleiner Teil der Berechnung für die Business-Logik verwendet, der Großteil für große, strukturierte Matrix- und Vektoroperationen – tatsächlich ist das meiste davon Matrixmultiplikation.
Wie im EVM-Beispiel werden auch hier beide Arbeitsarten unterschiedlich behandelt. Die High-Level-Business-Logik wird in Python geschrieben, einer sehr allgemeinen und flexiblen, aber auch sehr langsamen Sprache; die Ineffizienz wird akzeptiert, da sie nur einen kleinen Teil der Gesamtrechenleistung beansprucht. Die intensiven Operationen werden in hochoptimiertem Code geschrieben, meist CUDA-Code, der auf GPUs läuft. Zunehmend sehen wir auch LLM-Inferenz auf ASICs.
Moderne programmierbare Kryptografie wie SNARK folgt erneut auf zwei Ebenen einem ähnlichen Muster. Erstens kann der Prover in einer High-Level-Sprache geschrieben werden, wobei die schwere Arbeit durch vektorisierte Operationen erledigt wird, wie im obigen KI-Beispiel. Mein runder STARK-Code zeigt dies. Zweitens kann das innerhalb der Kryptografie ausgeführte Programm selbst so geschrieben werden, dass es sich in allgemeine Business-Logik und hochstrukturierte teure Arbeit aufteilt.
Um zu verstehen, wie das funktioniert, schauen wir uns einen der neuesten Trends bei STARK-Proofs an. Um allgemeingültig und einfach zu verwenden zu sein, bauen Teams zunehmend STARK-Prover für weit verbreitete Minimal-Virtual-Machines wie RISC-V. Jedes Programm, dessen Ausführung bewiesen werden soll, kann in RISC-V kompiliert werden, und der Prover kann dann die Ausführung dieses Codes in RISC-V beweisen.
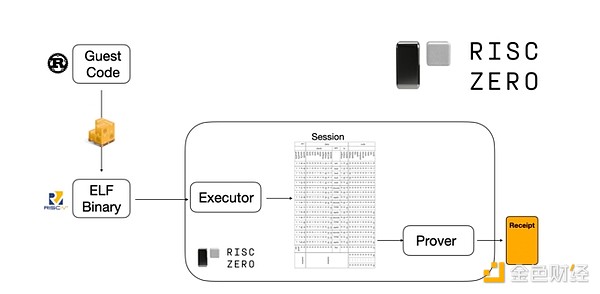
Diagramm aus der RiscZero-Dokumentation
Das ist sehr praktisch: Man muss die Beweislogik nur einmal schreiben, und von da an kann jedes zu beweisende Programm in jeder „traditionellen“ Programmiersprache geschrieben werden (z. B. unterstützt RiskZero Rust). Es gibt jedoch ein Problem: Dieser Ansatz bringt erhebliche Overheads mit sich. Programmierbare Kryptografie ist bereits sehr teuer; der Overhead, Code im RISC-V-Interpreter auszuführen, ist zu hoch. Daher haben Entwickler einen Trick gefunden: Sie identifizieren bestimmte teure Operationen, die den Großteil der Berechnung ausmachen (meist Hashing und Signaturen), und erstellen dann spezialisierte Module, um diese Operationen sehr effizient zu beweisen. Dann kombiniert man einfach das ineffiziente, aber allgemeine RISC-V-Beweissystem mit dem effizienten, aber spezialisierten Beweissystem und erhält so das Beste aus beiden Welten.
Auch außerhalb von ZK-SNARKs kann programmierbare Kryptografie, wie Multi-Party Computation (MPC) und Fully Homomorphic Encryption (FHE), mit ähnlichen Methoden optimiert werden.
Wie sieht das Phänomen insgesamt aus?
Moderne Berechnungen folgen zunehmend dem, was ich als Glue- und Coprozessor-Architektur bezeichne: Es gibt eine zentrale „Kleber“-Komponente, die sehr allgemein, aber ineffizient ist und für die Datenübertragung zwischen einem oder mehreren Coprozessor-Komponenten zuständig ist, die weniger allgemein, aber sehr effizient sind.
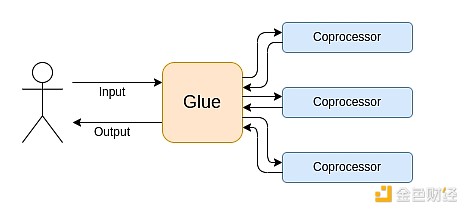
Das ist eine Vereinfachung: In der Praxis gibt es fast immer mehr als zwei Ebenen im Kompromiss zwischen Effizienz und Allgemeinheit. GPUs und andere Chips, die in der Branche üblicherweise als „Coprocessor“ bezeichnet werden, sind weniger allgemein als CPUs, aber allgemeiner als ASICs. Die Kompromisse beim Spezialisierungsgrad sind komplex und hängen davon ab, welche Teile eines Algorithmus in fünf Jahren noch gleich sind und welche sich in sechs Monaten ändern. In ZK-Proof-Architekturen sehen wir oft ähnliche mehrschichtige Spezialisierungen. Für ein breites Denkmodell reichen jedoch zwei Ebenen. In vielen Bereichen der Berechnung gibt es ähnliche Situationen:
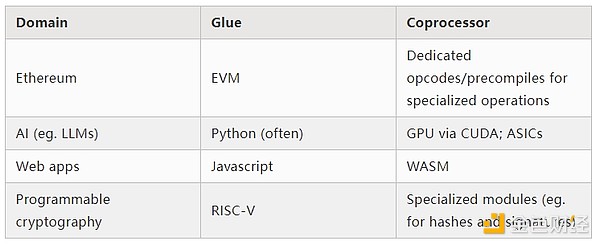
Wie die obigen Beispiele zeigen, kann Berechnung auf diese Weise aufgeteilt werden – es scheint ein Naturgesetz zu sein. Tatsächlich gibt es seit Jahrzehnten Beispiele für Spezialisierung in der Berechnung. Ich glaube jedoch, dass diese Trennung zunimmt. Dafür gibt es Gründe:
Erst kürzlich haben wir das Limit der CPU-Taktraten erreicht, sodass weitere Leistungssteigerungen nur noch durch Parallelisierung möglich sind. Parallelisierung ist jedoch schwer zu durchdenken, daher ist es für Entwickler oft praktikabler, weiterhin sequentiell zu denken und die Parallelisierung im Backend stattfinden zu lassen, gekapselt in spezialisierten Modulen für bestimmte Operationen.
Die Rechengeschwindigkeit ist erst kürzlich so hoch geworden, dass die Kosten der Business-Logik tatsächlich vernachlässigbar sind. In dieser Welt ist es sinnvoll, die VM für die Ausführung der Business-Logik auf andere Ziele als Effizienz zu optimieren: Entwicklerfreundlichkeit, Vertrautheit, Sicherheit und ähnliche Ziele. Gleichzeitig können spezialisierte „Coprocessor“-Module weiterhin auf Effizienz ausgelegt werden und ihre Sicherheit und Entwicklerfreundlichkeit aus der relativ einfachen „Schnittstelle“ mit dem Kleber ziehen.
Es wird immer klarer, welche die wichtigsten teuren Operationen sind. In der Kryptografie ist das am offensichtlichsten: Die wahrscheinlichsten teuren Operationen sind Modulo-Operationen, elliptische Kurven-Linearkombinationen (auch Multi-Scalar-Multiplikation genannt), schnelle Fourier-Transformationen usw. Auch in der KI wird das immer deutlicher: Seit über zwanzig Jahren besteht der Großteil der Berechnung aus „hauptsächlich Matrixmultiplikation“ (wenn auch mit unterschiedlichen Genauigkeitsstufen). Auch in anderen Bereichen gibt es ähnliche Trends. Im Vergleich zu vor 20 Jahren gibt es viel weniger „unbekannte Unbekannte“ in der (rechenintensiven) Berechnung.
Was bedeutet das?
Ein entscheidender Punkt ist: Kleber (Glue) sollte darauf optimiert werden, ein guter Kleber zu sein, und Coprozessoren (coprocessor) sollten darauf optimiert werden, gute Coprozessoren zu sein. Wir können die Bedeutung davon in mehreren Schlüsselbereichen untersuchen.
EVM
Blockchain-Virtual-Machines (wie die EVM) müssen nicht effizient sein, sondern nur vertraut. Mit den richtigen Coprozessoren (auch „Precompiles“ genannt) kann die Berechnung in einer ineffizienten VM tatsächlich genauso effizient sein wie in einer nativen, effizienten VM. Zum Beispiel ist der Overhead der 256-Bit-Register der EVM relativ gering, während die Vorteile der Vertrautheit und des bestehenden Entwickler-Ökosystems enorm und dauerhaft sind. Teams, die die EVM optimieren, haben sogar festgestellt, dass der Mangel an Parallelisierung meist nicht das Hauptproblem für die Skalierbarkeit ist.
Die beste Methode zur Verbesserung der EVM ist wahrscheinlich (i) das Hinzufügen besserer Precompiles oder spezialisierter OpCodes – eine Kombination aus EVM-MAX und SIMD könnte sinnvoll sein – sowie (ii) die Verbesserung des Speicherlayouts, z. B. durch die Änderungen der Verkle-Bäume, die als Nebeneffekt die Kosten für den Zugriff auf benachbarte Speicherplätze erheblich senken.
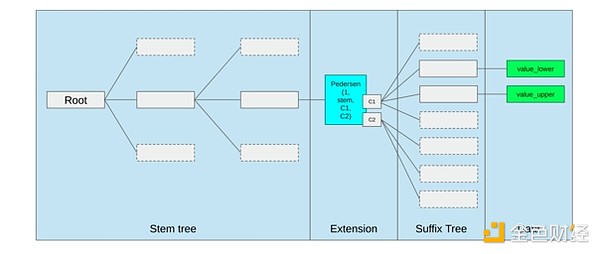
Speicheroptimierung im Ethereum Verkle Tree Proposal, bei der benachbarte Speicher-Keys zusammengelegt und die Gas-Kosten entsprechend angepasst werden. Solche Optimierungen, zusammen mit besseren Precompiles, sind wahrscheinlich wichtiger als Anpassungen an der EVM selbst.
Sichere Berechnung und offene Hardware
Eine große Herausforderung bei der Erhöhung der Sicherheit moderner Berechnungen auf Hardwareebene ist ihre zu komplexe und proprietäre Natur: Chips werden auf Effizienz optimiert, was proprietäre Optimierungen erfordert. Hintertüren lassen sich leicht verstecken, und Seitenkanal-Schwachstellen werden ständig entdeckt.
Es gibt weiterhin Bemühungen aus verschiedenen Richtungen, offenere und sicherere Alternativen zu fördern. Einige Berechnungen werden zunehmend in Trusted Execution Environments durchgeführt, auch auf dem Handy des Nutzers, was die Sicherheit erhöht hat. Die Bewegung hin zu mehr Open-Source-Consumer-Hardware geht weiter, mit jüngsten Erfolgen wie RISC-V-Laptops, die Ubuntu ausführen.
RISC-V-Laptop mit Debian
Effizienz bleibt jedoch ein Problem. Der Autor des oben verlinkten Artikels schreibt:
Neuere Open-Source-Chipdesigns wie RISC-V können nicht mit Prozessor-Technologien konkurrieren, die seit Jahrzehnten verbessert werden. Jeder Fortschritt hat einen Anfang.
Noch paranoidere Ansätze, wie dieses Design eines RISC-V-Computers auf einem FPGA, bringen noch mehr Overhead mit sich. Aber was wäre, wenn die Glue- und Coprozessor-Architektur bedeuten würde, dass dieser Overhead tatsächlich keine Rolle spielt? Was wäre, wenn wir akzeptieren, dass offene und sichere Chips langsamer sind als proprietäre, und im Zweifel sogar auf gängige Optimierungen wie Speculative Execution und Branch Prediction verzichten, aber versuchen, dies durch (wenn nötig proprietäre) ASIC-Module für die rechenintensivsten, spezifischen Berechnungen auszugleichen? Sensible Berechnungen könnten auf dem „Hauptchip“ erfolgen, der auf Sicherheit, Open-Source-Design und Seitenkanalresistenz optimiert ist. Die intensiveren Berechnungen (z. B. ZK-Proofs, KI) würden auf ASIC-Modulen durchgeführt, die weniger über die ausgeführten Berechnungen wissen (möglicherweise, durch kryptografische Blindierung, in manchen Fällen sogar gar nichts).
Kryptografie
Ein weiterer wichtiger Punkt ist, dass all dies für die Kryptografie, insbesondere für die Mainstream-Adoption programmierbarer Kryptografie, sehr optimistisch ist. Wir haben bereits einige hochoptimierte Implementierungen bestimmter, hochstrukturierter Berechnungen in SNARKs, MPC und anderen Settings gesehen: Der Overhead bestimmter Hashfunktionen ist nur ein paar Hundert Mal teurer als die direkte Berechnung, und auch der Overhead für KI (hauptsächlich Matrixmultiplikation) ist sehr gering. Weitere Verbesserungen wie GKR könnten dies noch weiter senken. Vollständig generische VM-Ausführung, insbesondere in einem RISC-V-Interpreter, wird wahrscheinlich weiterhin einen Overhead von etwa Zehntausendfach verursachen, aber aus den in diesem Artikel beschriebenen Gründen ist das nicht entscheidend: Solange die rechenintensivsten Teile mit effizienten, spezialisierten Techniken behandelt werden, bleibt der Gesamt-Overhead kontrollierbar.
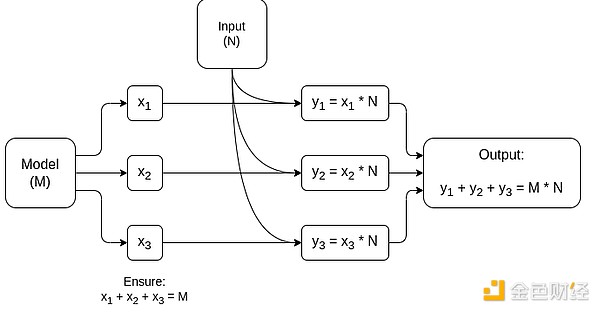
Vereinfachtes Diagramm eines MPC für Matrixmultiplikation, der größten Komponente bei der Inferenz von KI-Modellen. Siehe diesen Artikel für weitere Details, einschließlich wie die Privatsphäre von Modell und Eingaben gewahrt bleibt.
Eine Ausnahme von der Idee „Die Glue-Schicht muss nur vertraut, nicht effizient sein“ ist die Latenz und in geringerem Maße die Datenbandbreite. Wenn eine Berechnung viele Male schwere Operationen auf denselben Daten ausführt (wie in Kryptografie und KI), kann jede durch eine ineffiziente Glue-Schicht verursachte Latenz zum Hauptengpass der Laufzeit werden. Daher gibt es auch Effizienzerfordernisse an die Glue-Schicht, wenn auch spezifischere.
Fazit
Insgesamt halte ich die oben beschriebenen Trends aus mehreren Blickwinkeln für sehr positive Entwicklungen. Erstens ist dies eine vernünftige Methode, um die Recheneffizienz zu maximieren und gleichzeitig die Entwicklerfreundlichkeit zu erhalten – mehr von beidem ist für alle von Vorteil. Insbesondere durch die Spezialisierung auf der Client-Seite zur Effizienzsteigerung wird es möglich, sensible und leistungsintensive Berechnungen (z. B. ZK-Proofs, LLM-Inferenz) lokal auf Nutzerhardware auszuführen. Zweitens eröffnet sich ein großes Zeitfenster, um sicherzustellen, dass das Streben nach Effizienz nicht andere Werte beeinträchtigt, insbesondere Sicherheit, Offenheit und Einfachheit: Seitenkanalsicherheit und Offenheit in Computerhardware, geringere Komplexität in ZK-SNARK-Schaltkreisen und geringere Komplexität in Virtual Machines. Historisch gesehen hat das Streben nach Effizienz diese anderen Faktoren oft in den Hintergrund gedrängt. Mit der Glue- und Coprozessor-Architektur ist das nicht mehr nötig. Ein Teil der Maschine wird auf Effizienz optimiert, der andere auf Allgemeinheit und andere Werte – beide arbeiten zusammen.
Dieser Trend ist auch sehr vorteilhaft für die Kryptografie, da sie selbst ein Hauptbeispiel für „teure, strukturierte Berechnung“ ist, und dieser Trend beschleunigt ihre Entwicklung. Das bietet eine weitere Chance, die Sicherheit zu erhöhen. Im Blockchain-Bereich wird auch mehr Sicherheit möglich: Wir können uns weniger um die Optimierung der Virtual Machine sorgen und mehr auf die Optimierung von Precompiles und anderen Funktionen konzentrieren, die mit der VM koexistieren.
Drittens eröffnet dieser Trend kleineren und neueren Akteuren die Möglichkeit zur Teilnahme. Wenn Berechnung weniger monolithisch und modularer wird, sinkt die Eintrittsschwelle erheblich. Selbst mit einem ASIC für eine Art von Berechnung kann man etwas bewirken. Das gilt auch für den ZK-Proof-Bereich und die EVM-Optimierung. Es wird einfacher und zugänglicher, Code mit nahezu modernster Effizienz zu schreiben. Die Prüfung und formale Verifikation solcher Codes wird ebenfalls einfacher und zugänglicher. Schließlich, da diese sehr unterschiedlichen Bereiche der Berechnung auf einige gemeinsame Muster konvergieren, gibt es mehr Raum für Zusammenarbeit und gegenseitiges Lernen.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
Von „Wer gibt wem Geld“ zu „Nur den Richtigen geben“: Die nächste Generation von Launchpads muss neu gemischt werden
Die nächste Generation von Launchpads könnte dazu beitragen, das Problem des Community-Starts im Kryptowährungsbereich zu lösen, ein Problem, das durch Airdrops bisher nicht behoben werden konnte.

Balancer plant, 8 Millionen US-Dollar aus den wiedererlangten Mitteln des 128-Millionen-Dollar-Exploits zu verteilen.
Balancer hat einen Plan vorgeschlagen, etwa 8 Millionen Dollar an geretteten Vermögenswerten zu verteilen, nachdem bei einem größeren Exploit Anfang dieses Monats über 128 Millionen Dollar aus seinen Tresoren abgezogen wurden. Es wurde darauf hingewiesen, dass sechs White-Hat-Akteure während des Angriffs rund 3,86 Millionen Dollar wiederhergestellt haben.

Do Kwon beantragt eine Höchststrafe von 5 Jahren Gefängnis im $40 Milliarden Terra-Betrugsfall
Quick Take Terraform Labs Gründer Do Kwon und seine Anwälte haben ein US-Gericht gebeten, seine Haftstrafe auf maximal fünf Jahre zu begrenzen. Die Urteilsverkündung für Kwon ist für den 11. Dezember angesetzt.
