
Vitalik: Arsitektur Glue dan Coprocessor, Konsep Baru untuk Meningkatkan Efisiensi dan Keamanan

Penggabung harus dioptimalkan agar menjadi penggabung yang baik, sedangkan koprosesor juga harus dioptimalkan agar menjadi koprosesor yang baik.
Glue harus dioptimalkan untuk menjadi glue yang baik, dan coprocessor juga harus dioptimalkan untuk menjadi coprocessor yang baik.
Judul Asli: "Glue and coprocessor architectures"
Penulis: Vitalik Buterin, Pendiri Ethereum
Penerjemah: Deng Tong, Jinse Finance
Terima kasih khusus kepada Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra, dan berbagai kontributor Flashbots atas masukan dan komentarnya.
Jika Anda menganalisis secara detail tingkat menengah pada komputasi intensif sumber daya apa pun di dunia modern, Anda akan berulang kali menemukan satu karakteristik: komputasi dapat dibagi menjadi dua bagian:
- Sejumlah kecil "logika bisnis" yang kompleks namun tidak berat secara komputasi;
- Banyak "pekerjaan mahal" yang intensif namun sangat terstruktur.
Kedua bentuk komputasi ini paling baik ditangani dengan cara yang berbeda: yang pertama, arsitekturnya mungkin kurang efisien namun membutuhkan tingkat generalitas yang sangat tinggi; yang kedua, arsitekturnya mungkin kurang generalis, namun membutuhkan efisiensi yang sangat tinggi.
Apa saja contoh pendekatan berbeda ini dalam praktik?
Pertama, mari kita lihat lingkungan yang paling saya kenal: Ethereum Virtual Machine (EVM). Ini adalah geth debug trace dari transaksi Ethereum yang baru-baru ini saya lakukan: memperbarui hash IPFS blog saya di ENS. Transaksi ini menghabiskan total 46924 gas, yang dapat dikategorikan sebagai berikut:
- Biaya dasar: 21,000
- Data panggilan: 1,556
- Eksekusi EVM: 24,368
- Opcode SLOAD: 6,400
- Opcode SSTORE: 10,100
- Opcode LOG: 2,149
- Lainnya: 6,719

Trace EVM untuk pembaruan hash ENS. Kolom kedua dari belakang adalah konsumsi gas.
Moral dari cerita ini adalah: sebagian besar eksekusi (sekitar 73% jika hanya melihat EVM, sekitar 85% jika termasuk bagian biaya dasar yang mencakup komputasi) terkonsentrasi pada sedikit operasi mahal yang terstruktur: baca/tulis storage, log, dan kriptografi (biaya dasar termasuk 3000 untuk verifikasi tanda tangan, EVM juga termasuk 272 untuk pembayaran hash). Sisanya adalah "logika bisnis": menukar bit calldata untuk mengekstrak ID record yang saya coba atur dan hash yang saya atur, dan sebagainya. Dalam transfer token, ini akan mencakup penambahan dan pengurangan saldo, dalam aplikasi yang lebih canggih, ini mungkin termasuk loop, dan lain-lain.
Di EVM, kedua bentuk eksekusi ini ditangani secara berbeda. Logika bisnis tingkat tinggi ditulis dalam bahasa tingkat tinggi, biasanya Solidity, yang dapat dikompilasi ke EVM. Pekerjaan mahal tetap dipicu oleh opcode EVM (seperti SLOAD), tetapi lebih dari 99% komputasi aktual dilakukan dalam modul khusus yang ditulis langsung di dalam kode klien (bahkan di dalam library).
Untuk memperkuat pemahaman tentang pola ini, mari kita jelajahi dalam konteks lain: kode AI yang ditulis dengan python menggunakan torch.
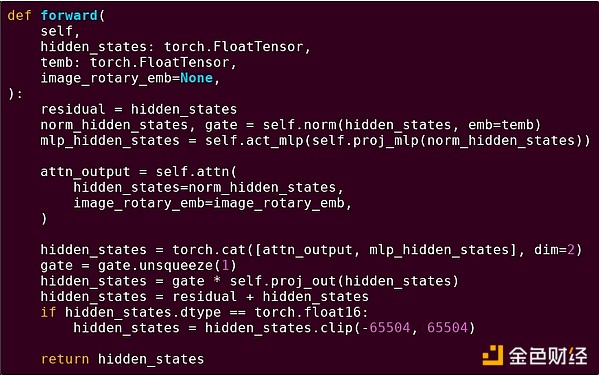
Forward pass dari satu blok model transformer
Apa yang kita lihat di sini? Kita melihat sejumlah kecil "logika bisnis" yang ditulis dalam Python, yang mendeskripsikan struktur operasi yang sedang dijalankan. Dalam aplikasi nyata, akan ada jenis logika bisnis lain yang menentukan detail seperti bagaimana mendapatkan input dan apa yang dilakukan pada output. Namun, jika kita menelusuri setiap operasi secara mendalam (self.norm, torch.cat, +, *, langkah-langkah di dalam self.attn...), kita melihat komputasi vektorisasi: operasi yang sama dihitung secara paralel pada banyak nilai. Seperti pada contoh pertama, sebagian kecil komputasi digunakan untuk logika bisnis, sebagian besar digunakan untuk operasi matriks dan vektor besar yang terstruktur — pada kenyataannya, sebagian besar hanyalah perkalian matriks.
Sama seperti pada contoh EVM, kedua jenis pekerjaan ini ditangani dengan dua cara berbeda. Kode logika bisnis tingkat tinggi ditulis dalam Python, bahasa yang sangat generalis dan fleksibel, tetapi juga sangat lambat; kita menerima inefisiensi ini karena hanya melibatkan sebagian kecil dari total biaya komputasi. Sementara itu, operasi intensif ditulis dalam kode yang sangat dioptimalkan, biasanya kode CUDA yang berjalan di GPU. Bahkan, kita semakin sering melihat inferensi LLM dilakukan di ASIC.
Kriptografi modern yang dapat diprogram, seperti SNARK, sekali lagi mengikuti pola serupa pada dua tingkat. Pertama, prover dapat ditulis dalam bahasa tingkat tinggi, di mana pekerjaan berat dilakukan melalui operasi vektorisasi, seperti pada contoh AI di atas. Kode STARK bulat saya di sini menunjukkan hal ini. Kedua, program yang dijalankan di dalam kriptografi itu sendiri dapat ditulis dengan cara yang membagi antara logika bisnis generalis dan pekerjaan mahal yang sangat terstruktur.
Untuk memahami cara kerjanya, kita dapat melihat salah satu tren terbaru dalam pembuktian STARK. Untuk generalitas dan kemudahan penggunaan, tim semakin banyak membangun prover STARK untuk mesin virtual minimal yang banyak diadopsi (seperti RISC-V). Program apa pun yang perlu dibuktikan eksekusinya dapat dikompilasi ke RISC-V, lalu prover dapat membuktikan eksekusi kode RISC-V tersebut.
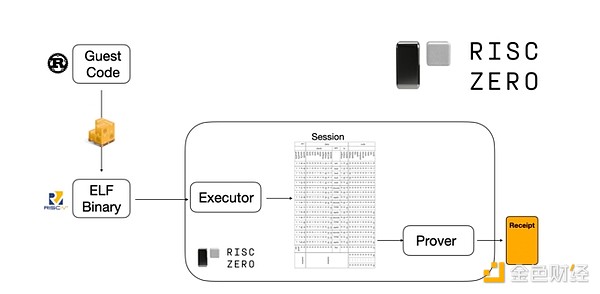
Diagram dari dokumentasi RiscZero
Ini sangat nyaman: artinya kita hanya perlu menulis logika pembuktian sekali, dan setelah itu, program apa pun yang perlu dibuktikan dapat ditulis dalam bahasa pemrograman "tradisional" apa pun (misalnya RiskZero mendukung Rust). Namun, ada masalah: pendekatan ini menghasilkan overhead yang besar. Kriptografi yang dapat diprogram sudah sangat mahal; menambah overhead menjalankan kode dalam interpreter RISC-V terlalu banyak. Jadi, pengembang menemukan trik: mengidentifikasi operasi mahal tertentu yang membentuk sebagian besar komputasi (biasanya hash dan tanda tangan), lalu membuat modul khusus untuk membuktikan operasi ini secara sangat efisien. Kemudian, Anda cukup menggabungkan sistem pembuktian RISC-V yang generalis namun tidak efisien dengan sistem pembuktian khusus yang efisien, dan Anda mendapatkan yang terbaik dari kedua dunia.
Kriptografi yang dapat diprogram selain ZK-SNARK, seperti multiparty computation (MPC) dan fully homomorphic encryption (FHE), mungkin juga dioptimalkan dengan pendekatan serupa.
Secara umum, bagaimana fenomena ini?
Komputasi modern semakin mengikuti apa yang saya sebut arsitektur glue dan coprocessor: Anda memiliki beberapa komponen "glue" pusat, yang sangat generalis namun tidak efisien, bertanggung jawab untuk mengirimkan data di antara satu atau lebih komponen coprocessor, yang kurang generalis namun sangat efisien.
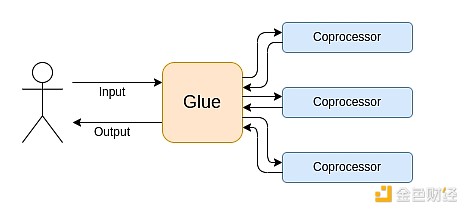
Ini adalah penyederhanaan: dalam praktiknya, kurva trade-off antara efisiensi dan generalitas hampir selalu memiliki lebih dari dua tingkat. GPU dan chip lain yang biasanya disebut "coprocessor" di industri tidak seumum CPU, tetapi lebih umum daripada ASIC. Trade-off tingkat spesialisasi sangat kompleks, tergantung pada prediksi dan intuisi tentang bagian mana dari algoritma yang akan tetap sama dalam lima tahun, dan bagian mana yang akan berubah dalam enam bulan. Dalam arsitektur pembuktian ZK, kita sering melihat spesialisasi multi-level serupa. Namun, untuk model berpikir yang luas, mempertimbangkan dua tingkat sudah cukup. Di banyak bidang komputasi, situasinya serupa:
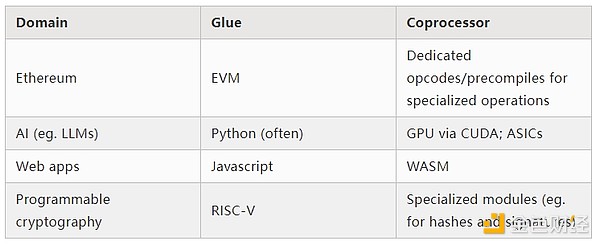
Dari contoh di atas, jelas bahwa komputasi dapat dibagi dengan cara ini, dan tampaknya ini adalah hukum alam. Faktanya, Anda dapat menemukan contoh spesialisasi komputasi selama beberapa dekade. Namun, saya percaya pemisahan ini sedang meningkat. Saya pikir ada alasannya:
Kita baru-baru ini mencapai batas peningkatan kecepatan clock CPU, sehingga hanya dengan paralelisasi kita dapat memperoleh keuntungan lebih lanjut. Namun, paralelisasi sulit untuk dipikirkan, sehingga bagi pengembang, lebih praktis untuk tetap berpikir secara berurutan dan membiarkan paralelisasi terjadi di backend, dibungkus dalam modul khusus yang dibangun untuk operasi tertentu.
Kecepatan komputasi baru-baru ini menjadi sangat cepat sehingga biaya komputasi logika bisnis benar-benar dapat diabaikan. Dalam dunia ini, mengoptimalkan VM yang menjalankan logika bisnis untuk tujuan selain efisiensi komputasi juga masuk akal: ramah pengembang, familiaritas, keamanan, dan tujuan serupa lainnya. Sementara itu, modul "coprocessor" khusus dapat terus dirancang untuk efisiensi, dan mendapatkan keamanan serta ramah pengembang dari "antarmuka" mereka yang relatif sederhana dengan glue.
Operasi mahal terpenting menjadi semakin jelas. Ini paling jelas dalam kriptografi, di mana jenis operasi mahal tertentu yang kemungkinan besar akan digunakan: operasi modulus, kombinasi linier kurva eliptik (alias multiplikasi multi-skalar), transformasi Fourier cepat, dan sebagainya. Dalam AI, situasinya juga semakin jelas, selama lebih dari dua dekade, sebagian besar komputasi adalah "terutama perkalian matriks" (meskipun tingkat presisinya berbeda). Bidang lain juga menunjukkan tren serupa. Dibandingkan 20 tahun lalu, ada jauh lebih sedikit unknown unknowns dalam komputasi (intensif).
Apa artinya ini?
Satu poin kunci adalah, glue harus dioptimalkan untuk menjadi glue yang baik, dan coprocessor juga harus dioptimalkan untuk menjadi coprocessor yang baik. Kita dapat mengeksplorasi implikasi ini di beberapa bidang utama.
EVM
Blockchain virtual machine (seperti EVM) tidak perlu efisien, hanya perlu familiar. Cukup tambahkan coprocessor yang tepat (alias "precompile"), komputasi dalam VM yang tidak efisien sebenarnya bisa seefisien komputasi dalam VM native yang efisien. Misalnya, overhead dari register 256-bit EVM relatif kecil, sementara manfaat dari familiaritas EVM dan ekosistem pengembang yang ada sangat besar dan bertahan lama. Tim pengembang yang mengoptimalkan EVM bahkan menemukan bahwa kurangnya paralelisasi biasanya bukan hambatan utama skalabilitas.
Cara terbaik untuk meningkatkan EVM mungkin hanya (i) menambahkan precompile atau opcode khusus yang lebih baik, misalnya kombinasi tertentu dari EVM-MAX dan SIMD mungkin masuk akal, serta (ii) meningkatkan tata letak storage, misalnya, perubahan Verkle tree secara tidak langsung sangat mengurangi biaya mengakses slot storage yang berdekatan.
Optimasi storage dalam proposal Verkle tree Ethereum, menempatkan storage key yang berdekatan bersama dan menyesuaikan biaya gas untuk mencerminkan hal ini. Optimasi seperti ini, ditambah precompile yang lebih baik, mungkin lebih penting daripada mengubah EVM itu sendiri.
Komputasi Aman dan Perangkat Keras Terbuka
Salah satu tantangan besar dalam meningkatkan keamanan komputasi modern di tingkat perangkat keras adalah sifatnya yang terlalu kompleks dan proprietary: desain chip dibuat untuk efisiensi, yang membutuhkan optimasi proprietary. Backdoor mudah disembunyikan, dan kerentanan side-channel terus ditemukan.
Orang-orang terus berupaya dari berbagai sudut untuk mendorong alternatif yang lebih terbuka dan aman. Beberapa komputasi semakin banyak dilakukan di lingkungan eksekusi tepercaya, termasuk di ponsel pengguna, yang telah meningkatkan keamanan pengguna. Upaya untuk mendorong perangkat keras konsumen yang lebih open source terus berlanjut, dengan beberapa kemenangan baru-baru ini seperti laptop RISC-V yang menjalankan Ubuntu.
Laptop RISC-V yang menjalankan Debian
Namun, efisiensi tetap menjadi masalah. Penulis artikel yang ditautkan di atas menulis:
Desain chip open source yang lebih baru seperti RISC-V tidak mungkin menandingi teknologi prosesor yang telah ada dan disempurnakan selama puluhan tahun. Kemajuan selalu memiliki titik awal.
Ide yang lebih paranoid, seperti desain komputer RISC-V di FPGA ini, menghadapi overhead yang lebih besar. Namun, bagaimana jika arsitektur glue dan coprocessor berarti overhead ini sebenarnya tidak penting? Bagaimana jika kita menerima bahwa chip open dan aman akan lebih lambat daripada chip proprietary, bahkan jika perlu mengorbankan optimasi umum seperti speculative execution dan branch prediction, tetapi mencoba mengkompensasi dengan menambahkan modul ASIC (proprietary jika perlu) untuk jenis komputasi tertentu yang paling intensif? Komputasi sensitif dapat dilakukan di "chip utama" yang dioptimalkan untuk keamanan, desain open source, dan resistensi side-channel. Komputasi yang lebih intensif (seperti ZK proof, AI) dilakukan di modul ASIC, yang mengetahui lebih sedikit tentang komputasi yang sedang dijalankan (mungkin, melalui blinding kriptografi, dalam beberapa kasus bahkan nol pengetahuan).
Kriptografi
Poin kunci lainnya adalah, semua ini sangat optimis untuk kriptografi, terutama kriptografi yang dapat diprogram menjadi arus utama. Kita telah melihat beberapa implementasi super-optimasi untuk komputasi terstruktur tertentu dalam SNARK, MPC, dan pengaturan lainnya: overhead beberapa fungsi hash hanya beberapa ratus kali lebih mahal daripada menjalankan komputasi secara langsung, dan overhead AI (terutama perkalian matriks) juga sangat rendah. Peningkatan lebih lanjut seperti GKR dapat menurunkan level ini lebih jauh. Eksekusi VM yang benar-benar generalis, terutama saat dijalankan dalam interpreter RISC-V, mungkin akan tetap memiliki overhead sekitar sepuluh ribu kali, tetapi karena alasan yang dijelaskan dalam artikel ini, itu tidak masalah: selama bagian paling intensif dari komputasi ditangani secara terpisah dengan teknologi khusus yang efisien, total overhead tetap dapat dikendalikan.
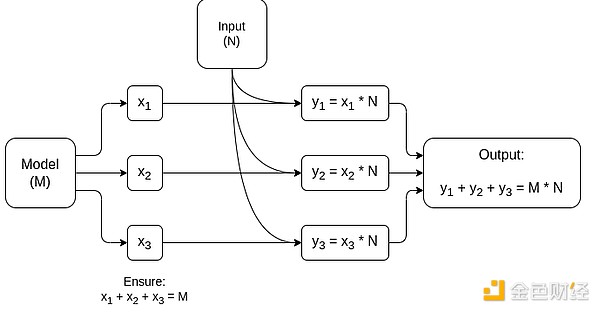
Diagram sederhana MPC khusus perkalian matriks, komponen terbesar dalam inferensi model AI. Lihat artikel ini untuk detail lebih lanjut, termasuk cara menjaga privasi model dan input.
Satu pengecualian untuk ide "lapisan glue hanya perlu familiar, tidak perlu efisien" adalah latensi, dan pada tingkat lebih kecil, bandwidth data. Jika komputasi melibatkan operasi berat berulang puluhan kali pada data yang sama (seperti dalam kriptografi dan AI), maka latensi apa pun yang disebabkan oleh lapisan glue yang tidak efisien dapat menjadi hambatan utama waktu eksekusi. Oleh karena itu, lapisan glue juga memiliki persyaratan efisiensi, meskipun lebih spesifik.
Kesimpulan
Secara keseluruhan, saya percaya tren di atas adalah perkembangan yang sangat positif dari berbagai sudut pandang. Pertama, ini adalah cara yang masuk akal untuk memaksimalkan efisiensi komputasi sambil mempertahankan keramahan pengembang, memungkinkan kita mendapatkan lebih banyak dari keduanya yang bermanfaat bagi semua orang. Secara khusus, dengan mengkhususkan di sisi klien untuk efisiensi, ini meningkatkan kemampuan kita untuk menjalankan komputasi sensitif dan berkinerja tinggi secara lokal di perangkat keras pengguna (misalnya ZK proof, inferensi LLM). Kedua, ini menciptakan peluang besar untuk memastikan bahwa pengejaran efisiensi tidak mengorbankan nilai lain, yang paling jelas adalah keamanan, keterbukaan, dan kesederhanaan: keamanan dan keterbukaan side-channel dalam perangkat keras komputer, mengurangi kompleksitas sirkuit dalam ZK-SNARK, dan mengurangi kompleksitas dalam virtual machine. Secara historis, pengejaran efisiensi membuat faktor-faktor lain ini menjadi prioritas kedua. Dengan arsitektur glue dan coprocessor, itu tidak lagi diperlukan. Bagian mesin dioptimalkan untuk efisiensi, bagian lain dioptimalkan untuk generalitas dan nilai lain, keduanya bekerja sama.
Tren ini juga sangat menguntungkan bagi kriptografi, karena kriptografi sendiri adalah contoh utama dari "komputasi terstruktur yang mahal", dan tren ini mempercepat perkembangannya. Ini menambah peluang lain untuk meningkatkan keamanan. Dalam dunia blockchain, peningkatan keamanan juga menjadi mungkin: kita bisa lebih sedikit khawatir tentang optimasi virtual machine, dan lebih fokus pada optimasi precompile dan fitur lain yang hidup berdampingan dengan virtual machine.
Ketiga, tren ini memberikan peluang bagi peserta yang lebih kecil dan lebih baru untuk berpartisipasi. Jika komputasi menjadi kurang monolitik dan lebih modular, ini sangat menurunkan hambatan masuk. Bahkan ASIC untuk satu jenis komputasi pun dapat membuat perbedaan. Hal yang sama berlaku di bidang ZK proof dan optimasi EVM. Menulis kode dengan efisiensi hampir setara dengan tingkat terdepan menjadi lebih mudah dan lebih dapat diakses. Audit dan verifikasi formal kode semacam itu juga menjadi lebih mudah dan lebih dapat diakses. Akhirnya, karena bidang komputasi yang sangat berbeda ini semakin konvergen pada beberapa pola umum, ada lebih banyak ruang untuk kolaborasi dan pembelajaran di antara mereka.
Disclaimer: Konten pada artikel ini hanya merefleksikan opini penulis dan tidak mewakili platform ini dengan kapasitas apa pun. Artikel ini tidak dimaksudkan sebagai referensi untuk membuat keputusan investasi.
Kamu mungkin juga menyukai
Lebih dari $756 juta dalam 11 hari: XRP ETF Pecahkan Rekor

Shiba Inu: Peningkatan Privasi Shibarium Ditargetkan pada 2026

Prediksi Harga Hyperliquid 2025-2030: Akankah Token HYPE Memecahkan Rekor ATH-nya?
Keputusan Kritis: Potensi Penghapusan Strategy dari Indeks MSCI Picu Kekhawatiran Arus Keluar $8,8 Miliar