
Vitalik: Architettura di colla e coprocessore, una nuova idea per migliorare efficienza e sicurezza

L'aggregatore dovrebbe essere ottimizzato per diventare un buon aggregatore, mentre il coprocessore dovrebbe essere ottimizzato per diventare un buon coprocessore.
Il collante dovrebbe essere ottimizzato per essere un buon collante, mentre il coprocessore dovrebbe essere ottimizzato per essere un buon coprocessore.
Titolo originale: "Glue and coprocessor architectures"
Autore: Vitalik Buterin, fondatore di Ethereum
Traduzione: Deng Tong, Jinse Finance
Un ringraziamento speciale a Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra e ai vari collaboratori di Flashbots per i feedback e i commenti forniti.
Se analizzi con un livello medio di dettaglio qualsiasi calcolo intensivo di risorse nel mondo moderno, scoprirai ripetutamente una caratteristica: il calcolo può essere suddiviso in due parti:
- Una quantità relativamente piccola di "logica di business" complessa ma non intensiva dal punto di vista computazionale;
- Un grande volume di "lavoro costoso" intensivo ma altamente strutturato.
Queste due forme di calcolo sono meglio gestite in modi diversi: la prima può avere un'architettura meno efficiente ma deve essere altamente generica; la seconda può avere un'architettura meno generica ma deve essere estremamente efficiente.
Quali sono gli esempi pratici di questi approcci diversi?
Per cominciare, diamo un'occhiata all'ambiente che conosco meglio: la Ethereum Virtual Machine (EVM). Questo è il debug trace geth di una mia recente transazione su Ethereum: l'aggiornamento dell'hash IPFS del mio blog su ENS. La transazione ha consumato in totale 46924 gas, classificabili come segue:
- Costo base: 21.000
- Dati di chiamata: 1.556
- Esecuzione EVM: 24.368
- Opcode SLOAD: 6.400
- Opcode SSTORE: 10.100
- Opcode LOG: 2.149
- Altro: 6.719

Trace EVM dell'aggiornamento dell'hash ENS. La penultima colonna mostra il consumo di gas.
La morale di questa storia è: la maggior parte dell'esecuzione (circa il 73% se si considera solo l'EVM, circa l'85% se si includono i costi base che coprono il calcolo) si concentra in pochissime operazioni costose e strutturate: lettura e scrittura in memoria, log e crittografia (il costo base include 3000 per la verifica della firma, l'EVM include anche 272 per l'hash). Il resto dell'esecuzione è "logica di business": spostare i bit di calldata per estrarre l'ID del record che sto cercando di impostare e l'hash che sto impostando, ecc. In un trasferimento di token, questo includerebbe l'aggiunta e la sottrazione dei saldi, in applicazioni più avanzate potrebbe includere cicli, ecc.
Nell'EVM, queste due forme di esecuzione sono gestite in modo diverso. La logica di business di alto livello è scritta in linguaggi di alto livello, solitamente Solidity, che viene compilato in EVM. Il lavoro costoso è ancora attivato dagli opcode EVM (come SLOAD), ma oltre il 99% del calcolo effettivo avviene all'interno di moduli specializzati scritti direttamente nel codice client (o persino in librerie).
Per rafforzare la comprensione di questo modello, esploriamolo in un altro contesto: codice AI scritto in python usando torch.
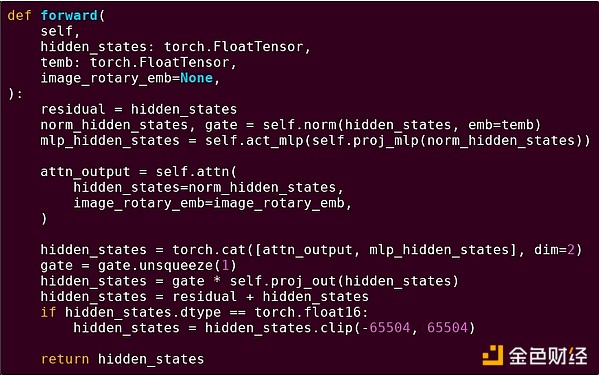
Forward pass di un blocco di un modello Transformer
Cosa vediamo qui? Vediamo una quantità relativamente piccola di "logica di business" scritta in Python, che descrive la struttura delle operazioni eseguite. Nelle applicazioni reali, ci sarebbe anche un altro tipo di logica di business che decide dettagli come come ottenere l'input e cosa fare con l'output. Ma se esaminiamo ogni singola operazione (self.norm, torch.cat, +, *, i vari passaggi interni di self.attn...), vediamo calcoli vettorializzati: la stessa operazione viene eseguita in parallelo su molti valori. Come nel primo esempio, una piccola parte del calcolo è logica di business, la maggior parte è esecuzione di grandi operazioni strutturate su matrici e vettori — infatti, la maggior parte è solo moltiplicazione di matrici.
Proprio come nell'esempio EVM, questi due tipi di lavoro sono gestiti in due modi diversi. Il codice di logica di business di alto livello è scritto in Python, un linguaggio altamente generico e flessibile ma molto lento; accettiamo l'inefficienza perché riguarda solo una piccola parte del costo computazionale totale. Nel frattempo, le operazioni intensive sono scritte in codice altamente ottimizzato, spesso codice CUDA che gira su GPU. Stiamo persino iniziando a vedere sempre più spesso l'inferenza LLM eseguita su ASIC.
La crittografia programmabile moderna, come SNARK, segue nuovamente un modello simile su due livelli. Innanzitutto, il prover può essere scritto in un linguaggio di alto livello, dove il lavoro pesante viene svolto tramite operazioni vettorializzate, proprio come nell'esempio AI sopra. Il mio codice STARK circolare qui lo mostra. In secondo luogo, il programma stesso eseguito all'interno della crittografia può essere scritto in modo da suddividere tra logica di business generica e lavoro costoso altamente strutturato.
Per capire come funziona, possiamo guardare a una delle ultime tendenze nelle prove STARK. Per essere generici e facili da usare, i team stanno sempre più costruendo prover STARK per le macchine virtuali minime più adottate (come RISC-V). Qualsiasi programma che necessita di una prova di esecuzione può essere compilato in RISC-V, quindi il prover può dimostrare l'esecuzione di quel codice in RISC-V.
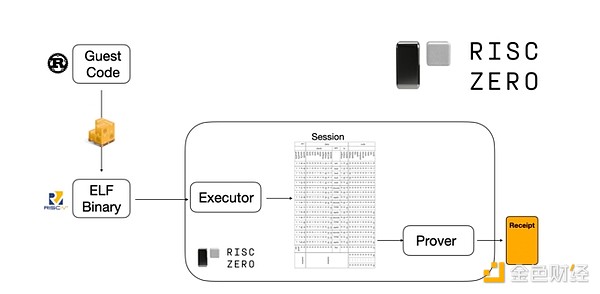
Diagramma dalla documentazione di RiscZero
Questo è molto conveniente: significa che dobbiamo scrivere la logica di prova solo una volta, e da quel momento in poi qualsiasi programma che necessita di una prova può essere scritto in qualsiasi linguaggio di programmazione "tradizionale" (ad esempio RiskZero supporta Rust). Tuttavia, c'è un problema: questo approccio comporta un grande overhead. La crittografia programmabile è già molto costosa; aggiungere l'overhead di eseguire il codice in un interprete RISC-V è troppo. Così, gli sviluppatori hanno escogitato un trucco: identificare le operazioni costose specifiche che costituiscono la maggior parte del calcolo (di solito hash e firme), quindi creare moduli specializzati per provare queste operazioni in modo molto efficiente. Quindi, combinando il sistema di prova RISC-V inefficiente ma generico con sistemi di prova efficienti ma specializzati, si ottiene il meglio di entrambi i mondi.
La crittografia programmabile oltre ZK-SNARK, come il calcolo multi-party (MPC) e la crittografia completamente omomorfica (FHE), può essere ottimizzata in modo simile.
In generale, qual è il fenomeno?
Il calcolo moderno segue sempre più quello che chiamo l'architettura collante e coprocessore: hai alcuni componenti centrali "collante", altamente generici ma inefficienti, che si occupano di trasmettere dati tra uno o più componenti coprocessore, che sono poco generici ma molto efficienti.
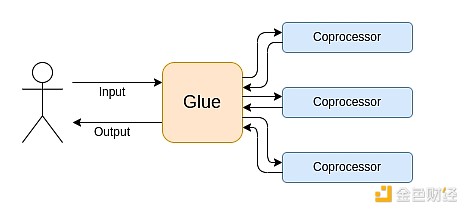
Questa è una semplificazione: nella pratica, la curva di compromesso tra efficienza e generalità ha quasi sempre più di due livelli. Le GPU e altri chip comunemente chiamati "coprocessori" nell'industria sono meno generici delle CPU, ma più generici degli ASIC. Il compromesso nel grado di specializzazione è complesso e dipende da previsioni e intuizioni su quali parti dell'algoritmo rimarranno invariate tra cinque anni e quali cambieranno tra sei mesi. Nell'architettura delle prove ZK vediamo spesso una simile specializzazione multilivello. Ma per un modello mentale ampio, considerare due livelli è sufficiente. In molti campi del calcolo si verificano situazioni simili:
Dagli esempi sopra, il calcolo può certamente essere suddiviso in questo modo, e sembra essere una legge naturale. In effetti, puoi trovare esempi di specializzazione del calcolo che risalgono a decenni fa. Tuttavia, credo che questa separazione stia aumentando. E penso che ci siano delle ragioni:
Solo recentemente abbiamo raggiunto il limite dell'aumento della velocità di clock delle CPU, quindi ulteriori guadagni possono essere ottenuti solo tramite la parallelizzazione. Tuttavia, la parallelizzazione è difficile da ragionare, quindi per gli sviluppatori è spesso più pratico continuare a ragionare in modo sequenziale e lasciare che la parallelizzazione avvenga nel backend, incapsulata in moduli specializzati costruiti per operazioni specifiche.
La velocità di calcolo è diventata così elevata solo di recente che il costo computazionale della logica di business è diventato davvero trascurabile. In questo mondo, ha senso ottimizzare la VM che esegue la logica di business per obiettivi diversi dall'efficienza computazionale: facilità d'uso per gli sviluppatori, familiarità, sicurezza e altri obiettivi simili. Nel frattempo, i moduli coprocessore specializzati possono continuare a essere progettati per l'efficienza e trarre la loro sicurezza e facilità d'uso per gli sviluppatori dalla relativa semplicità dell'"interfaccia" con il collante.
Diventa sempre più chiaro quali siano le operazioni costose più importanti. Questo è più evidente nella crittografia, dove è più probabile che vengano utilizzati tipi specifici di operazioni costose: operazioni modulari, combinazioni lineari su curve ellittiche (note anche come moltiplicazione scalare multipla), trasformate di Fourier veloci, ecc. Anche nell'intelligenza artificiale, questa situazione sta diventando sempre più evidente: da oltre vent'anni la maggior parte del calcolo è "principalmente moltiplicazione di matrici" (anche se a diversi livelli di precisione). Tendenze simili stanno emergendo in altri settori. Rispetto a vent'anni fa, ci sono molti meno "sconosciuti sconosciuti" nel calcolo (intensivo).
Cosa significa tutto ciò?
Un punto chiave è che il collante (Glue) dovrebbe essere ottimizzato per essere un buon collante, mentre il coprocessore (coprocessor) dovrebbe essere ottimizzato per essere un buon coprocessore. Possiamo esplorare cosa significa questo in alcuni settori chiave.
EVM
Le macchine virtuali blockchain (come EVM) non devono essere efficienti, devono solo essere familiari. Basta aggiungere i coprocessori giusti (noti anche come "precompilati") e il calcolo in una VM inefficiente può in realtà essere efficiente quanto quello in una VM nativa efficiente. Ad esempio, il sovraccarico dovuto ai registri a 256 bit dell'EVM è relativamente piccolo, mentre i vantaggi della familiarità dell'EVM e dell'ecosistema di sviluppatori esistente sono enormi e duraturi. I team che ottimizzano l'EVM hanno persino scoperto che la mancanza di parallelizzazione di solito non è il principale ostacolo alla scalabilità.
Il modo migliore per migliorare l'EVM potrebbe essere semplicemente (i) aggiungere precompilati migliori o opcode specializzati — ad esempio, una qualche combinazione di EVM-MAX e SIMD potrebbe essere ragionevole — e (ii) migliorare il layout della memoria, ad esempio, le modifiche degli alberi Verkle come effetto collaterale riducono notevolmente il costo di accesso a slot di memoria adiacenti.
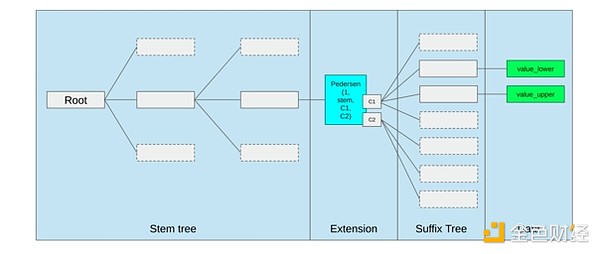
Ottimizzazione della memoria nella proposta degli alberi Verkle di Ethereum, che raggruppa le chiavi di memoria adiacenti e regola il costo del gas di conseguenza. Ottimizzazioni come questa, insieme a precompilati migliori, potrebbero essere più importanti che modificare l'EVM stessa.
Calcolo sicuro e hardware aperto
Una delle grandi sfide nell'aumentare la sicurezza del calcolo moderno a livello hardware è la sua natura troppo complessa e proprietaria: i chip sono progettati per essere efficienti, il che richiede ottimizzazioni proprietarie. Le backdoor sono facili da nascondere, le vulnerabilità side-channel vengono scoperte continuamente.
Le persone continuano a lavorare da molteplici angolazioni per promuovere alternative più aperte e sicure. Alcuni calcoli vengono sempre più eseguiti in ambienti di esecuzione affidabili, inclusi i telefoni degli utenti, il che ha già aumentato la sicurezza degli utenti. Il movimento per promuovere hardware consumer più open source continua, con alcune recenti vittorie come i laptop RISC-V che eseguono Ubuntu.
Laptop RISC-V che esegue Debian
Tuttavia, l'efficienza rimane un problema. L'autore dell'articolo linkato sopra scrive:
Design di chip open source più recenti come RISC-V non possono competere con tecnologie di processori già esistenti e migliorate da decenni. Ogni progresso ha un punto di partenza.
Idee più paranoiche, come questo design di computer RISC-V costruito su FPGA, affrontano un overhead ancora maggiore. Ma cosa succede se l'architettura collante e coprocessore significa che questo overhead in realtà non è importante? E se accettassimo che chip aperti e sicuri saranno più lenti di quelli proprietari, rinunciando se necessario a ottimizzazioni comuni come l'esecuzione speculativa e la previsione dei rami, ma cercando di compensare aggiungendo moduli ASIC (anche proprietari, se necessario) per i tipi di calcolo più intensivi? Il calcolo sensibile potrebbe essere eseguito sul "chip principale", ottimizzato per sicurezza, design open source e resistenza ai side-channel. I calcoli più intensivi (come ZK proof, AI) sarebbero eseguiti nei moduli ASIC, che avrebbero meno informazioni sul calcolo eseguito (forse, tramite offuscamento crittografico, in alcuni casi anche zero informazioni).
Crittografia
Un altro punto chiave è che tutto ciò è molto ottimistico per la crittografia, soprattutto per la crittografia programmabile che diventa mainstream. Abbiamo già visto alcune implementazioni super ottimizzate di calcoli altamente strutturati in SNARK, MPC e altri contesti: il costo di alcuni hash è solo qualche centinaio di volte superiore all'esecuzione diretta, e anche il costo dell'AI (principalmente moltiplicazione di matrici) è molto basso. Ulteriori miglioramenti come GKR potrebbero abbassare ulteriormente questo livello. L'esecuzione di VM completamente generiche, specialmente quando eseguite in un interprete RISC-V, potrebbe continuare a comportare un overhead di circa diecimila volte, ma per i motivi descritti in questo articolo, ciò non è importante: purché le parti più intensive del calcolo siano gestite separatamente con tecniche specializzate efficienti, l'overhead totale è gestibile.
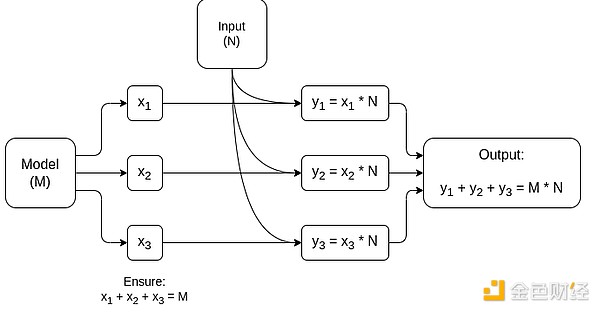
Schema semplificato di MPC specializzato per la moltiplicazione di matrici, il componente più grande nell'inferenza dei modelli AI. Vedi questo articolo per maggiori dettagli, inclusi come mantenere privati modello e input.
Un'eccezione all'idea che "il collante deve solo essere familiare, non efficiente" è la latenza, e in misura minore la larghezza di banda dei dati. Se il calcolo comporta operazioni pesanti ripetute decine di volte sugli stessi dati (come nella crittografia e nell'AI), qualsiasi latenza causata da uno strato collante inefficiente può diventare il principale collo di bottiglia del tempo di esecuzione. Quindi anche lo strato collante ha requisiti di efficienza, sebbene siano più specifici.
Conclusione
Nel complesso, credo che le tendenze sopra descritte siano sviluppi molto positivi da molteplici punti di vista. In primo luogo, è un modo ragionevole per massimizzare l'efficienza computazionale mantenendo la facilità d'uso per gli sviluppatori, ottenendo così più di entrambi a beneficio di tutti. In particolare, implementando la specializzazione lato client per l'efficienza, aumenta la nostra capacità di eseguire calcoli sensibili e ad alte prestazioni (come ZK proof, inferenza LLM) localmente sull'hardware dell'utente. In secondo luogo, crea una grande finestra di opportunità per garantire che la ricerca dell'efficienza non comprometta altri valori, in particolare sicurezza, apertura e semplicità: sicurezza e apertura contro i side-channel nell'hardware, riduzione della complessità dei circuiti in ZK-SNARK, riduzione della complessità nelle VM. Storicamente, la ricerca dell'efficienza ha relegato questi altri fattori in secondo piano. Con l'architettura collante e coprocessore, non è più necessario. Una parte della macchina è ottimizzata per l'efficienza, l'altra per la generalità e altri valori, e lavorano insieme.
Questa tendenza è anche molto favorevole alla crittografia, poiché la crittografia stessa è un esempio principale di "calcolo strutturato costoso", e questa tendenza ne accelera lo sviluppo. Ciò offre un'ulteriore opportunità per aumentare la sicurezza. Nel mondo blockchain, anche la sicurezza può essere migliorata: possiamo preoccuparci meno dell'ottimizzazione della VM e concentrarci di più sull'ottimizzazione delle precompilate e di altre funzionalità che coesistono con la VM.
In terzo luogo, questa tendenza offre opportunità di partecipazione a soggetti più piccoli e nuovi. Se il calcolo diventa meno monolitico e più modulare, la barriera all'ingresso si abbassa notevolmente. Anche con un ASIC per un solo tipo di calcolo, è possibile fare la differenza. Lo stesso vale per il campo delle prove ZK e per l'ottimizzazione dell'EVM. Scrivere codice con efficienza quasi all'avanguardia diventa più facile e accessibile. Audit e verifica formale di tale codice diventano più facili e accessibili. Infine, poiché questi campi di calcolo molto diversi stanno convergendo su alcuni modelli comuni, c'è più spazio per collaborazione e apprendimento reciproco.
Esclusione di responsabilità: il contenuto di questo articolo riflette esclusivamente l’opinione dell’autore e non rappresenta in alcun modo la piattaforma. Questo articolo non deve essere utilizzato come riferimento per prendere decisioni di investimento.
Ti potrebbe interessare anche
Il won della Corea del Sud diventa la valuta peggiore in Asia mentre il kimchi premium diventa rialzista
EUR/USD sale sopra 1,1600 mentre l'Europa respinge la minaccia di dazi di Trump