In breve
- DeepSeek V4 potrebbe essere rilasciato entro poche settimane, puntando a prestazioni di codifica di livello elite.
- Fonti interne affermano che potrebbe superare Claude e ChatGPT nei compiti di codifica a contesto lungo.
- Gli sviluppatori sono già entusiasti in vista di una possibile rivoluzione.
Il polo Arte, Moda e Intrattenimento di Decrypt.
Scopri SCENE Secondo quanto riferito, DeepSeek sta pianificando il rilascio del suo modello V4 intorno a metà febbraio e, se i test interni sono indicativi, i giganti dell'AI della Silicon Valley dovrebbero essere preoccupati.
La startup di intelligenza artificiale con sede a Hangzhou potrebbe puntare a un rilascio intorno al 17 febbraio — durante il Capodanno Lunare, ovviamente — con un modello specificamente progettato per i compiti di codifica, secondo
. Persone a conoscenza diretta del progetto affermano che V4 supera sia Claude di Anthropic che la serie GPT di OpenAI nei benchmark interni, specialmente nella gestione di prompt di codice estremamente lunghi.
Naturalmente, nessun benchmark o informazione sul modello è stata resa pubblica, quindi è impossibile verificare direttamente tali affermazioni. DeepSeek non ha nemmeno confermato le voci.
Tuttavia, la comunità degli sviluppatori non sta aspettando una comunicazione ufficiale. Su Reddit, r/DeepSeek e r/LocalLLaMA sono già molto attivi, gli utenti stanno accumulando crediti API e gli appassionati su X hanno già condiviso le loro previsioni secondo cui V4 potrebbe consolidare la posizione di DeepSeek come l'outsider agguerrito che rifiuta di seguire le regole multimiliardarie della Silicon Valley.
Anthropic ha bloccato gli abbonamenti Claude nelle app di terze parti come OpenCode e avrebbe interrotto l’accesso a xAI e OpenAI.
Claude e Claude Code sono ottimi, ma non ancora dieci volte migliori. Questo spingerà solo altri laboratori a muoversi più velocemente sui loro modelli/agent di codifica.
Si dice che DeepSeek V4 stia per essere lanciato…
— Yuchen Jin (@Yuchenj_UW) 9 gennaio 2026
Non sarebbe la prima rivoluzione di DeepSeek. Quando l’azienda ha rilasciato il suo modello di ragionamento R1 nel gennaio 2025, ha innescato una svendita da 1 trilione di dollari nei mercati globali.
Il motivo? L’R1 di DeepSeek ha eguagliato il modello o1 di OpenAI nei benchmark di matematica e ragionamento pur costando, secondo quanto riferito, solo 6 milioni di dollari per lo sviluppo — circa 68 volte meno rispetto alle spese dei concorrenti. Il modello V3 ha poi raggiunto il 90,2% sul benchmark MATH-500, superando il 78,3% di Claude e l’aggiornamento recente “V3.2 Speciale” ne ha migliorato ulteriormente le prestazioni.
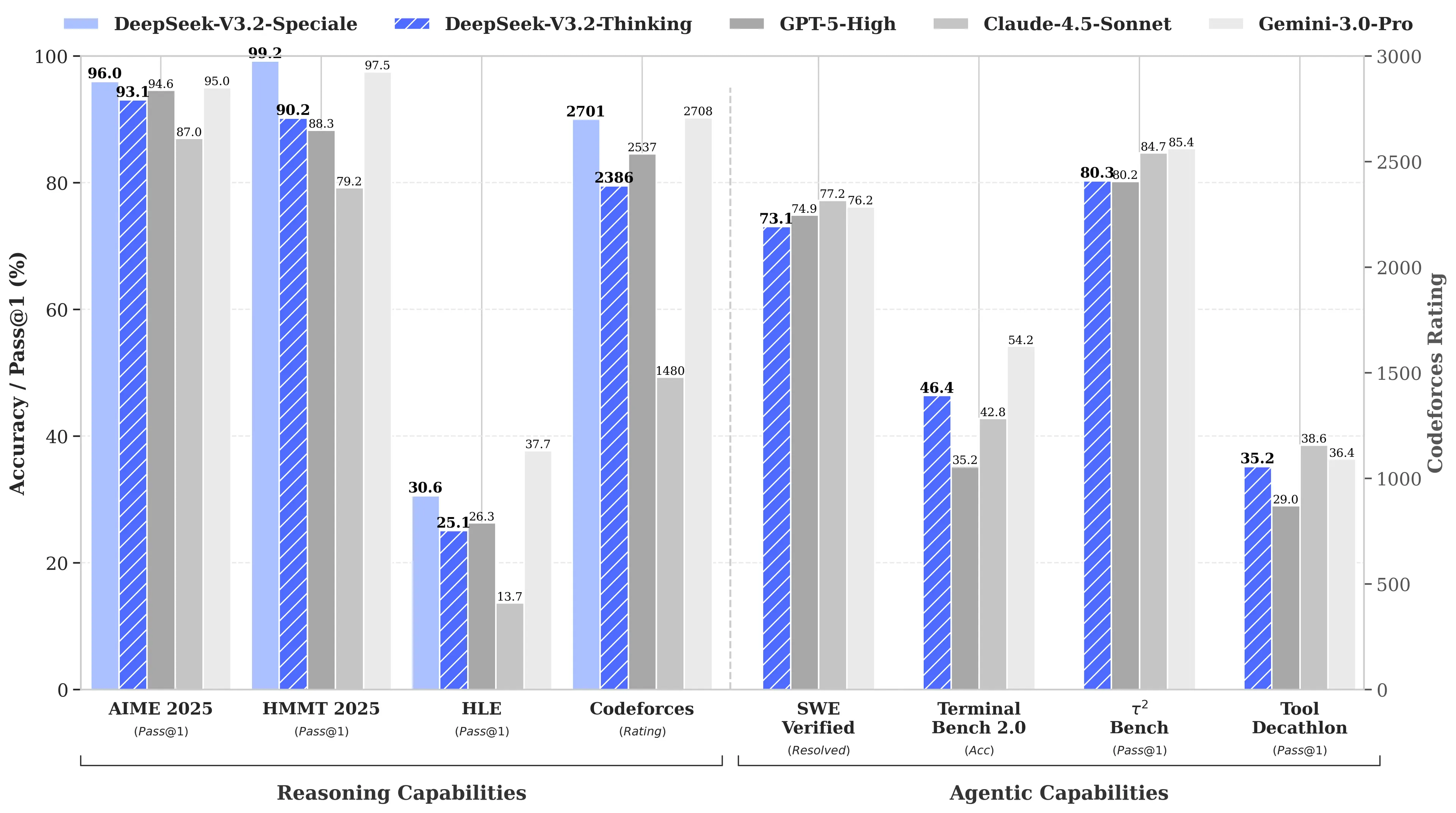
Immagine: DeepSeek
L’orientamento verso la codifica di V4 sarebbe una svolta strategica. Mentre R1 si concentrava sul ragionamento puro—logica, matematica, dimostrazioni formali—V4 è un modello ibrido (compiti di ragionamento e non) che punta al mercato enterprise degli sviluppatori, dove la generazione di codice ad alta precisione si traduce direttamente in ricavi.
Per rivendicare la supremazia, V4 dovrebbe superare Claude Opus 4.5, che attualmente detiene il record SWE-bench Verified con l’80,9%. Ma se i lanci precedenti di DeepSeek sono indicativi, allora questo potrebbe non essere impossibile da raggiungere nemmeno con tutte le limitazioni che un laboratorio AI cinese si trova ad affrontare.
Il segreto non così segreto
Supponendo che le voci siano vere, come può un piccolo laboratorio raggiungere un simile risultato?
L’arma segreta dell'azienda potrebbe essere contenuta nel suo articolo di ricerca del 1° gennaio: Manifold-Constrained Hyper-Connections, o mHC. Co-firmato dal fondatore Liang Wenfeng, il nuovo metodo di addestramento affronta un problema fondamentale nello scaling dei grandi modelli linguistici—come espandere la capacità di un modello senza che diventi instabile o esploda durante l’addestramento.
Le architetture AI tradizionali forzano tutte le informazioni attraverso un unico canale ristretto. mHC allarga quel canale in più flussi che possono scambiarsi informazioni senza causare il collasso dell’addestramento.
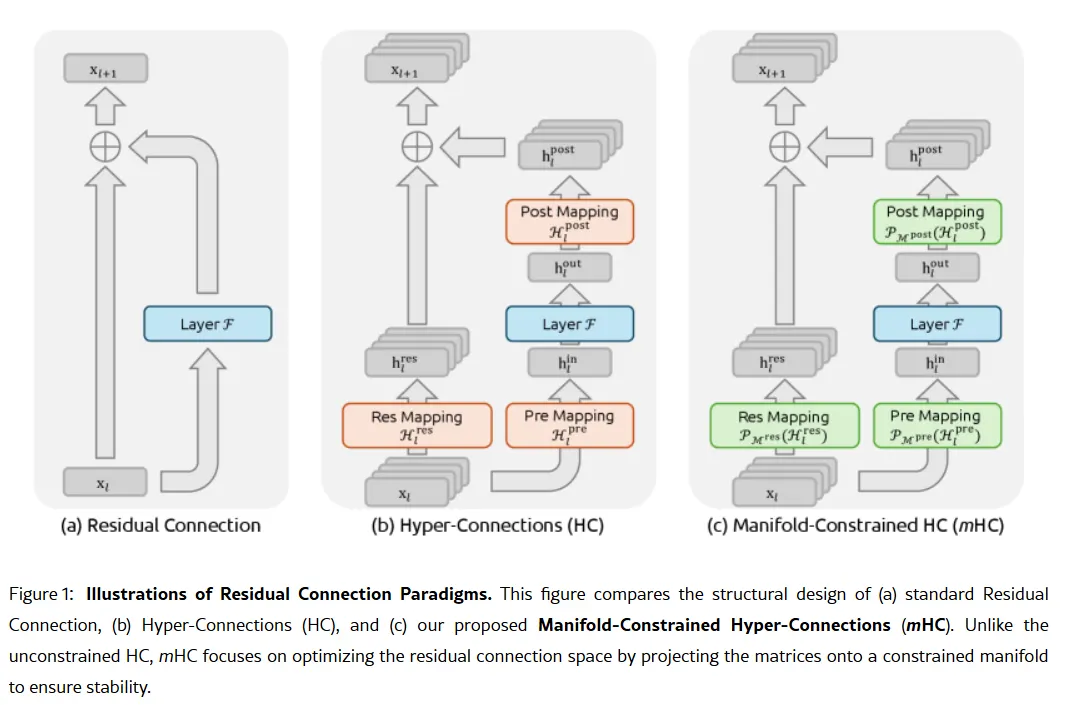
Immagine: DeepSeek
Wei Sun, principale analista AI per Counterpoint Research, ha definito mHC una "sorprendente svolta" in un commento a
. La tecnica, afferma, dimostra che DeepSeek può "aggirare i colli di bottiglia computazionali e sbloccare salti di intelligenza", anche con accesso limitato a chip avanzati a causa delle restrizioni all’export degli Stati Uniti.
Lian Jye Su, chief analyst di Omdia, ha notato che la disponibilità di DeepSeek a pubblicare i suoi metodi segnala una "nuova fiducia nell’industria AI cinese". L’approccio open-source dell’azienda l’ha resa molto amata tra gli sviluppatori che la vedono come incarnazione di ciò che OpenAI era un tempo, prima di virare verso modelli chiusi e raccolte fondi da miliardi di dollari.
Non tutti sono convinti. Alcuni sviluppatori su Reddit si lamentano che i modelli di ragionamento di DeepSeek sprecano risorse computazionali in compiti semplici, mentre i critici sostengono che i benchmark dell’azienda non riflettono la complessità del mondo reale. Un post su Medium intitolato "DeepSeek fa schifo - E ho smesso di fingere che non sia così" è diventato virale nell’aprile 2025, accusando i modelli di produrre "banalità con bug" e "librerie allucinate".
DeepSeek porta inoltre con sé delle criticità. Le preoccupazioni sulla privacy hanno afflitto l’azienda, con alcuni governi che hanno vietato l’app nativa di DeepSeek. I legami dell’azienda con la Cina e le domande sulla censura nei suoi modelli aggiungono frizioni geopolitiche al dibattito tecnico.
Tuttavia, lo slancio è innegabile. DeepSeek è stata ampiamente adottata in Asia e, se V4 manterrà le promesse sulla codifica, potrebbe seguirne l’adozione enterprise anche in Occidente.
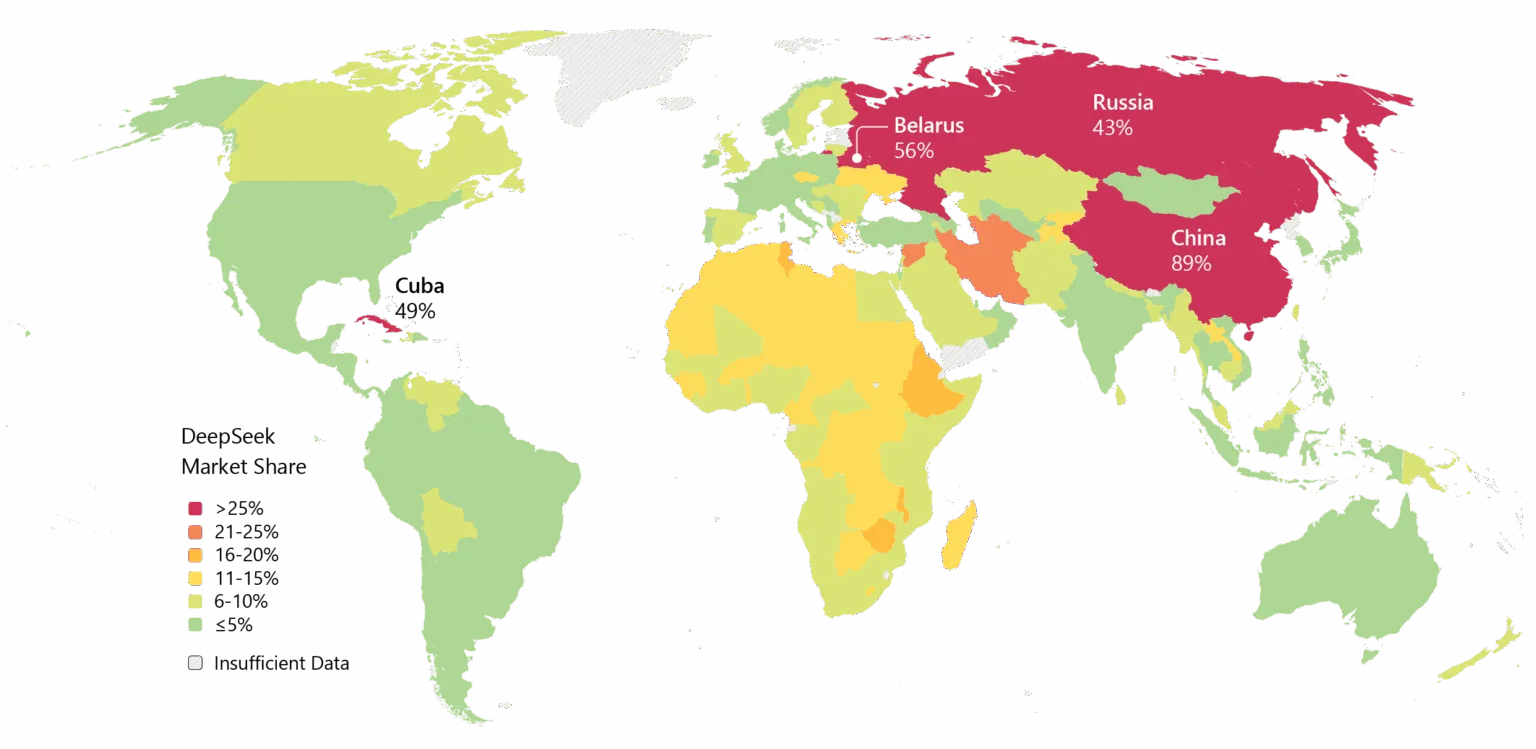
Immagine: Microsoft
C’è anche la questione del tempismo. Secondo
, DeepSeek aveva originariamente pianificato di rilasciare il suo modello R2 a maggio 2025, ma ha posticipato la tabella di marcia dopo che il fondatore Liang si è detto insoddisfatto delle sue prestazioni. Ora, con V4 che punta, secondo quanto riferito, a febbraio e R2 che potrebbe seguire ad agosto, l’azienda sta procedendo a un ritmo che suggerisce urgenza — o fiducia. Forse entrambe.