
OpenAI nakazano przekazanie 20 milionów logów ChatGPT w sprawie o prawa autorskie z NYT

W skrócie
- Orzeczenie zobowiązuje OpenAI do udostępnienia 20 milionów logów czatów po miesiącach sporów dotyczących prywatności, przechowywania i zakresu.
- Sędzia Ona T. Wang orzekła, że wielkość próbki jest „proporcjonalna” do potrzeb sprawy w celu udowodnienia, czy wyniki ChatGPT odtwarzały treści Times.
- Sprawa dołącza do rosnącej fali wyzwań dotyczących praw autorskich, skierowanych przeciwko temu, jak laboratoria AI pozyskują i wykorzystują dane treningowe.
Federalny sędzia magistracki nakazał OpenAI przekazanie około 20 milionów zanonimizowanych logów ChatGPT do The New York Times oraz innych powodów, pogłębiając ekspozycję firmy rozwijającej AI na szereg sporów dotyczących praw autorskich i zarządzania danymi.
Wydane w środę w Nowym Jorku orzeczenie odrzuca wniosek OpenAI o zablokowanie udostępnienia zapisów rozmów użytkowników i nakazuje firmie przekazanie logów w ramach ochronnego systemu.
Wynik ten może wpłynąć na to, jak firmy technologiczne takie jak OpenAI, Anthropic i Perplexity pozyskują dane treningowe, licencjonują treści oraz budują zabezpieczenia dotyczące tego, co ich systemy mogą generować.
Chociaż sąd „uznaje, że względy prywatności użytkowników OpenAI są szczere”, takie względy „są tylko jednym z czynników w analizie proporcjonalności i nie mogą dominować tam, gdzie istnieje wyraźna istotność i minimalne obciążenie”, napisała sędzia magistracka USA Ona T. Wang.
Orzeczenie wynika z trwającego pozwu Times, który zarzuca, że modele OpenAI były trenowane na chronionych prawem autorskim treściach prasowych bez zgody. Pozew został złożony po raz pierwszy w grudniu 2023 roku.
W styczniu ubiegłego roku OpenAI zakwestionowało roszczenia NYT i złożyło kontrpozew, twierdząc, że publikacja nie „przedstawia całej historii”.
Sąd później uznał, że próbka 20 milionów logów czatów jest „proporcjonalna do potrzeb sprawy”, aby ocenić, czy wyniki ChatGPT kopiowały materiały NYT.
W ciągu ostatniego roku spór się nasilił, a powodowie domagali się szerokiego dostępu do danych wyjściowych, podczas gdy OpenAI ostrzegało, że szeroka produkcja tych materiałów zwiększy obciążenia związane z prywatnością i operacjami.
W czerwcu OpenAI napotkało kolejny problem, gdy sąd nakazał firmie zachowanie szerokiego zakresu danych użytkowników ChatGPT na potrzeby procesu, w tym rozmów, które użytkownicy mogli już usunąć.
Kilka miesięcy później, w październiku, spór powrócił, gdy sąd zwrócił uwagę na zgłoszenie OpenAI z 20 października (ECF 679), które kwestionowało produkcję próbki 20 milionów logów, i nakazał obu stronom przedstawić wyjaśnienia, dlaczego się nie zgadzają.
W tym czasie sędzia naciskała strony, by wyjaśniły, jak spór odnosi się do wcześniejszych obaw dotyczących usuniętych logów i czy OpenAI wycofało się z wcześniejszych ustaleń dotyczących tego, co wcześniej twierdziło, że przekaże.
Niemiecka narodowa organizacja praw muzycznych odniosła częściowe, ale decydujące zwycięstwo przeciwko OpenAI po tym, jak sąd w Monachium orzekł, że modele leżące u podstaw ChatGPT nielegalnie odtwarzały chronione prawem autorskim niemieckie teksty piosenek. Orzeczenie nakazuje OpenAI zaprzestanie reprodukcji, ujawnienie odpowiednich szczegółów treningowych oraz wypłatę odszkodowania właścicielom praw. Orzeczenie nie jest jeszcze prawomocne i OpenAI może się od niego odwołać. Jeśli zostanie utrzymane, decyzja może zmienić sposób, w jaki firmy AI pozyskują i licencjonują materiały kreatywne w Europie, podczas gdy regulatorzy rozważają szersze o...
News Law and Order 3 min readVince DioquinoNov 13, 2025
Pod koniec ubiegłego miesiąca OpenAI złożyło formalny sprzeciw, prosząc sędziego okręgowego o uchylenie orzeczenia sędziego magistrackiego dotyczącego ujawnienia materiałów dowodowych.
Firma argumentowała, że orzeczenie było „oczywiście błędne” i „nieproporcjonalne”, ponieważ zmusiłoby ją do ujawnienia milionów prywatnych rozmów użytkowników, zgodnie z dokumentem sądowym udostępnionym Decrypt przez przedstawiciela OpenAI.
Spór pojawia się w ramach szerszej ofensywy przeciwko laboratoriom AI, w której autorzy, organizacje prasowe, wydawcy muzyczni i repozytoria kodu próbują sprawdzić, jak daleko sięgają istniejące przepisy dotyczące praw autorskich, gdy modele przetwarzają i odtwarzają chronione materiały.
Sądy w całych Stanach Zjednoczonych i Europie obecnie rozpatrują podobne roszczenia.
Zastrzeżenie: Treść tego artykułu odzwierciedla wyłącznie opinię autora i nie reprezentuje platformy w żadnym charakterze. Niniejszy artykuł nie ma służyć jako punkt odniesienia przy podejmowaniu decyzji inwestycyjnych.
Może Ci się również spodobać
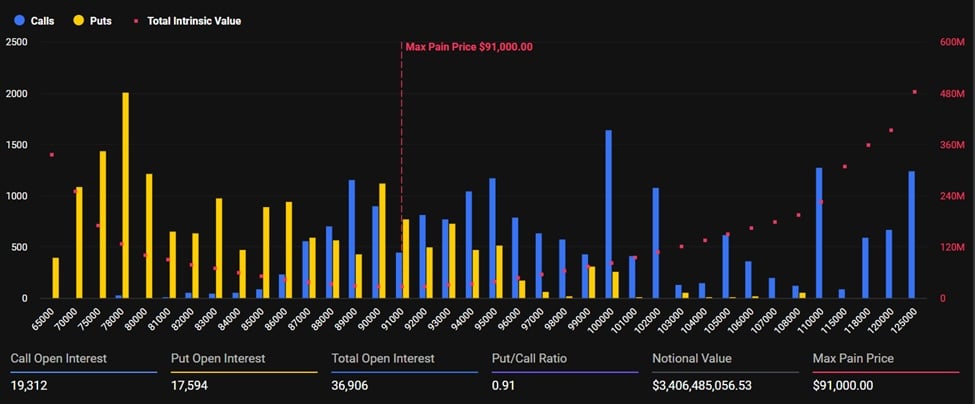
Cena Bitcoin ponownie testuje wsparcie na poziomie 91 000 dolarów przy wygaśnięciu opcji o wartości 3,4 miliarda dolarów: co dalej?
Cena Bitcoin ponownie testuje wsparcie na poziomie 91 000 dolarów przed wygaśnięciem opcji 5 grudnia, podczas gdy byki walczą o zdecydowane wybicie.
Ten altcoin może iść wbrew dzisiejszemu rynkowi niedźwiedzia, twierdzi ChatGPT
Globalna kapitalizacja rynku kryptowalut wynosi dziś około 3,1–3,2 biliona dolarów, co oznacza spadek o około 1,7–1,8% w ciągu ostatnich 24 godzin. Większość głównych kryptowalut notuje spadki, z wyjątkiem tej altcoiny, która nadal utrzymuje silne fundamenty.
Tokeny zakotwiczone na danych (DAT) i ERC-8028: natywny standard aktywów AI dla zdecentralizowanej sztucznej inteligencji (dAI) na Ethereum
Jeśli ethereum ma stać się warstwą rozliczeniową i koordynacyjną dla agentów AI, potrzebny jest sposób reprezentowania natywnych aktywów AI: taki, który posiada uniwersalność podobną do ERC-20, a jednocześnie spełnia specyficzne wymagania modeli ekonomicznych AI.

Spotowe ETF-y na bitcoin odnotowały odpływ 195 milionów dolarów, największy dzienny odpływ od 2 tygodni
Szybki przegląd: Spotowe ETF-y bitcoin w USA odnotowały w czwartek odpływy netto w wysokości 194,6 milionów dolarów, w porównaniu do odpływów w wysokości 14,9 milionów dolarów dzień wcześniej. Czwartkowy odpływ był ich największym jednodniowym odpływem od 20 listopada.
