
Estreia em 2026, Jensen Huang lança uma "bomba nuclear" de 2,5 toneladas no evento | CES2026

Mostrar original
Por:爱范儿
*Há um pequeno vídeo bônus no final. Esta é a primeira vez em 5 anos que a NVIDIA não lança uma placa de vídeo de consumo na CES. O CEO Jensen Huang caminhou confiante até o centro do palco do NVIDIA Live, ainda vestindo a jaqueta de couro de crocodilo brilhante do ano passado.  Diferente do ano passado, quando fez uma apresentação principal solo, em 2026 Jensen Huang teve uma agenda apertada. Do NVIDIA Live ao diálogo sobre IA industrial da Siemens, até o Lenovo TechWorld, ele participou de três eventos em 48 horas. Na última vez, ele lançou a série de placas de vídeo RTX 50 na CES. Desta vez, IA física, tecnologia robótica e uma “ bomba nuclear corporativa ” de 2,5 toneladas foram os verdadeiros protagonistas. Plataforma de computação Vera Rubin estreia, quanto mais compra, mais economiza Durante a apresentação, o sempre irreverente Jensen levou ao palco um rack de servidor de IA de 2,5 toneladas, introduzindo o ponto central do evento: a plataforma de computação Vera Rubin, nomeada em homenagem à astrônoma que descobriu a matéria escura, com um único objetivo: Acelerar a velocidade de treinamento de IA, antecipando a chegada da próxima geração de modelos.
Diferente do ano passado, quando fez uma apresentação principal solo, em 2026 Jensen Huang teve uma agenda apertada. Do NVIDIA Live ao diálogo sobre IA industrial da Siemens, até o Lenovo TechWorld, ele participou de três eventos em 48 horas. Na última vez, ele lançou a série de placas de vídeo RTX 50 na CES. Desta vez, IA física, tecnologia robótica e uma “ bomba nuclear corporativa ” de 2,5 toneladas foram os verdadeiros protagonistas. Plataforma de computação Vera Rubin estreia, quanto mais compra, mais economiza Durante a apresentação, o sempre irreverente Jensen levou ao palco um rack de servidor de IA de 2,5 toneladas, introduzindo o ponto central do evento: a plataforma de computação Vera Rubin, nomeada em homenagem à astrônoma que descobriu a matéria escura, com um único objetivo: Acelerar a velocidade de treinamento de IA, antecipando a chegada da próxima geração de modelos.  Normalmente, existe uma regra interna na NVIDIA: cada geração de produto altera no máximo 1-2 chips. Mas desta vez, a Vera Rubin rompeu com o padrão ao redesenhar seis chips de uma só vez, todos já em plena produção.
Normalmente, existe uma regra interna na NVIDIA: cada geração de produto altera no máximo 1-2 chips. Mas desta vez, a Vera Rubin rompeu com o padrão ao redesenhar seis chips de uma só vez, todos já em plena produção.
A razão é que, com a desaceleração da Lei de Moore, os métodos tradicionais de aumento de desempenho não acompanham o crescimento anual de 10 vezes dos modelos de IA, então a NVIDIA optou por um “design de colaboração extrema”—inovando em todos os chips e em todos os níveis da plataforma ao mesmo tempo. Estes seis chips são: 1. Vera CPU: - 88 núcleos Olympus personalizados pela NVIDIA - Tecnologia de multithreading espacial NVIDIA, suporta 176 threads - Largura de banda NVLink C2C de 1,8 TB/s - Memória do sistema de 1,5 TB (3 vezes a da Grace) - Largura de banda LPDDR5X de 1,2 TB/s - 227 bilhões de transistores
Estes seis chips são: 1. Vera CPU: - 88 núcleos Olympus personalizados pela NVIDIA - Tecnologia de multithreading espacial NVIDIA, suporta 176 threads - Largura de banda NVLink C2C de 1,8 TB/s - Memória do sistema de 1,5 TB (3 vezes a da Grace) - Largura de banda LPDDR5X de 1,2 TB/s - 227 bilhões de transistores  2. Rubin GPU: - Capacidade de inferência NVFP4 de 50 PFLOPS, 5 vezes a do Blackwell anterior - Possui 336 bilhões de transistores, 1,6 vezes mais que o Blackwell - Equipado com terceira geração do mecanismo Transformer, ajusta dinamicamente a precisão conforme as necessidades do modelo Transformer
2. Rubin GPU: - Capacidade de inferência NVFP4 de 50 PFLOPS, 5 vezes a do Blackwell anterior - Possui 336 bilhões de transistores, 1,6 vezes mais que o Blackwell - Equipado com terceira geração do mecanismo Transformer, ajusta dinamicamente a precisão conforme as necessidades do modelo Transformer  3. Placa de rede ConnectX-9: - Ethernet de 800 Gb/s baseada em 200G PAM4 SerDes - RDMA programável e acelerador de caminho de dados - Certificação CNSA e FIPS - 23 bilhões de transistores
3. Placa de rede ConnectX-9: - Ethernet de 800 Gb/s baseada em 200G PAM4 SerDes - RDMA programável e acelerador de caminho de dados - Certificação CNSA e FIPS - 23 bilhões de transistores  4. BlueField-4 DPU: - Motor de ponta a ponta construído especialmente para a nova geração de plataformas de armazenamento de IA - DPU de 800G Gb/s para SmartNIC e processadores de armazenamento - CPU Grace de 64 núcleos combinada com ConnectX-9 - 126 bilhões de transistores
4. BlueField-4 DPU: - Motor de ponta a ponta construído especialmente para a nova geração de plataformas de armazenamento de IA - DPU de 800G Gb/s para SmartNIC e processadores de armazenamento - CPU Grace de 64 núcleos combinada com ConnectX-9 - 126 bilhões de transistores  5. Chip de troca NVLink-6: - Conecta 18 nós de computação, suporta até 72 Rubin GPUs rodando como um só conjunto - Na arquitetura NVLink 6, cada GPU pode obter largura de banda all-to-all de 3,6 TB por segundo - Utiliza 400G SerDes, suporta In-Network SHARP Collectives, podendo realizar operações coletivas dentro da rede de troca
5. Chip de troca NVLink-6: - Conecta 18 nós de computação, suporta até 72 Rubin GPUs rodando como um só conjunto - Na arquitetura NVLink 6, cada GPU pode obter largura de banda all-to-all de 3,6 TB por segundo - Utiliza 400G SerDes, suporta In-Network SHARP Collectives, podendo realizar operações coletivas dentro da rede de troca  6. Chip de troca óptica Spectrum-6 para Ethernet - 512 canais, 200 Gbps por canal, para transmissão de dados ainda mais rápida - Tecnologia de silício fotônico com processo COOP da TSMC - Interface óptica copackaged - 352 bilhões de transistores
6. Chip de troca óptica Spectrum-6 para Ethernet - 512 canais, 200 Gbps por canal, para transmissão de dados ainda mais rápida - Tecnologia de silício fotônico com processo COOP da TSMC - Interface óptica copackaged - 352 bilhões de transistores  Com a integração profunda destes seis chips, o sistema Vera Rubin NVL72 teve uma melhoria abrangente de desempenho em relação à geração anterior Blackwell. Em tarefas de inferência NVFP4, este chip alcançou um poder de computação impressionante de 3,6 EFLOPS, cinco vezes o da arquitetura Blackwell anterior. Para treinamento NVFP4, o desempenho chega a 2,5 EFLOPS, um aumento de 3,5 vezes. No armazenamento, o NVL72 conta com 54TB de memória LPDDR5X, três vezes o do produto anterior. A capacidade de HBM (memória de alta largura de banda) chega a 20,7TB, um aumento de 1,5 vez. Em largura de banda, o HBM4 chega a 1,6 PB/s, aumento de 2,8 vezes; largura de banda Scale-Up chega a 260 TB/s, aumento de 2 vezes. Apesar de tanta melhoria de desempenho, a contagem de transistores subiu apenas 1,7 vez, para 220 trilhões, demonstrando inovação na tecnologia de fabricação de semicondutores.
Com a integração profunda destes seis chips, o sistema Vera Rubin NVL72 teve uma melhoria abrangente de desempenho em relação à geração anterior Blackwell. Em tarefas de inferência NVFP4, este chip alcançou um poder de computação impressionante de 3,6 EFLOPS, cinco vezes o da arquitetura Blackwell anterior. Para treinamento NVFP4, o desempenho chega a 2,5 EFLOPS, um aumento de 3,5 vezes. No armazenamento, o NVL72 conta com 54TB de memória LPDDR5X, três vezes o do produto anterior. A capacidade de HBM (memória de alta largura de banda) chega a 20,7TB, um aumento de 1,5 vez. Em largura de banda, o HBM4 chega a 1,6 PB/s, aumento de 2,8 vezes; largura de banda Scale-Up chega a 260 TB/s, aumento de 2 vezes. Apesar de tanta melhoria de desempenho, a contagem de transistores subiu apenas 1,7 vez, para 220 trilhões, demonstrando inovação na tecnologia de fabricação de semicondutores.  Na engenharia, a Vera Rubin também trouxe avanços técnicos. Antes, um nó de supercomputação precisava de 43 cabos, montagem levava duas horas e era fácil errar. Agora, o nó Vera Rubin usa zero cabos, apenas seis tubos de resfriamento líquido, montado em cinco minutos. Mais impressionante ainda, na parte de trás do rack há quase 3,2 km de cabos de cobre, 5.000 cabos formam a rede backbone NVLink, atingindo velocidade de 400Gbps. Como disse Jensen: “Talvez pese algumas centenas de libras, você precisa ser um CEO em boa forma para este trabalho”. No universo da IA, tempo é dinheiro. Um dado fundamental: para treinar um modelo de 10 trilhões de parâmetros, Rubin precisa de apenas 1/4 do número de sistemas Blackwell, e o custo para gerar um token é cerca de 1/10 do Blackwell.
Na engenharia, a Vera Rubin também trouxe avanços técnicos. Antes, um nó de supercomputação precisava de 43 cabos, montagem levava duas horas e era fácil errar. Agora, o nó Vera Rubin usa zero cabos, apenas seis tubos de resfriamento líquido, montado em cinco minutos. Mais impressionante ainda, na parte de trás do rack há quase 3,2 km de cabos de cobre, 5.000 cabos formam a rede backbone NVLink, atingindo velocidade de 400Gbps. Como disse Jensen: “Talvez pese algumas centenas de libras, você precisa ser um CEO em boa forma para este trabalho”. No universo da IA, tempo é dinheiro. Um dado fundamental: para treinar um modelo de 10 trilhões de parâmetros, Rubin precisa de apenas 1/4 do número de sistemas Blackwell, e o custo para gerar um token é cerca de 1/10 do Blackwell. 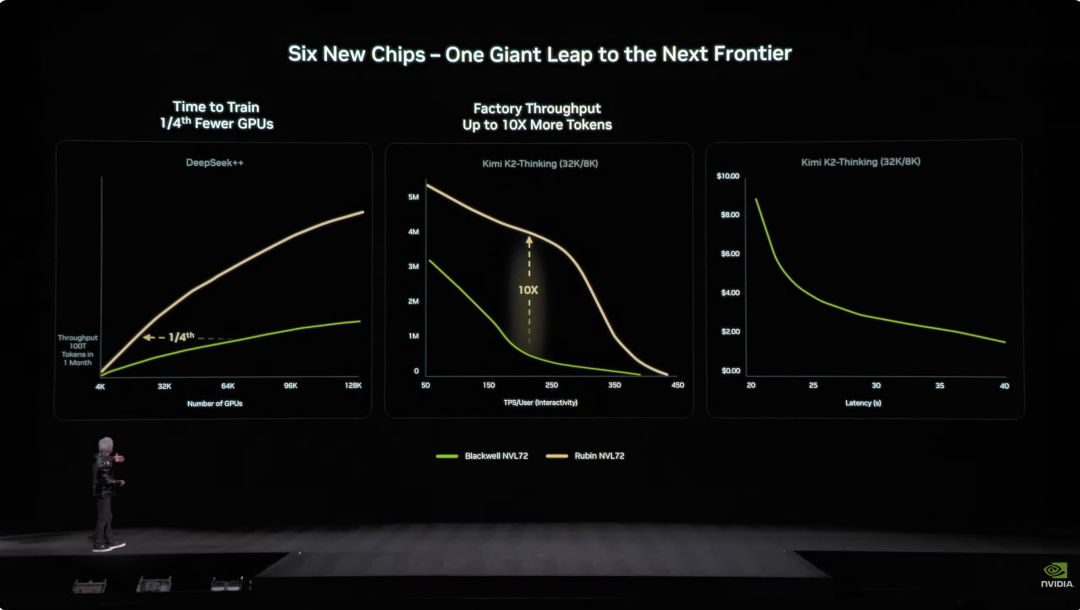 Além disso, embora o consumo de energia do Rubin seja o dobro do Grace Blackwell, o ganho de desempenho é muito maior: 5 vezes em inferência, 3,5 vezes em treinamento. Mais importante, o Rubin aumentou em 10 vezes a eficiência (tokens de IA por watt e por dólar) em relação ao Blackwell. Para um data center de gigawatts de US$ 50 bilhões, isso significa dobrar a capacidade de receita. No passado, o maior problema do setor de IA era a memória de contexto insuficiente. Quando a IA trabalha, ela gera “KV Cache” (cache de chave-valor), que é a “memória de trabalho” da IA. O problema é que à medida que as conversas aumentam e os modelos crescem, a memória HBM fica insuficiente.
Além disso, embora o consumo de energia do Rubin seja o dobro do Grace Blackwell, o ganho de desempenho é muito maior: 5 vezes em inferência, 3,5 vezes em treinamento. Mais importante, o Rubin aumentou em 10 vezes a eficiência (tokens de IA por watt e por dólar) em relação ao Blackwell. Para um data center de gigawatts de US$ 50 bilhões, isso significa dobrar a capacidade de receita. No passado, o maior problema do setor de IA era a memória de contexto insuficiente. Quando a IA trabalha, ela gera “KV Cache” (cache de chave-valor), que é a “memória de trabalho” da IA. O problema é que à medida que as conversas aumentam e os modelos crescem, a memória HBM fica insuficiente.  A NVIDIA lançou no ano passado a arquitetura Grace-Blackwell para expandir a memória, mas ainda não era suficiente. A solução Vera Rubin é implantar processadores BlueField-4 no rack, especialmente para gerenciar o KV Cache. Cada nó tem 4 BlueField-4, cada um com 150TB de memória de contexto, distribuída para as GPUs. Cada GPU recebe 16TB extras de memória—sendo que a memória nativa da GPU é de cerca de 1TB—e, crucialmente, a largura de banda permanece em 200Gbps, sem perda de velocidade. No entanto, apenas capacidade não basta: para que “post-its” distribuídos em dezenas de racks e milhares de GPUs ajam como uma única memória, a rede precisa ser “grande, rápida e estável”. É aqui que entra o Spectrum-X. Spectrum-X é a primeira plataforma de rede Ethernet de ponta a ponta do mundo “projetada para IA generativa”, trazendo a mais recente geração com processo COOP da TSMC, tecnologia de silício fotônico, 512 canais × 200Gbps. Jensen fez as contas: um data center de gigawatts custa US$ 50 bilhões, Spectrum-X pode aumentar a produtividade em 25%, economizando US$ 5 bilhões. “Você pode dizer que este sistema de rede é quase ‘de graça’.” Em segurança, o Vera Rubin também suporta Computação Confidencial. Todos os dados são criptografados durante transmissão, armazenamento e processamento, incluindo todos os barramentos como PCIe, NVLink e comunicação CPU-GPU. As empresas podem implantar seus modelos em sistemas externos sem medo de vazamento de dados. DeepSeek surpreendeu o mundo, open source e agentes são o mainstream da IA Depois do prato principal, voltamos ao início do discurso. Jensen Huang abriu com um número impressionante: cerca de US$ 10 trilhões em recursos computacionais investidos na última década estão sendo totalmente modernizados. Mas não é apenas uma atualização de hardware, é mais sobre uma mudança de paradigma de software. Ele destacou especialmente os modelos de agentes com capacidade de agir de forma autônoma, mencionando o Cursor, que mudou completamente a forma de programar dentro da NVIDIA.
A NVIDIA lançou no ano passado a arquitetura Grace-Blackwell para expandir a memória, mas ainda não era suficiente. A solução Vera Rubin é implantar processadores BlueField-4 no rack, especialmente para gerenciar o KV Cache. Cada nó tem 4 BlueField-4, cada um com 150TB de memória de contexto, distribuída para as GPUs. Cada GPU recebe 16TB extras de memória—sendo que a memória nativa da GPU é de cerca de 1TB—e, crucialmente, a largura de banda permanece em 200Gbps, sem perda de velocidade. No entanto, apenas capacidade não basta: para que “post-its” distribuídos em dezenas de racks e milhares de GPUs ajam como uma única memória, a rede precisa ser “grande, rápida e estável”. É aqui que entra o Spectrum-X. Spectrum-X é a primeira plataforma de rede Ethernet de ponta a ponta do mundo “projetada para IA generativa”, trazendo a mais recente geração com processo COOP da TSMC, tecnologia de silício fotônico, 512 canais × 200Gbps. Jensen fez as contas: um data center de gigawatts custa US$ 50 bilhões, Spectrum-X pode aumentar a produtividade em 25%, economizando US$ 5 bilhões. “Você pode dizer que este sistema de rede é quase ‘de graça’.” Em segurança, o Vera Rubin também suporta Computação Confidencial. Todos os dados são criptografados durante transmissão, armazenamento e processamento, incluindo todos os barramentos como PCIe, NVLink e comunicação CPU-GPU. As empresas podem implantar seus modelos em sistemas externos sem medo de vazamento de dados. DeepSeek surpreendeu o mundo, open source e agentes são o mainstream da IA Depois do prato principal, voltamos ao início do discurso. Jensen Huang abriu com um número impressionante: cerca de US$ 10 trilhões em recursos computacionais investidos na última década estão sendo totalmente modernizados. Mas não é apenas uma atualização de hardware, é mais sobre uma mudança de paradigma de software. Ele destacou especialmente os modelos de agentes com capacidade de agir de forma autônoma, mencionando o Cursor, que mudou completamente a forma de programar dentro da NVIDIA. 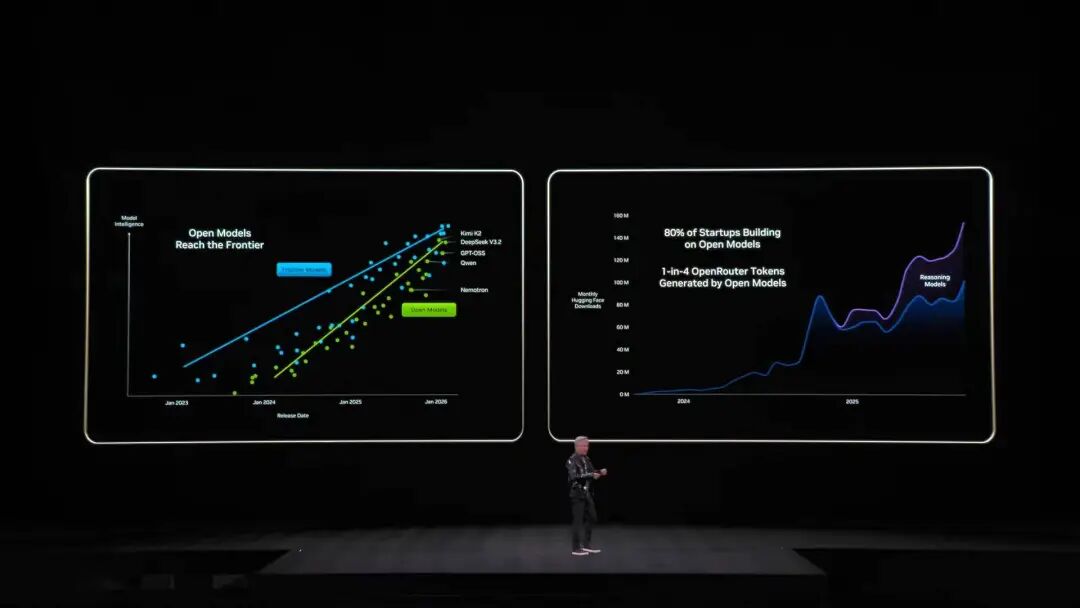 O que mais empolgou a plateia foi seu alto elogio à comunidade open source. Jensen afirmou que o avanço do DeepSeek V1 no ano passado surpreendeu o mundo; como o primeiro sistema de inferência open source, impulsionou toda a indústria. No slide, vemos os conhecidos players chineses Kimi k2 e DeepSeek V3.2 ocupando o primeiro e segundo lugar em open source. Jensen acredita que, embora os modelos open source estejam atualmente cerca de seis meses atrás dos mais avançados, um novo modelo aparece a cada seis meses. Essa velocidade de iteração faz com que startups, gigantes e pesquisadores não queiram ficar de fora, incluindo a própria NVIDIA. Por isso, desta vez não venderam apenas “pás” e placas de vídeo; a NVIDIA construiu o supercomputador DGX Cloud, valendo bilhões de dólares, e desenvolveu modelos de ponta como La Proteina (síntese de proteínas) e OpenFold 3.
O que mais empolgou a plateia foi seu alto elogio à comunidade open source. Jensen afirmou que o avanço do DeepSeek V1 no ano passado surpreendeu o mundo; como o primeiro sistema de inferência open source, impulsionou toda a indústria. No slide, vemos os conhecidos players chineses Kimi k2 e DeepSeek V3.2 ocupando o primeiro e segundo lugar em open source. Jensen acredita que, embora os modelos open source estejam atualmente cerca de seis meses atrás dos mais avançados, um novo modelo aparece a cada seis meses. Essa velocidade de iteração faz com que startups, gigantes e pesquisadores não queiram ficar de fora, incluindo a própria NVIDIA. Por isso, desta vez não venderam apenas “pás” e placas de vídeo; a NVIDIA construiu o supercomputador DGX Cloud, valendo bilhões de dólares, e desenvolveu modelos de ponta como La Proteina (síntese de proteínas) e OpenFold 3.  O ecossistema open source de modelos da NVIDIA abrange biomedicina, IA física, modelos de agentes, robótica e direção autônoma Entre os destaques do discurso estão vários modelos open source da família NVIDIA Nemotron, incluindo voz, multimodalidade, geração aumentada por busca e segurança. Jensen também mencionou que os modelos open source Nemotron têm ótimo desempenho em vários rankings e estão sendo amplamente adotados por empresas. O que é IA física? Lançamento de dezenas de modelos de uma só vez Se os grandes modelos de linguagem resolvem problemas do “mundo digital”, a próxima ambição da NVIDIA é conquistar o “mundo físico”. Jensen mencionou que, para que a IA entenda as leis da física e sobreviva no mundo real, os dados são extremamente escassos. Além dos modelos open source de agentes Nemotron, ele propôs a arquitetura central das “três computadoras” para construir uma IA física (Physical AI).
O ecossistema open source de modelos da NVIDIA abrange biomedicina, IA física, modelos de agentes, robótica e direção autônoma Entre os destaques do discurso estão vários modelos open source da família NVIDIA Nemotron, incluindo voz, multimodalidade, geração aumentada por busca e segurança. Jensen também mencionou que os modelos open source Nemotron têm ótimo desempenho em vários rankings e estão sendo amplamente adotados por empresas. O que é IA física? Lançamento de dezenas de modelos de uma só vez Se os grandes modelos de linguagem resolvem problemas do “mundo digital”, a próxima ambição da NVIDIA é conquistar o “mundo físico”. Jensen mencionou que, para que a IA entenda as leis da física e sobreviva no mundo real, os dados são extremamente escassos. Além dos modelos open source de agentes Nemotron, ele propôs a arquitetura central das “três computadoras” para construir uma IA física (Physical AI). 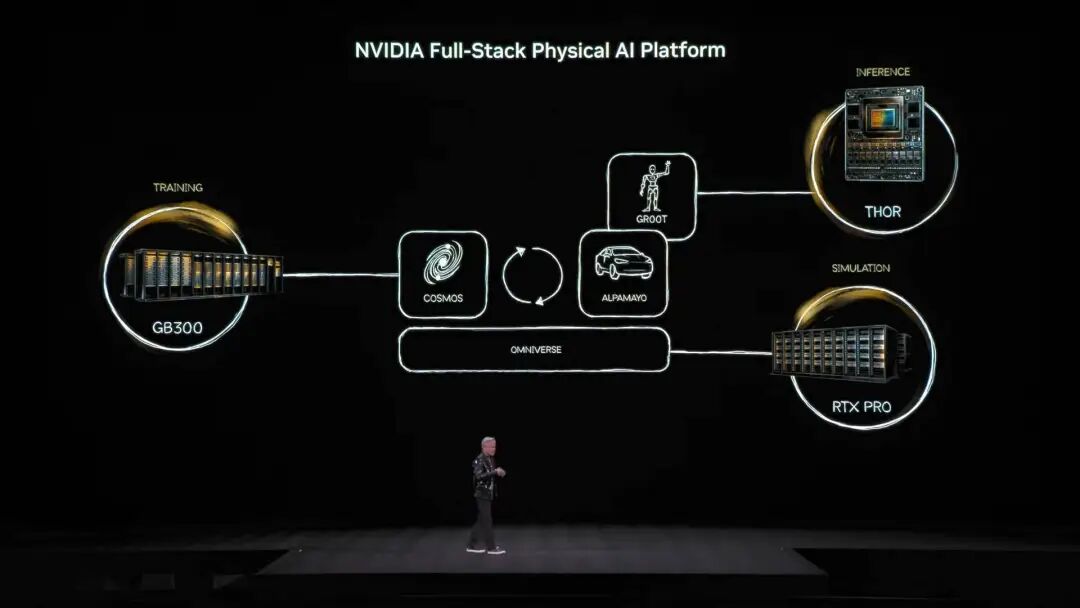
O computador de treinamento, que conhecemos, construído com placas de vídeo de nível de treinamento, como a arquitetura GB300 mencionada na imagem.
O computador de inferência, funcionando como o “cerebelo” na borda de robôs ou carros, responsável pela execução em tempo real.
O computador de simulação, incluindo Omniverse e Cosmos, fornece um ambiente virtual de treinamento para IA aprender feedback físico em simulação. O sistema Cosmos pode gerar uma enorme quantidade de ambientes de treinamento de IA do mundo físico Com base nessa arquitetura, Jensen Huang lançou oficialmente o impressionante Alpamayo, o primeiro modelo de direção autônoma do mundo com capacidade de pensar e raciocinar.
O sistema Cosmos pode gerar uma enorme quantidade de ambientes de treinamento de IA do mundo físico Com base nessa arquitetura, Jensen Huang lançou oficialmente o impressionante Alpamayo, o primeiro modelo de direção autônoma do mundo com capacidade de pensar e raciocinar.  Diferente da direção autônoma tradicional, Alpamayo é um sistema treinado de ponta a ponta. Sua inovação é resolver o “problema de cauda longa” da direção autônoma. Diante de situações complexas nunca vistas, Alpamayo não segue cegamente o código, mas raciocina como um motorista humano. “Ele te dirá o que fará em seguida e por que tomou tal decisão.” Na demonstração, o modo de direção do veículo foi impressionantemente natural, capaz de dividir cenários extremamente complexos em conhecimentos básicos para lidar. Além do demo, tudo isso não é teoria. Jensen anunciou que o Mercedes CLA com pilha tecnológica Alpamayo será lançado oficialmente este trimestre nos EUA, em breve chegando à Europa e Ásia.
Diferente da direção autônoma tradicional, Alpamayo é um sistema treinado de ponta a ponta. Sua inovação é resolver o “problema de cauda longa” da direção autônoma. Diante de situações complexas nunca vistas, Alpamayo não segue cegamente o código, mas raciocina como um motorista humano. “Ele te dirá o que fará em seguida e por que tomou tal decisão.” Na demonstração, o modo de direção do veículo foi impressionantemente natural, capaz de dividir cenários extremamente complexos em conhecimentos básicos para lidar. Além do demo, tudo isso não é teoria. Jensen anunciou que o Mercedes CLA com pilha tecnológica Alpamayo será lançado oficialmente este trimestre nos EUA, em breve chegando à Europa e Ásia.  Este carro foi classificado pelo NCAP como o mais seguro do mundo, graças ao exclusivo “dual safety stack” da NVIDIA. Quando o modelo de IA ponta a ponta não tem confiança suficiente na estrada, o sistema alterna imediatamente para o modo tradicional mais seguro, garantindo segurança total. Na apresentação, Jensen também mostrou a estratégia de robótica da NVIDIA.
Este carro foi classificado pelo NCAP como o mais seguro do mundo, graças ao exclusivo “dual safety stack” da NVIDIA. Quando o modelo de IA ponta a ponta não tem confiança suficiente na estrada, o sistema alterna imediatamente para o modo tradicional mais seguro, garantindo segurança total. Na apresentação, Jensen também mostrou a estratégia de robótica da NVIDIA. 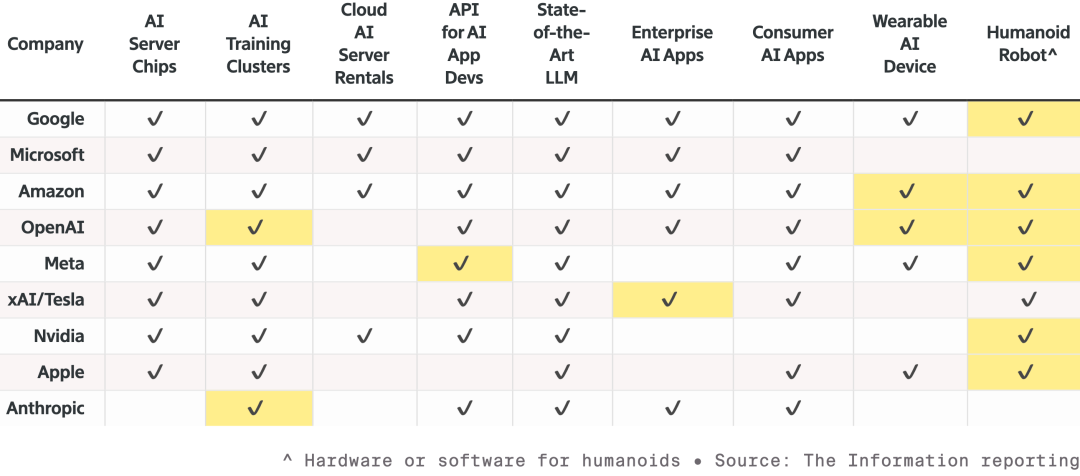 A competição entre nove principais fabricantes de IA e hardware, todos expandindo linhas de produtos e disputando espaço na robótica; células destacadas representam novos produtos desde o ano passado Todos os robôs contarão com computadores compactos Jetson, treinados no simulador Isaac da plataforma Omniverse. E a NVIDIA está integrando essa tecnologia nos sistemas industriais de Synopsys, Cadence, Siemens, entre outros.
A competição entre nove principais fabricantes de IA e hardware, todos expandindo linhas de produtos e disputando espaço na robótica; células destacadas representam novos produtos desde o ano passado Todos os robôs contarão com computadores compactos Jetson, treinados no simulador Isaac da plataforma Omniverse. E a NVIDIA está integrando essa tecnologia nos sistemas industriais de Synopsys, Cadence, Siemens, entre outros.  Jensen convidou ao palco robôs humanóides e quadrúpedes de empresas como Boston Dynamics e Agility, destacando que o maior robô é, na verdade, a própria fábrica De baixo para cima, a visão da NVIDIA é que, no futuro, design de chips, de sistemas e de fábricas serão acelerados por IA física da NVIDIA. No evento, mais uma vez robôs da Disney brilharam, e Jensen brincou com esses robôs fofíssimos: “Vocês serão projetados no computador, fabricados no computador e até testados e validados no computador antes de enfrentarem a gravidade real.”
Jensen convidou ao palco robôs humanóides e quadrúpedes de empresas como Boston Dynamics e Agility, destacando que o maior robô é, na verdade, a própria fábrica De baixo para cima, a visão da NVIDIA é que, no futuro, design de chips, de sistemas e de fábricas serão acelerados por IA física da NVIDIA. No evento, mais uma vez robôs da Disney brilharam, e Jensen brincou com esses robôs fofíssimos: “Vocês serão projetados no computador, fabricados no computador e até testados e validados no computador antes de enfrentarem a gravidade real.”  Se não soubéssemos que era Jensen Huang, poderíamos pensar que toda a apresentação era de uma fabricante de modelos de IA. No auge das discussões sobre uma possível bolha da IA e com a desaceleração da Lei de Moore, Jensen parece querer mostrar o que a IA realmente pode fazer, aumentando a confiança de todos em IA. Além de lançar a poderosa plataforma de supercomputação de IA Vera Rubin para saciar a fome por poder computacional, ele investiu mais do que nunca em aplicações e software, mostrando com todas as forças as mudanças concretas que a IA pode trazer. Assim como Jensen disse, no passado eles faziam chips para o mundo virtual, agora estão mostrando pessoalmente, focando em IA física representada por direção autônoma e robôs humanoides, entrando no competitivo mundo físico real. Afinal, só com a “guerra” em andamento, as armas continuam sendo vendidas. *Por fim, o vídeo bônus: Devido à limitação de tempo na apresentação da CES, Jensen não conseguiu apresentar muitos slides. Então ele fez um vídeo engraçado com os slides não exibidos. Confira⬇️
Se não soubéssemos que era Jensen Huang, poderíamos pensar que toda a apresentação era de uma fabricante de modelos de IA. No auge das discussões sobre uma possível bolha da IA e com a desaceleração da Lei de Moore, Jensen parece querer mostrar o que a IA realmente pode fazer, aumentando a confiança de todos em IA. Além de lançar a poderosa plataforma de supercomputação de IA Vera Rubin para saciar a fome por poder computacional, ele investiu mais do que nunca em aplicações e software, mostrando com todas as forças as mudanças concretas que a IA pode trazer. Assim como Jensen disse, no passado eles faziam chips para o mundo virtual, agora estão mostrando pessoalmente, focando em IA física representada por direção autônoma e robôs humanoides, entrando no competitivo mundo físico real. Afinal, só com a “guerra” em andamento, as armas continuam sendo vendidas. *Por fim, o vídeo bônus: Devido à limitação de tempo na apresentação da CES, Jensen não conseguiu apresentar muitos slides. Então ele fez um vídeo engraçado com os slides não exibidos. Confira⬇️ 
Diferente do ano passado, quando fez uma apresentação principal solo, em 2026 Jensen Huang teve uma agenda apertada. Do NVIDIA Live ao diálogo sobre IA industrial da Siemens, até o Lenovo TechWorld, ele participou de três eventos em 48 horas. Na última vez, ele lançou a série de placas de vídeo RTX 50 na CES. Desta vez, IA física, tecnologia robótica e uma “ bomba nuclear corporativa ” de 2,5 toneladas foram os verdadeiros protagonistas. Plataforma de computação Vera Rubin estreia, quanto mais compra, mais economiza Durante a apresentação, o sempre irreverente Jensen levou ao palco um rack de servidor de IA de 2,5 toneladas, introduzindo o ponto central do evento: a plataforma de computação Vera Rubin, nomeada em homenagem à astrônoma que descobriu a matéria escura, com um único objetivo: Acelerar a velocidade de treinamento de IA, antecipando a chegada da próxima geração de modelos. Normalmente, existe uma regra interna na NVIDIA: cada geração de produto altera no máximo 1-2 chips. Mas desta vez, a Vera Rubin rompeu com o padrão ao redesenhar seis chips de uma só vez, todos já em plena produção. A razão é que, com a desaceleração da Lei de Moore, os métodos tradicionais de aumento de desempenho não acompanham o crescimento anual de 10 vezes dos modelos de IA, então a NVIDIA optou por um “design de colaboração extrema”—inovando em todos os chips e em todos os níveis da plataforma ao mesmo tempo.
Estes seis chips são: 1. Vera CPU: - 88 núcleos Olympus personalizados pela NVIDIA - Tecnologia de multithreading espacial NVIDIA, suporta 176 threads - Largura de banda NVLink C2C de 1,8 TB/s - Memória do sistema de 1,5 TB (3 vezes a da Grace) - Largura de banda LPDDR5X de 1,2 TB/s - 227 bilhões de transistores 2. Rubin GPU: - Capacidade de inferência NVFP4 de 50 PFLOPS, 5 vezes a do Blackwell anterior - Possui 336 bilhões de transistores, 1,6 vezes mais que o Blackwell - Equipado com terceira geração do mecanismo Transformer, ajusta dinamicamente a precisão conforme as necessidades do modelo Transformer 3. Placa de rede ConnectX-9: - Ethernet de 800 Gb/s baseada em 200G PAM4 SerDes - RDMA programável e acelerador de caminho de dados - Certificação CNSA e FIPS - 23 bilhões de transistores 4. BlueField-4 DPU: - Motor de ponta a ponta construído especialmente para a nova geração de plataformas de armazenamento de IA - DPU de 800G Gb/s para SmartNIC e processadores de armazenamento - CPU Grace de 64 núcleos combinada com ConnectX-9 - 126 bilhões de transistores 5. Chip de troca NVLink-6: - Conecta 18 nós de computação, suporta até 72 Rubin GPUs rodando como um só conjunto - Na arquitetura NVLink 6, cada GPU pode obter largura de banda all-to-all de 3,6 TB por segundo - Utiliza 400G SerDes, suporta In-Network SHARP Collectives, podendo realizar operações coletivas dentro da rede de troca 6. Chip de troca óptica Spectrum-6 para Ethernet - 512 canais, 200 Gbps por canal, para transmissão de dados ainda mais rápida - Tecnologia de silício fotônico com processo COOP da TSMC - Interface óptica copackaged - 352 bilhões de transistores Com a integração profunda destes seis chips, o sistema Vera Rubin NVL72 teve uma melhoria abrangente de desempenho em relação à geração anterior Blackwell. Em tarefas de inferência NVFP4, este chip alcançou um poder de computação impressionante de 3,6 EFLOPS, cinco vezes o da arquitetura Blackwell anterior. Para treinamento NVFP4, o desempenho chega a 2,5 EFLOPS, um aumento de 3,5 vezes. No armazenamento, o NVL72 conta com 54TB de memória LPDDR5X, três vezes o do produto anterior. A capacidade de HBM (memória de alta largura de banda) chega a 20,7TB, um aumento de 1,5 vez. Em largura de banda, o HBM4 chega a 1,6 PB/s, aumento de 2,8 vezes; largura de banda Scale-Up chega a 260 TB/s, aumento de 2 vezes. Apesar de tanta melhoria de desempenho, a contagem de transistores subiu apenas 1,7 vez, para 220 trilhões, demonstrando inovação na tecnologia de fabricação de semicondutores. Na engenharia, a Vera Rubin também trouxe avanços técnicos. Antes, um nó de supercomputação precisava de 43 cabos, montagem levava duas horas e era fácil errar. Agora, o nó Vera Rubin usa zero cabos, apenas seis tubos de resfriamento líquido, montado em cinco minutos. Mais impressionante ainda, na parte de trás do rack há quase 3,2 km de cabos de cobre, 5.000 cabos formam a rede backbone NVLink, atingindo velocidade de 400Gbps. Como disse Jensen: “Talvez pese algumas centenas de libras, você precisa ser um CEO em boa forma para este trabalho”. No universo da IA, tempo é dinheiro. Um dado fundamental: para treinar um modelo de 10 trilhões de parâmetros, Rubin precisa de apenas 1/4 do número de sistemas Blackwell, e o custo para gerar um token é cerca de 1/10 do Blackwell. Além disso, embora o consumo de energia do Rubin seja o dobro do Grace Blackwell, o ganho de desempenho é muito maior: 5 vezes em inferência, 3,5 vezes em treinamento. Mais importante, o Rubin aumentou em 10 vezes a eficiência (tokens de IA por watt e por dólar) em relação ao Blackwell. Para um data center de gigawatts de US$ 50 bilhões, isso significa dobrar a capacidade de receita. No passado, o maior problema do setor de IA era a memória de contexto insuficiente. Quando a IA trabalha, ela gera “KV Cache” (cache de chave-valor), que é a “memória de trabalho” da IA. O problema é que à medida que as conversas aumentam e os modelos crescem, a memória HBM fica insuficiente. A NVIDIA lançou no ano passado a arquitetura Grace-Blackwell para expandir a memória, mas ainda não era suficiente. A solução Vera Rubin é implantar processadores BlueField-4 no rack, especialmente para gerenciar o KV Cache. Cada nó tem 4 BlueField-4, cada um com 150TB de memória de contexto, distribuída para as GPUs. Cada GPU recebe 16TB extras de memória—sendo que a memória nativa da GPU é de cerca de 1TB—e, crucialmente, a largura de banda permanece em 200Gbps, sem perda de velocidade. No entanto, apenas capacidade não basta: para que “post-its” distribuídos em dezenas de racks e milhares de GPUs ajam como uma única memória, a rede precisa ser “grande, rápida e estável”. É aqui que entra o Spectrum-X. Spectrum-X é a primeira plataforma de rede Ethernet de ponta a ponta do mundo “projetada para IA generativa”, trazendo a mais recente geração com processo COOP da TSMC, tecnologia de silício fotônico, 512 canais × 200Gbps. Jensen fez as contas: um data center de gigawatts custa US$ 50 bilhões, Spectrum-X pode aumentar a produtividade em 25%, economizando US$ 5 bilhões. “Você pode dizer que este sistema de rede é quase ‘de graça’.” Em segurança, o Vera Rubin também suporta Computação Confidencial. Todos os dados são criptografados durante transmissão, armazenamento e processamento, incluindo todos os barramentos como PCIe, NVLink e comunicação CPU-GPU. As empresas podem implantar seus modelos em sistemas externos sem medo de vazamento de dados. DeepSeek surpreendeu o mundo, open source e agentes são o mainstream da IA Depois do prato principal, voltamos ao início do discurso. Jensen Huang abriu com um número impressionante: cerca de US$ 10 trilhões em recursos computacionais investidos na última década estão sendo totalmente modernizados. Mas não é apenas uma atualização de hardware, é mais sobre uma mudança de paradigma de software. Ele destacou especialmente os modelos de agentes com capacidade de agir de forma autônoma, mencionando o Cursor, que mudou completamente a forma de programar dentro da NVIDIA. O que mais empolgou a plateia foi seu alto elogio à comunidade open source. Jensen afirmou que o avanço do DeepSeek V1 no ano passado surpreendeu o mundo; como o primeiro sistema de inferência open source, impulsionou toda a indústria. No slide, vemos os conhecidos players chineses Kimi k2 e DeepSeek V3.2 ocupando o primeiro e segundo lugar em open source. Jensen acredita que, embora os modelos open source estejam atualmente cerca de seis meses atrás dos mais avançados, um novo modelo aparece a cada seis meses. Essa velocidade de iteração faz com que startups, gigantes e pesquisadores não queiram ficar de fora, incluindo a própria NVIDIA. Por isso, desta vez não venderam apenas “pás” e placas de vídeo; a NVIDIA construiu o supercomputador DGX Cloud, valendo bilhões de dólares, e desenvolveu modelos de ponta como La Proteina (síntese de proteínas) e OpenFold 3. O ecossistema open source de modelos da NVIDIA abrange biomedicina, IA física, modelos de agentes, robótica e direção autônoma Entre os destaques do discurso estão vários modelos open source da família NVIDIA Nemotron, incluindo voz, multimodalidade, geração aumentada por busca e segurança. Jensen também mencionou que os modelos open source Nemotron têm ótimo desempenho em vários rankings e estão sendo amplamente adotados por empresas. O que é IA física? Lançamento de dezenas de modelos de uma só vez Se os grandes modelos de linguagem resolvem problemas do “mundo digital”, a próxima ambição da NVIDIA é conquistar o “mundo físico”. Jensen mencionou que, para que a IA entenda as leis da física e sobreviva no mundo real, os dados são extremamente escassos. Além dos modelos open source de agentes Nemotron, ele propôs a arquitetura central das “três computadoras” para construir uma IA física (Physical AI). O computador de treinamento, que conhecemos, construído com placas de vídeo de nível de treinamento, como a arquitetura GB300 mencionada na imagem.
O computador de inferência, funcionando como o “cerebelo” na borda de robôs ou carros, responsável pela execução em tempo real.
O computador de simulação, incluindo Omniverse e Cosmos, fornece um ambiente virtual de treinamento para IA aprender feedback físico em simulação.
O sistema Cosmos pode gerar uma enorme quantidade de ambientes de treinamento de IA do mundo físico Com base nessa arquitetura, Jensen Huang lançou oficialmente o impressionante Alpamayo, o primeiro modelo de direção autônoma do mundo com capacidade de pensar e raciocinar. Diferente da direção autônoma tradicional, Alpamayo é um sistema treinado de ponta a ponta. Sua inovação é resolver o “problema de cauda longa” da direção autônoma. Diante de situações complexas nunca vistas, Alpamayo não segue cegamente o código, mas raciocina como um motorista humano. “Ele te dirá o que fará em seguida e por que tomou tal decisão.” Na demonstração, o modo de direção do veículo foi impressionantemente natural, capaz de dividir cenários extremamente complexos em conhecimentos básicos para lidar. Além do demo, tudo isso não é teoria. Jensen anunciou que o Mercedes CLA com pilha tecnológica Alpamayo será lançado oficialmente este trimestre nos EUA, em breve chegando à Europa e Ásia. Este carro foi classificado pelo NCAP como o mais seguro do mundo, graças ao exclusivo “dual safety stack” da NVIDIA. Quando o modelo de IA ponta a ponta não tem confiança suficiente na estrada, o sistema alterna imediatamente para o modo tradicional mais seguro, garantindo segurança total. Na apresentação, Jensen também mostrou a estratégia de robótica da NVIDIA. A competição entre nove principais fabricantes de IA e hardware, todos expandindo linhas de produtos e disputando espaço na robótica; células destacadas representam novos produtos desde o ano passado Todos os robôs contarão com computadores compactos Jetson, treinados no simulador Isaac da plataforma Omniverse. E a NVIDIA está integrando essa tecnologia nos sistemas industriais de Synopsys, Cadence, Siemens, entre outros. Jensen convidou ao palco robôs humanóides e quadrúpedes de empresas como Boston Dynamics e Agility, destacando que o maior robô é, na verdade, a própria fábrica De baixo para cima, a visão da NVIDIA é que, no futuro, design de chips, de sistemas e de fábricas serão acelerados por IA física da NVIDIA. No evento, mais uma vez robôs da Disney brilharam, e Jensen brincou com esses robôs fofíssimos: “Vocês serão projetados no computador, fabricados no computador e até testados e validados no computador antes de enfrentarem a gravidade real.” Se não soubéssemos que era Jensen Huang, poderíamos pensar que toda a apresentação era de uma fabricante de modelos de IA. No auge das discussões sobre uma possível bolha da IA e com a desaceleração da Lei de Moore, Jensen parece querer mostrar o que a IA realmente pode fazer, aumentando a confiança de todos em IA. Além de lançar a poderosa plataforma de supercomputação de IA Vera Rubin para saciar a fome por poder computacional, ele investiu mais do que nunca em aplicações e software, mostrando com todas as forças as mudanças concretas que a IA pode trazer. Assim como Jensen disse, no passado eles faziam chips para o mundo virtual, agora estão mostrando pessoalmente, focando em IA física representada por direção autônoma e robôs humanoides, entrando no competitivo mundo físico real. Afinal, só com a “guerra” em andamento, as armas continuam sendo vendidas. *Por fim, o vídeo bônus: Devido à limitação de tempo na apresentação da CES, Jensen não conseguiu apresentar muitos slides. Então ele fez um vídeo engraçado com os slides não exibidos. Confira⬇️ 0
0
Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
PoolX: bloqueie e ganhe!
Até 10% de APR - Quanto mais você bloquear, mais poderá ganhar.
Bloquear agora!
Talvez também goste
Vitalik Buterin provoca debate sobre a maior ameaça das criptomoedas
Cointurk•2026/01/11 08:14
Os Bitcoin Maxis estavam certos: Por que rejeitar ICOs para combater o “Corposlop”?
CoinEdition•2026/01/11 07:07
Robinhood reinveste em blockchain para impulsionar a infraestrutura cripto
Cointurk•2026/01/11 07:04
Populares
MaisPreços de criptomoedas
MaisBitcoin
BTC
$90,587.93
+0.06%
Ethereum
ETH
$3,090.99
+0.08%
Tether USDt
USDT
$0.9986
+0.01%
XRP
XRP
$2.09
-0.33%
BNB
BNB
$912.73
+0.91%
Solana
SOL
$136
+0.06%
USDC
USDC
$0.9996
-0.01%
TRON
TRX
$0.2987
+0.30%
Dogecoin
DOGE
$0.1398
-0.25%
Cardano
ADA
$0.3907
+0.82%
Como vender PI
Listagem de PI na Bitget: compre ou venda PI com rapidez!
Operar agora
Ainda não é um Bitgetter?Pacote de boas-vindas de 6.200 USDT para novos usuários!
Criar conta