Em resumo
- DeepSeek V4 pode ser lançado em poucas semanas, visando desempenho de codificação em nível de elite.
- Fontes internas afirmam que pode superar Claude e ChatGPT em tarefas de código com contexto longo.
- Desenvolvedores já estão empolgados diante de uma possível disrupção.
Segundo relatos, a DeepSeek planeja lançar seu modelo V4 por volta de meados de fevereiro e, se os testes internos forem um indicativo, os gigantes da IA do Vale do Silício têm motivos para ficarem preocupados.
A startup de IA sediada em Hangzhou pode estar mirando um lançamento por volta de 17 de fevereiro—Ano Novo Lunar, naturalmente—com um modelo especificamente projetado para tarefas de codificação, de acordo com
. Pessoas com conhecimento direto do projeto afirmam que o V4 supera tanto o Claude da Anthropic quanto a série GPT da OpenAI nos testes internos, especialmente ao lidar com prompts de código extremamente longos.
Claro, nenhum benchmark ou informação sobre o modelo foi compartilhado publicamente, então é impossível verificar tais afirmações diretamente. A DeepSeek também não confirmou os rumores.
Mesmo assim, a comunidade de desenvolvedores não está esperando uma palavra oficial. Os fóruns r/DeepSeek e r/LocalLLaMA do Reddit já estão esquentando, usuários estão acumulando créditos de API, e entusiastas no X têm compartilhado rapidamente previsões de que o V4 pode consolidar a posição da DeepSeek como o azarão rebelde que se recusa a jogar segundo as regras bilionárias do Vale do Silício.
A Anthropic bloqueou assinantes do Claude em aplicativos de terceiros como OpenCode, e supostamente cortou o acesso da xAI e OpenAI.
Claude e Claude Code são ótimos, mas ainda não são 10x melhores. Isso só vai estimular outros laboratórios a avançarem mais rápido em seus modelos/agentes de codificação.
O DeepSeek V4 está com lançamento previsto...
— Yuchen Jin (@Yuchenj_UW) 9 de janeiro de 2026
Essa não seria a primeira disrupção da DeepSeek. Quando a empresa lançou seu modelo de raciocínio R1 em janeiro de 2025, provocou uma liquidação de US$ 1 trilhão nos mercados globais.
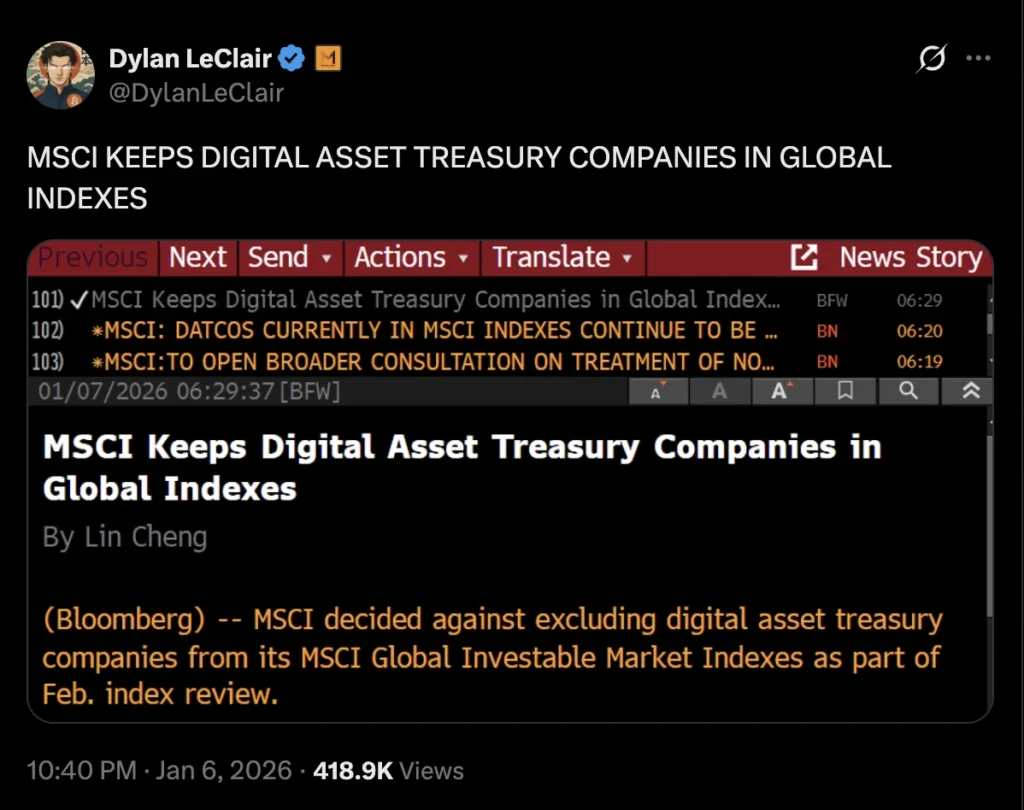
O motivo? O R1 da DeepSeek igualou o modelo o1 da OpenAI em benchmarks de matemática e raciocínio, apesar de supostamente ter custado apenas US$ 6 milhões para ser desenvolvido—aproximadamente 68 vezes mais barato do que o gasto pelos concorrentes. Seu modelo V3 posteriormente atingiu 90,2% no benchmark MATH-500, ultrapassando os 78,3% do Claude, e a recente atualização “V3.2 Speciale” elevou ainda mais esse desempenho.
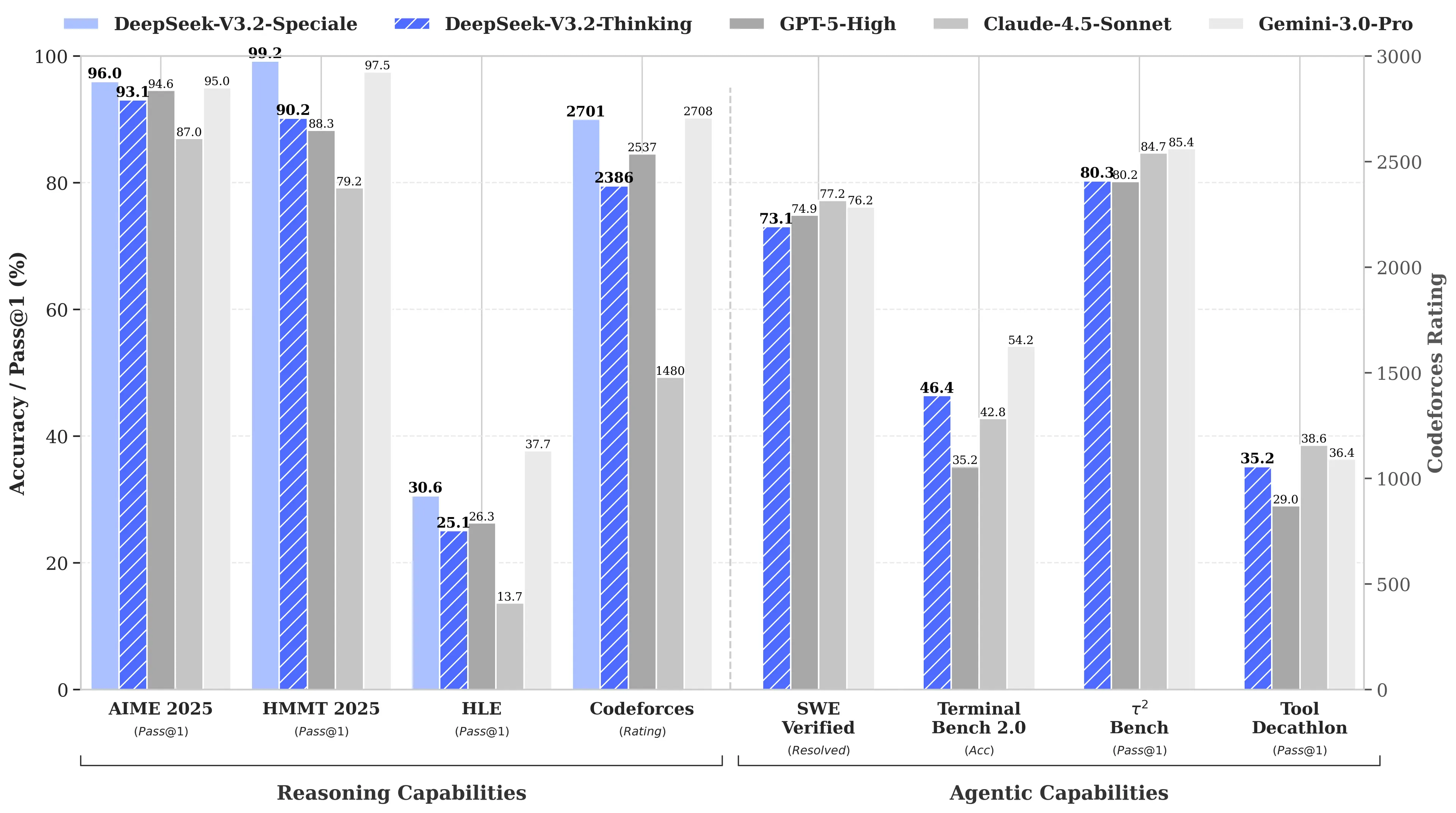
Imagem: DeepSeek
O foco em codificação do V4 seria uma mudança estratégica. Enquanto o R1 enfatizava puro raciocínio—lógica, matemática, provas formais—o V4 é um modelo híbrido (tarefas de raciocínio e não raciocínio) que mira o mercado de desenvolvedores corporativos onde geração de código com alta precisão se traduz diretamente em receita.
Para reivindicar a liderança, o V4 teria que superar o Claude Opus 4.5, que atualmente detém o recorde do SWE-bench Verified com 80,9%. Mas se os lançamentos anteriores da DeepSeek servirem de guia, isso pode não ser impossível de alcançar mesmo com todas as restrições que um laboratório de IA chinês enfrenta.
O segredo nada secreto
Assumindo que os rumores sejam verdadeiros, como esse pequeno laboratório pode alcançar tal feito?
A arma secreta da empresa pode estar contida em seu artigo científico de 1º de janeiro: Manifold-Constrained Hyper-Connections, ou mHC. Coautorado pelo fundador Liang Wenfeng, o novo método de treinamento aborda um problema fundamental ao escalar grandes modelos de linguagem—como expandir a capacidade de um modelo sem que ele se torne instável ou entre em colapso durante o treinamento.
Arquiteturas tradicionais de IA forçam toda a informação por um único caminho estreito. O mHC amplia esse caminho em vários fluxos que podem trocar informações sem causar colapso no treinamento.
Imagem: DeepSeek
Wei Sun, analista principal de IA na Counterpoint Research, chamou o mHC de "avanço impressionante" em comentários para
. A técnica, segundo ela, mostra que a DeepSeek pode "contornar gargalos computacionais e desbloquear avanços em inteligência", mesmo com acesso limitado a chips avançados devido a restrições de exportação dos EUA.
Lian Jye Su, analista-chefe da Omdia, destacou que a disposição da DeepSeek em publicar seus métodos sinaliza uma "nova confiança adquirida na indústria chinesa de IA." A abordagem open source da empresa a tornou favorita entre desenvolvedores que a veem como representação do que a OpenAI costumava ser, antes de migrar para modelos fechados e rodadas de captação bilionárias.
Nem todos estão convencidos. Alguns desenvolvedores no Reddit reclamam que os modelos de raciocínio da DeepSeek desperdiçam recursos computacionais em tarefas simples, enquanto críticos argumentam que os benchmarks da empresa não refletem a complexidade do mundo real. Um post no Medium intitulado "DeepSeek é ruim—e eu parei de fingir que não é" viralizou em abril de 2025, acusando os modelos de produzirem "códigos genéricos cheios de bugs" e "bibliotecas alucinadas".
A DeepSeek também carrega um histórico problemático. Preocupações com privacidade têm perseguido a empresa, com alguns governos banindo o aplicativo nativo da DeepSeek. Os laços da empresa com a China e dúvidas sobre censura em seus modelos adicionam fricção geopolítica aos debates técnicos.
Ainda assim, o ímpeto é inegável. A DeepSeek tem sido amplamente adotada na Ásia, e se o V4 cumprir suas promessas em codificação, a adoção corporativa no Ocidente pode ser o próximo passo.
Imagem: Microsoft
Há também a questão do timing. Segundo
, a DeepSeek originalmente planejava lançar seu modelo R2 em maio de 2025, mas estendeu o prazo depois que o fundador Liang ficou insatisfeito com seu desempenho. Agora, com o V4 supostamente mirando fevereiro e o R2 possivelmente vindo em agosto, a empresa se move num ritmo que sugere urgência—ou confiança. Talvez ambos.