Кратко
- DeepSeek V4 может выйти в течение нескольких недель, нацеливаясь на элитный уровень производительности в программировании.
- Инсайдеры утверждают, что она может обойти Claude и ChatGPT в задачах с длинным контекстом кода.
- Разработчики уже в предвкушении возможной революции.
Сообщается, что DeepSeek планирует выпустить свою модель V4 примерно в середине февраля, и если внутренние тесты что-то значат, гиганты искусственного интеллекта из Кремниевой долины должны быть настороже.
Стартап в сфере искусственного интеллекта из Ханчжоу может нацеливаться на запуск около 17 февраля — разумеется, в праздник Лунного Нового года — с моделью, специально предназначенной для задач программирования, согласно
. Люди, непосредственно знакомые с проектом, утверждают, что V4 превосходит как Claude от Anthropic, так и серию GPT от OpenAI во внутренних тестах, особенно при работе с чрезвычайно длинными запросами кода.
Конечно, никаких тестов или информации о модели публично не представлено, так что такие заявления невозможно напрямую проверить. DeepSeek также не подтверждала эти слухи.
Тем не менее, сообщество разработчиков не ждет официальных заявлений. На Reddit в r/DeepSeek и r/LocalLLaMA уже растет активность, пользователи закупают кредиты API, а энтузиасты в X активно делятся прогнозами, что V4 может закрепить за DeepSeek статус дерзкого «андердога», который отказывается играть по миллиардным правилам Кремниевой долины.
Anthropic заблокировала подписки Claude в сторонних приложениях, таких как OpenCode, и, по сообщениям, прекратила доступ для xAI и OpenAI.
Claude и Claude Code отличные, но пока не в 10 раз лучше. Это только подтолкнет другие лаборатории ускорить работу над своими моделями/агентами для программирования.
Ожидается выход DeepSeek V4…
— Yuchen Jin (@Yuchenj_UW) 9 января 2026
Это не первая встряска от DeepSeek. Когда компания выпустила свою модель рассуждений R1 в январе 2025 года, это спровоцировало распродажу на мировых рынках на сумму $1 трлн.
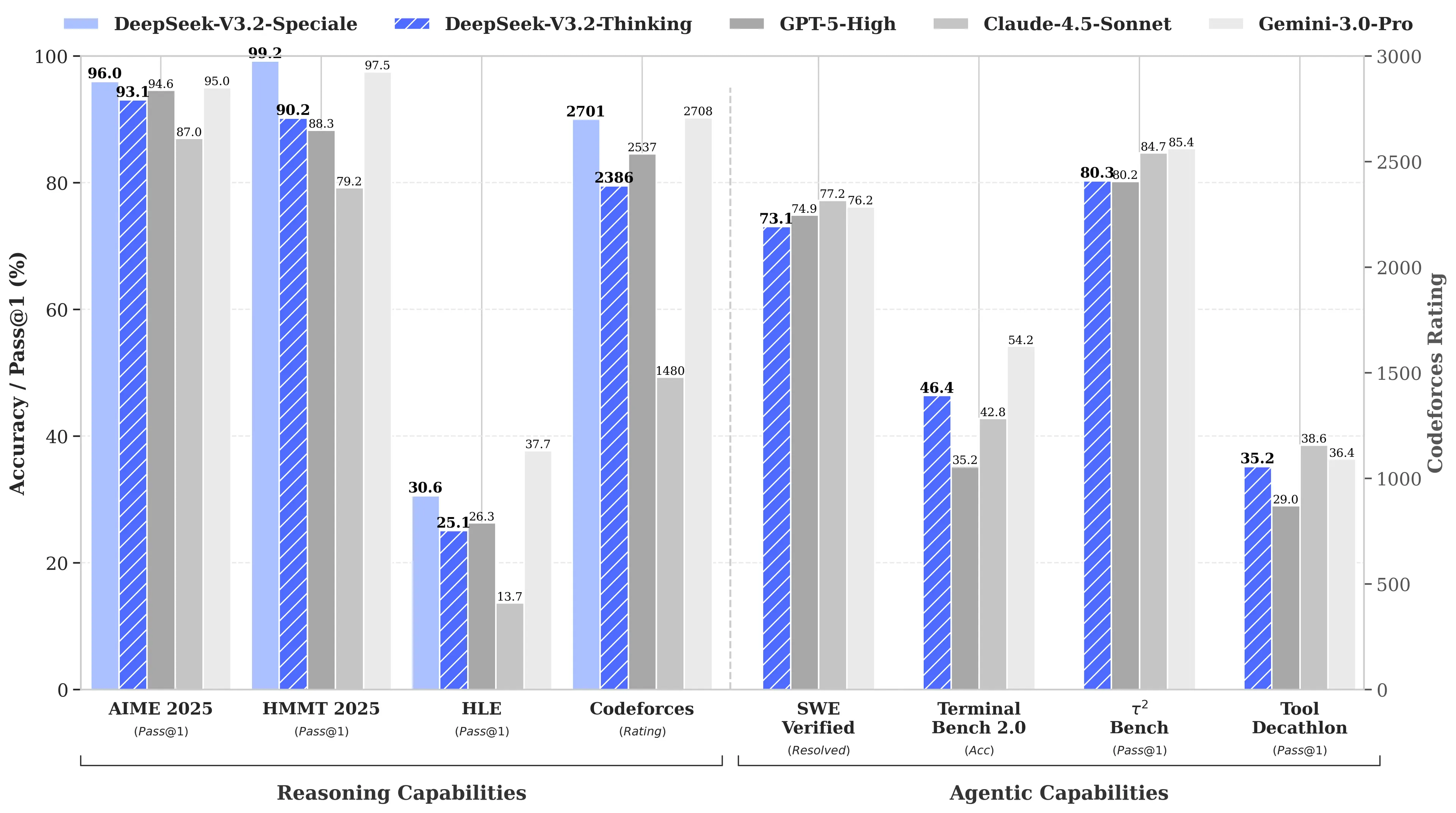
Причина? Модель R1 от DeepSeek показала такие же результаты на тестах по математике и логике, как и модель o1 от OpenAI, при том что на ее разработку было потрачено всего $6 млн — примерно в 68 раз дешевле, чем у конкурентов. Позже модель V3 набрала 90,2% на тесте MATH-500, опередив результат Claude (78,3%), а недавнее обновление “V3.2 Speciale” еще больше улучшило производительность.
Изображение: DeepSeek
Фокус V4 на программировании — это стратегический поворот. Если R1 делал ставку на чистое рассуждение — логику, математику, формальные доказательства — то V4 представляет собой гибридную модель (рассуждения и нерассуждающие задачи), нацеленную на корпоративный рынок разработчиков, где высокая точность генерации кода напрямую связана с доходом.
Чтобы заявить о лидерстве, V4 нужно превзойти Claude Opus 4.5, который сейчас удерживает рекорд SWE-bench Verified с показателем 80,9%. Но если судить по предыдущим релизам DeepSeek, то достичь этого вполне реально, несмотря на все ограничения, с которыми сталкивается китайская лаборатория ИИ.
Не такой уж секретный ингредиент
Если слухи верны, как маленькая лаборатория смогла добиться такого результата?
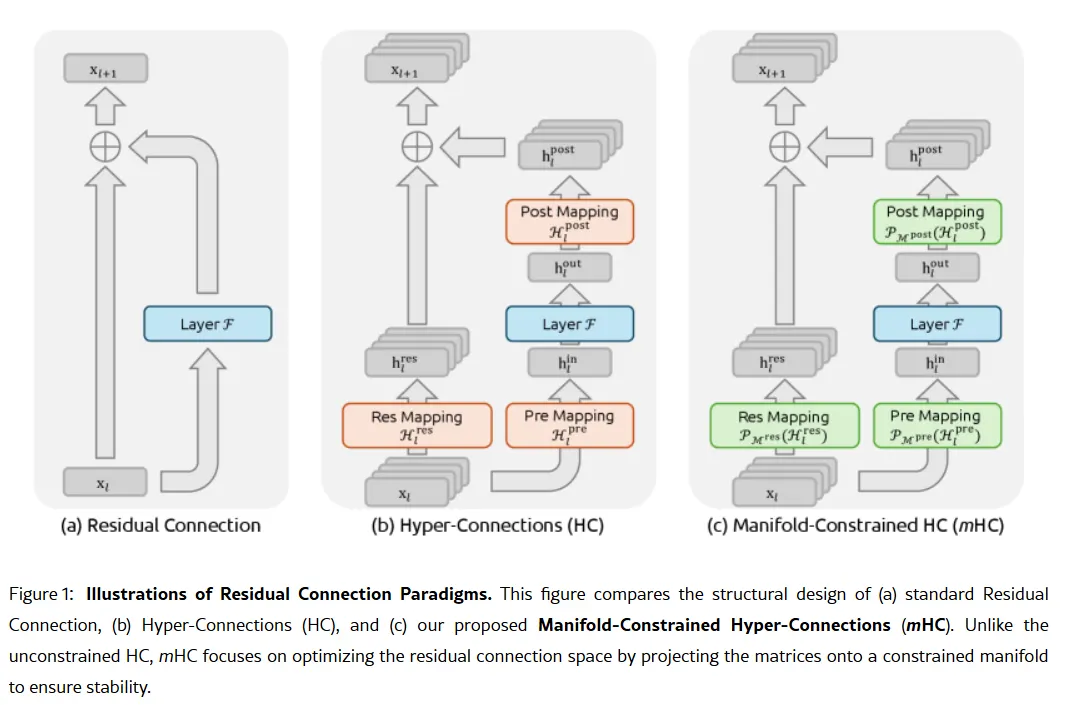
Секретным оружием компании, возможно, стало исследование, опубликованное 1 января: Manifold-Constrained Hyper-Connections, или mHC. Соавтором является основатель Лян Вэньфэн. Новый метод обучения решает фундаментальную проблему масштабирования больших языковых моделей — как расширить возможности модели, не делая ее нестабильной или склонной к "взрыву" во время тренировки.
Традиционные архитектуры ИИ заставляют всю информацию проходить через единственный узкий канал. mHC расширяет этот канал до нескольких потоков, которые могут обмениваться информацией, не вызывая сбоев в обучении.
Изображение: DeepSeek
Вэй Сунь, главный аналитик по ИИ в Counterpoint Research, назвала mHC «поразительным прорывом» в комментариях для
. По ее словам, эта технология показывает, что DeepSeek может «обходить вычислительные ограничения и совершать скачки в интеллекте», даже при ограниченном доступе к продвинутым чипам из-за экспортных ограничений США.
Лян Цзе Су, главный аналитик Omdia, отметил, что стремление DeepSeek публиковать свои методы говорит о «новой уверенности китайской ИИ-индустрии». Открытый подход компании сделал ее любимицей среди разработчиков, которые видят в ней воплощение того, чем некогда был OpenAI, до перехода к закрытым моделям и миллиардным инвестициям.
Однако не все убеждены. Некоторые разработчики на Reddit жалуются, что модели рассуждений DeepSeek тратят вычислительные ресурсы на простые задачи, а критики утверждают, что тесты компании не отражают реальных условий. Один из постов на Medium под названием "DeepSeek Sucks — And I'm Done Pretending It Doesn't" стал вирусным в апреле 2025 года, обвиняя модели в генерации «шаблонного бреда с багами» и «придуманных библиотек».
У DeepSeek также есть свои проблемы. Вопросы конфиденциальности преследуют компанию: некоторые правительства уже запретили родное приложение DeepSeek. Связи компании с Китаем и вопросы о цензуре в ее моделях добавляют геополитического напряжения к техническим спорам.
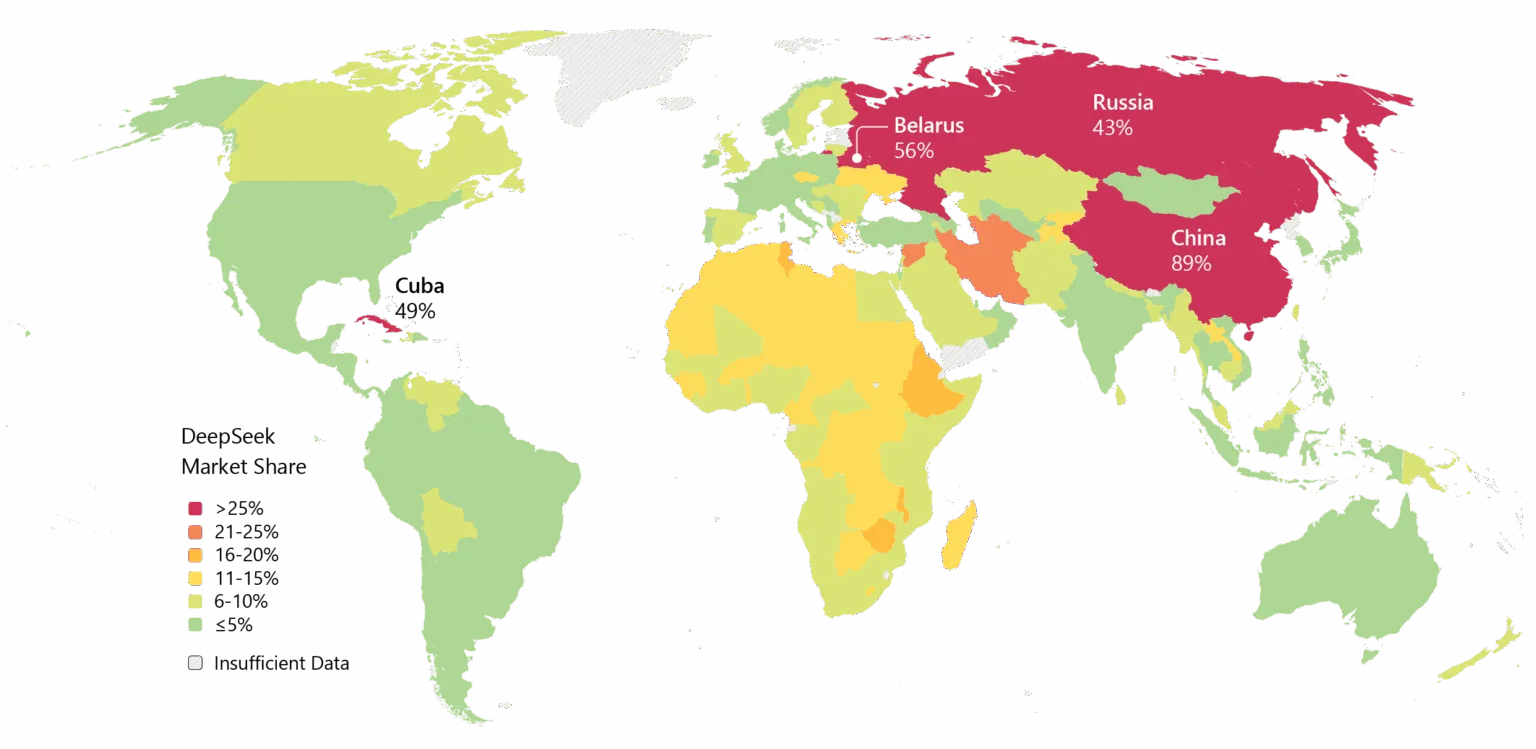
Тем не менее, инерция очевидна. DeepSeek широко используется в Азии, и если V4 оправдает ожидания в программировании, то корпоративное внедрение на Западе вполне возможно.
Изображение: Microsoft
Есть еще и фактор времени. Согласно
, изначально DeepSeek планировала выпустить модель R2 в мае 2025 года, но продлила сроки после того, как основатель Лян остался недоволен ее результатами. Теперь, когда V4 предположительно нацелена на февраль, а R2 может выйти в августе, компания двигается с такой скоростью, что это говорит либо о срочности, либо об уверенности. А может, и о том, и о другом.

