
Vitalik: нова концепція архітектури glue та coprocessor для підвищення ефективності та безпеки

З'єднувачі повинні бути оптимізовані для того, щоб бути хорошими з'єднувачами, а співпроцесори — для того, щоб бути хорошими співпроцесорами.
Клей має бути оптимізований для того, щоб бути хорошим клеєм, а співпроцесор — для того, щоб бути хорошим співпроцесором.
Оригінальна назва: «Glue and coprocessor architectures»
Автор: Vitalik Buterin, засновник Ethereum
Переклад: Deng Tong, Jinse Finance
Особлива подяка Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra та різним учасникам Flashbots за відгуки та коментарі.
Якщо ви з середнім рівнем деталізації проаналізуєте будь-які ресурсоємні обчислення в сучасному світі, ви знову і знову виявите одну особливість: обчислення можна розділити на дві частини:
- Відносно невелика кількість складної, але не надто ресурсоємної «бізнес-логіки»;
- Велика кількість інтенсивної, але високо структурованої «дорогої роботи».
Ці дві форми обчислень найкраще обробляти по-різному: перша може бути менш ефективною, але вимагає дуже високої універсальності; друга може бути менш універсальною, але повинна бути дуже ефективною.
Які приклади такого підходу існують на практиці?
Спочатку давайте розглянемо середовище, з яким я найбільше знайомий: Ethereum Virtual Machine (EVM). Ось нещодавній geth debug trace моєї транзакції в Ethereum: оновлення IPFS-хешу мого блогу на ENS. Ця транзакція спожила загалом 46924 gas, які можна класифікувати наступним чином:
- Базова вартість: 21,000
- Дані виклику: 1,556
- Виконання EVM: 24,368
- Операційний код SLOAD: 6,400
- Операційний код SSTORE: 10,100
- Операційний код LOG: 2,149
- Інше: 6,719

Трасування EVM для оновлення ENS-хешу. Передостанній стовпець — споживання gas.
Мораль цієї історії: більшість виконання (якщо брати лише EVM — близько 73%, якщо враховувати базову вартість, що покриває обчислення — близько 85%) зосереджена на дуже невеликій кількості структурованих дорогих операцій: читання та запис у сховище, логування та криптографія (базова вартість включає 3000 для оплати перевірки підпису, EVM також включає 272 для оплати хешування). Решта виконання — це «бізнес-логіка»: перестановка calldata для отримання ID запису, який я намагаюся встановити, і хешу, на який я його встановлюю, тощо. У токен-трансферах це включає додавання та віднімання балансів, у більш складних додатках це можуть бути цикли тощо.
У EVM ці дві форми виконання обробляються по-різному. Вища бізнес-логіка пишеться на більш високорівневих мовах, зазвичай Solidity, яка компілюється у EVM. Дорога робота все ще викликається через EVM-операційні коди (SLOAD тощо), але понад 99% фактичних обчислень виконується у спеціалізованих модулях, написаних безпосередньо у коді клієнта (або навіть у бібліотеках).
Щоб краще зрозуміти цю модель, давайте розглянемо інший контекст: AI-код, написаний на Python із використанням torch.
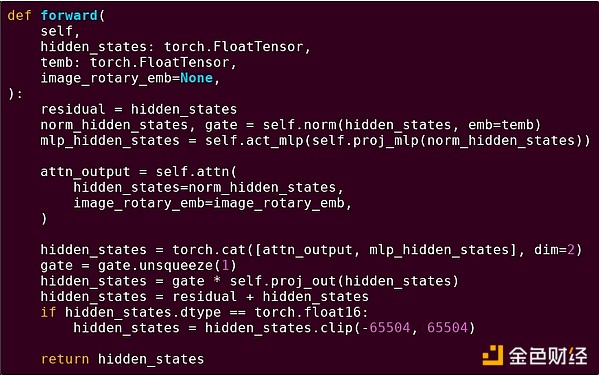
Пряме проходження одного блоку трансформерної моделі
Що ми тут бачимо? Ми бачимо відносно невелику кількість «бізнес-логіки», написаної на Python, яка описує структуру виконуваних операцій. На практиці буде ще один тип бізнес-логіки, який визначає такі деталі, як отримання вхідних даних і обробка вихідних. Але якщо ми заглибимося у кожну окрему операцію (self.norm, torch.cat, +, *, окремі кроки всередині self.attn...), ми побачимо векторизовані обчислення: одна й та сама операція паралельно виконується над великою кількістю значень. Як і в першому прикладі, невелика частина обчислень йде на бізнес-логіку, а основна частина — на виконання великих структурованих матричних і векторних операцій — насправді, здебільшого це просто множення матриць.
Як і у прикладі з EVM, ці два типи роботи обробляються по-різному. Вища бізнес-логіка пишеться на Python — це дуже універсальна і гнучка мова, але дуже повільна, і ми просто приймаємо неефективність, бо вона стосується лише невеликої частини загальних обчислювальних витрат. Тим часом інтенсивні операції пишуться на високо оптимізованому коді, зазвичай CUDA-коді, що виконується на GPU. Ми навіть дедалі частіше бачимо, як LLM-inference виконується на ASIC.
Сучасна програмована криптографія, така як SNARK, знову дотримується подібної моделі на двох рівнях. По-перше, доказувач може бути написаний на високорівневій мові, де важка робота виконується через векторизовані операції, як у наведеному вище AI-прикладі. Мій круговий STARK-код демонструє це. По-друге, сама програма, що виконується всередині криптографії, може бути написана так, щоб розділятися між універсальною бізнес-логікою та високо структурованою дорогою роботою.
Щоб зрозуміти, як це працює, можна подивитися на одну з останніх тенденцій у STARK-доказах. Для універсальності та зручності команди дедалі частіше створюють STARK-доказувачі для широко використовуваних мінімальних віртуальних машин, таких як RISC-V. Будь-яка програма, яку потрібно довести, може бути скомпільована у RISC-V, а доказувач може довести виконання цього коду на RISC-V.
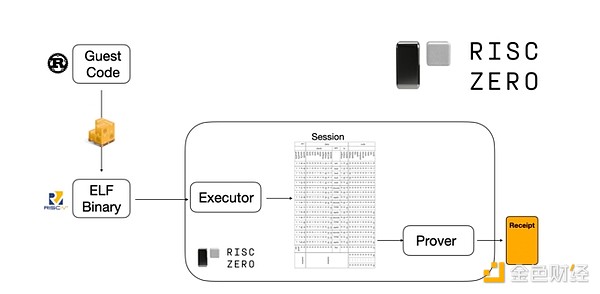
Діаграма з документації RiscZero
Це дуже зручно: це означає, що нам потрібно написати логіку доказу лише один раз, і з того моменту будь-яку програму, яку потрібно довести, можна написати на будь-якій «традиційній» мові програмування (наприклад, RiskZero підтримує Rust). Але є проблема: цей підхід створює великі накладні витрати. Програмована криптографія вже дуже дорога; додавання накладних витрат на виконання коду в інтерпретаторі RISC-V — це занадто багато. Тому розробники вигадали хитрість: визначити конкретні дорогі операції, які складають більшу частину обчислень (зазвичай це хешування та підписи), а потім створити спеціалізовані модулі для дуже ефективного доведення цих операцій. Потім ви просто комбінуєте неефективну, але універсальну систему доказів RISC-V із ефективною, але спеціалізованою системою доказів — і отримуєте найкраще з обох світів.
Крім ZK-SNARK, програмована криптографія, така як багатосторонні обчислення (MPC) та повністю гомоморфне шифрування (FHE), також може бути оптимізована подібним чином.
Яке загальне явище?
Сучасні обчислення дедалі більше дотримуються того, що я називаю архітектурою клею та співпроцесора: у вас є центральний «клейовий» компонент, який має високу універсальність, але низьку ефективність, і відповідає за передачу даних між одним або кількома співпроцесорними компонентами, які мають низьку універсальність, але високу ефективність.
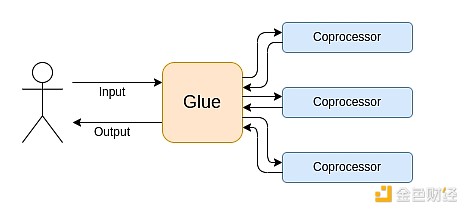
Це спрощення: на практиці компроміс між ефективністю та універсальністю майже завжди має більше ніж два рівні. GPU та інші чипи, які в індустрії зазвичай називають «співпроцесорами», менш універсальні, ніж CPU, але універсальніші, ніж ASIC. Компроміси спеціалізації складні й залежать від прогнозів і інтуїції щодо того, які частини алгоритму залишаться незмінними через п’ять років, а які зміняться через шість місяців. У ZK-доказових архітектурах ми часто бачимо подібну багаторівневу спеціалізацію. Але для широкої моделі мислення достатньо розглядати два рівні. У багатьох обчислювальних сферах спостерігається подібна ситуація:
З наведених вище прикладів видно, що обчислення дійсно можна розділити таким чином, і це здається природним законом. Насправді, ви можете знайти приклади спеціалізації обчислень за десятки років. Однак, я вважаю, що це розділення зростає. І на це є причини:
Ми лише нещодавно досягли межі підвищення тактової частоти CPU, тому подальші вигоди можливі лише через паралелізацію. Але паралелізація складна для розуміння, тому для розробників практичніше мислити послідовно і дозволити паралелізації відбуватися на бекенді, обгорнутій у спеціалізовані модулі для конкретних операцій.
Швидкість обчислень лише нещодавно стала настільки високою, що вартість обчислень бізнес-логіки стала дійсно незначною. У такому світі оптимізація VM для виконання бізнес-логіки з метою, відмінною від ефективності, також має сенс: зручність для розробників, знайомість, безпека та інші подібні цілі. Тим часом спеціалізовані модулі «співпроцесорів» можуть і далі проектуватися для ефективності, отримуючи свою безпеку та зручність для розробників із відносно простого «інтерфейсу» з клеєм.
Стає дедалі зрозуміліше, які саме операції є найдорожчими. Це найбільш очевидно в криптографії, де найбільш ймовірно використовуються певні типи дорогих операцій: модульні обчислення, лінійні комбінації еліптичних кривих (також відомі як множинне скалярне множення), швидке перетворення Фур’є тощо. В AI це також стає дедалі очевидніше: вже понад двадцять років більшість обчислень — це «переважно множення матриць» (хоча з різною точністю). Подібні тенденції спостерігаються й в інших сферах. Порівняно з 20 роками тому, у (ресурсоємних) обчисленнях набагато менше невідомих невідомих.
Що це означає?
Ключовий момент у тому, що клей (Glue) має бути оптимізований для того, щоб бути хорошим клеєм, а співпроцесор (coprocessor) — для того, щоб бути хорошим співпроцесором. Ми можемо дослідити значення цього у кількох ключових сферах.
EVM
Віртуальні машини блокчейну (наприклад, EVM) не повинні бути ефективними, вони повинні бути знайомими. Просто додайте правильні співпроцесори (також відомі як «precompile»), і обчислення в неефективній VM насправді може бути настільки ж ефективним, як і в нативній ефективній VM. Наприклад, накладні витрати EVM через 256-бітні регістри відносно невеликі, а переваги знайомості EVM та існуючої екосистеми розробників величезні та довготривалі. Команди, які оптимізують EVM, навіть виявили, що відсутність паралелізації зазвичай не є основною перешкодою для масштабування.
Найкращий спосіб покращити EVM, ймовірно, просто (i) додати кращі precompile або спеціалізовані операційні коди — наприклад, якась комбінація EVM-MAX і SIMD може бути розумною, а також (ii) покращити розміщення сховища, наприклад, зміни Verkle tree як побічний ефект значно знижують вартість доступу до сусідніх слотів сховища.
Оптимізація сховища у пропозиції Ethereum Verkle tree, яка групує сусідні ключі сховища разом і коригує вартість gas відповідно. Такі оптимізації, разом із кращими precompile, можуть бути важливішими, ніж зміни самої EVM.
Безпечні обчислення та відкритий hardware
Однією з великих проблем підвищення безпеки сучасних обчислень на рівні hardware є їх надмірна складність і закритість: чипи проектуються для ефективності, що вимагає закритих оптимізацій. Закладки легко приховати, побічні канали постійно виявляються.
Люди продовжують працювати над більш відкритими та безпечними альтернативами з різних сторін. Деякі обчислення дедалі частіше виконуються у довірених середовищах виконання, зокрема на телефонах користувачів, що вже підвищило безпеку користувачів. Рух за більш відкритий consumer hardware триває, і нещодавно були досягнуті певні перемоги, наприклад, ноутбук на RISC-V під Ubuntu.
Ноутбук на RISC-V під Debian
Однак ефективність все ще є проблемою. Автор статті за наведеним вище посиланням пише:
Нові відкриті чип-дизайни, такі як RISC-V, не можуть зрівнятися з процесорними технологіями, які існують і вдосконалюються десятиліттями. Прогрес завжди має початок.
Більш параноїдальні ідеї, такі як ця конструкція комп’ютера на RISC-V на FPGA, стикаються з ще більшими накладними витратами. Але що, якщо архітектура клею та співпроцесора означає, що ці накладні витрати насправді не мають значення? Що, якщо ми приймемо, що відкриті та безпечні чипи будуть повільнішими за закриті, і навіть відмовимося від таких поширених оптимізацій, як спекулятивне виконання та передбачення гілок, якщо потрібно, але спробуємо компенсувати це, додаючи (якщо потрібно, закриті) ASIC-модулі для найбільш інтенсивних типів обчислень? Чутливі обчислення можуть виконуватися на «головному чипі», оптимізованому для безпеки, відкритості та стійкості до побічних каналів. Інтенсивніші обчислення (наприклад, ZK-докази, AI) виконуватимуться на ASIC-модулях, які знатимуть менше про виконувані обчислення (можливо, через криптографічне засліплення, у деяких випадках навіть нуль інформації).
Криптографія
Ще один ключовий момент — усе це дуже оптимістично для криптографії, особливо для програмованої криптографії, яка стає мейнстрімом. Ми вже бачили деякі надоптимізовані реалізації для певних високо структурованих обчислень у SNARK, MPC та інших налаштуваннях: накладні витрати для деяких хеш-функцій лише в кілька сотень разів перевищують пряме виконання, а накладні витрати для AI (переважно множення матриць) дуже низькі. Подальші вдосконалення, такі як GKR, можуть ще більше знизити цей рівень. Повністю універсальне виконання VM, особливо у інтерпретаторі RISC-V, може й надалі мати накладні витрати близько десяти тисяч разів, але з причин, описаних у цій статті, це не має значення: якщо найбільш інтенсивні частини обчислень обробляються окремо за допомогою ефективних спеціалізованих технологій, загальні накладні витрати залишаються контрольованими.
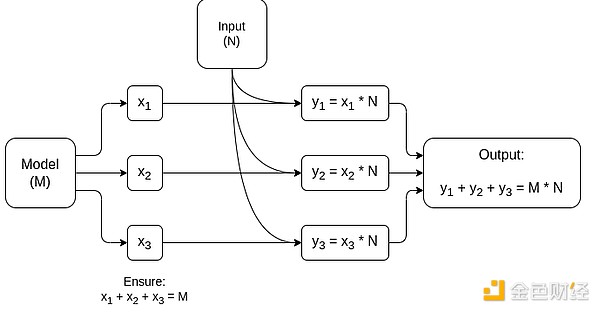
Схематичне зображення MPC, спеціалізованого для множення матриць — найбільшого компонента інференсу AI-моделей. Дивіться цю статтю для деталей, зокрема про те, як зберігати конфіденційність моделі та вхідних даних.
Винятком із ідеї «клейовий шар має бути знайомим, а не ефективним» є затримка, а меншою мірою — пропускна здатність даних. Якщо обчислення включає десятки повторних інтенсивних операцій над одними й тими ж даними (як у криптографії та AI), будь-яка затримка, спричинена неефективним клейовим шаром, може стати основним вузьким місцем у часі виконання. Тому клейовий шар також має вимоги до ефективності, хоча ці вимоги більш специфічні.
Висновок
Загалом, я вважаю, що наведені вище тенденції є дуже позитивним розвитком з багатьох точок зору. По-перше, це розумний спосіб максимізувати ефективність обчислень, зберігаючи зручність для розробників, і отримати більше обох для всіх. Зокрема, спеціалізація на стороні клієнта для підвищення ефективності підвищує нашу здатність виконувати чутливі та вимогливі до продуктивності обчислення (наприклад, ZK-докази, LLM-inference) локально на апаратному забезпеченні користувача. По-друге, це створює величезне вікно можливостей для того, щоб прагнення до ефективності не шкодило іншим цінностям, найочевиднішими з яких є безпека, відкритість і простота: безпека від побічних каналів і відкритість у комп’ютерному hardware, зниження складності схем у ZK-SNARK, зниження складності у віртуальних машинах. Історично прагнення до ефективності відсувало ці інші фактори на другий план. З архітектурою клею та співпроцесора це більше не потрібно. Одна частина машини оптимізує ефективність, інша — універсальність та інші цінності, і вони працюють разом.
Ця тенденція також дуже сприятлива для криптографії, оскільки сама криптографія є основним прикладом «дорогих структурованих обчислень», і ця тенденція прискорює її розвиток. Це ще одна можливість підвищити безпеку. У світі блокчейну також стає можливо підвищити безпеку: ми можемо менше турбуватися про оптимізацію віртуальної машини і більше зосереджуватися на оптимізації precompile та інших функцій, що співіснують із віртуальною машиною.
По-третє, ця тенденція відкриває можливості для менших і новіших учасників. Якщо обчислення стають менш монолітними, а більш модульними, це значно знижує бар’єр для входу. Навіть ASIC для одного типу обчислень може мати значення. Це також стосується сфери ZK-доказів та оптимізації EVM. Написання коду з майже передовою ефективністю стає простішим і доступнішим. Аудит і формальна верифікація такого коду також стають простішими і доступнішими. Нарешті, оскільки ці дуже різні обчислювальні сфери зближуються до спільних моделей, між ними з’являється більше простору для співпраці та навчання.
Відмова від відповідальності: зміст цієї статті відображає виключно думку автора і не представляє платформу в будь-якій якості. Ця стаття не повинна бути орієнтиром під час прийняття інвестиційних рішень.
Вас також може зацікавити
XRP опускається нижче $2, незважаючи на приплив $1B в ETF: наскільки низько може впасти ціна?

Цифрові банки вже давно перестали заробляти гроші на банківських послугах; справжня золота жила — у стейблкоїнах та верифікації особистості
Кількість користувачів не дорівнює прибутковості, стабільність та ідентичність є основою цифрового банкінгу.

Огляд зіркових нових проєктів та важливих оновлень в екосистемі Solana, окрім торгівлі
Конференція Solana Breakpoint 2025 була надзвичайно яскравою та насиченою подіями.

Огляд 33 переможців хакатону Solana Breakpoint 2025
Понад 9000 учасників об'єдналися в команди та подали 1576 проєктів, у підсумку 33 проєкти здобули перемогу — це найкращі галузеві стартапи, відібрані з сотень.
