Коротко
- DeepSeek V4 може з’явитися протягом кількох тижнів, орієнтуючись на елітний рівень продуктивності кодування.
- Інсайдери стверджують, що вона може перевершити Claude і ChatGPT у завданнях з довгим контекстом для коду.
- Розробники вже в захваті перед потенційним проривом.
За повідомленнями, DeepSeek планує випустити свою модель V4 приблизно в середині лютого, і якщо внутрішні тести вірні, гігантам штучного інтелекту із Силіконової долини варто насторожитися.
AI-стартап із Ханчжоу, ймовірно, націлюється на реліз близько 17 лютого — на Китайський Новий рік, звичайно, — із моделлю, спеціально розробленою для завдань кодування, згідно з
. Особи, які мають прямий доступ до проєкту, стверджують, що V4 випереджає як Claude від Anthropic, так і серію GPT від OpenAI у внутрішніх тестах, особливо при роботі з надзвичайно довгими запитами коду.
Безумовно, жодних бенчмарків чи інформації про модель публічно не розкрито, тому такі твердження неможливо перевірити напряму. DeepSeek також не підтвердила ці чутки.
Проте спільнота розробників не чекає на офіційні новини. На Reddit у r/DeepSeek та r/LocalLLaMA вже стає гаряче, користувачі запасаються API-кредитами, а ентузіасти на X швидко діляться своїми прогнозами, що V4 може закріпити статус DeepSeek як сміливого аутсайдера, який не грає за мільярдними правилами Силіконової долини.
Anthropic заблокувала підписки Claude у сторонніх додатках на кшталт OpenCode, і, за чутками, відключила доступ xAI та OpenAI.
Claude та Claude Code чудові, але поки не у 10 разів кращі. Це лише підштовхне інші лабораторії працювати швидше над своїми моделями/агентами для кодування.
Чутки, що DeepSeek V4 от-от з’явиться…
— Yuchen Jin (@Yuchenj_UW) 9 січня 2026
Це не буде перше велике потрясіння від DeepSeek. Коли компанія випустила свою модель для міркувань R1 у січні 2025 року, це спровокувало розпродаж на світових ринках на 1 трильйон доларів.
Причина? R1 від DeepSeek зрівнялася з o1 від OpenAI за результатами математичних і логічних тестів, хоча її розробка коштувала лише $6 мільйонів — приблизно у 68 разів дешевше, ніж у конкурентів. Її модель V3 пізніше досягла 90,2% на бенчмарку MATH-500, випередивши Claude з його 78,3%, а недавнє оновлення “V3.2 Speciale” ще більше покращило результати.
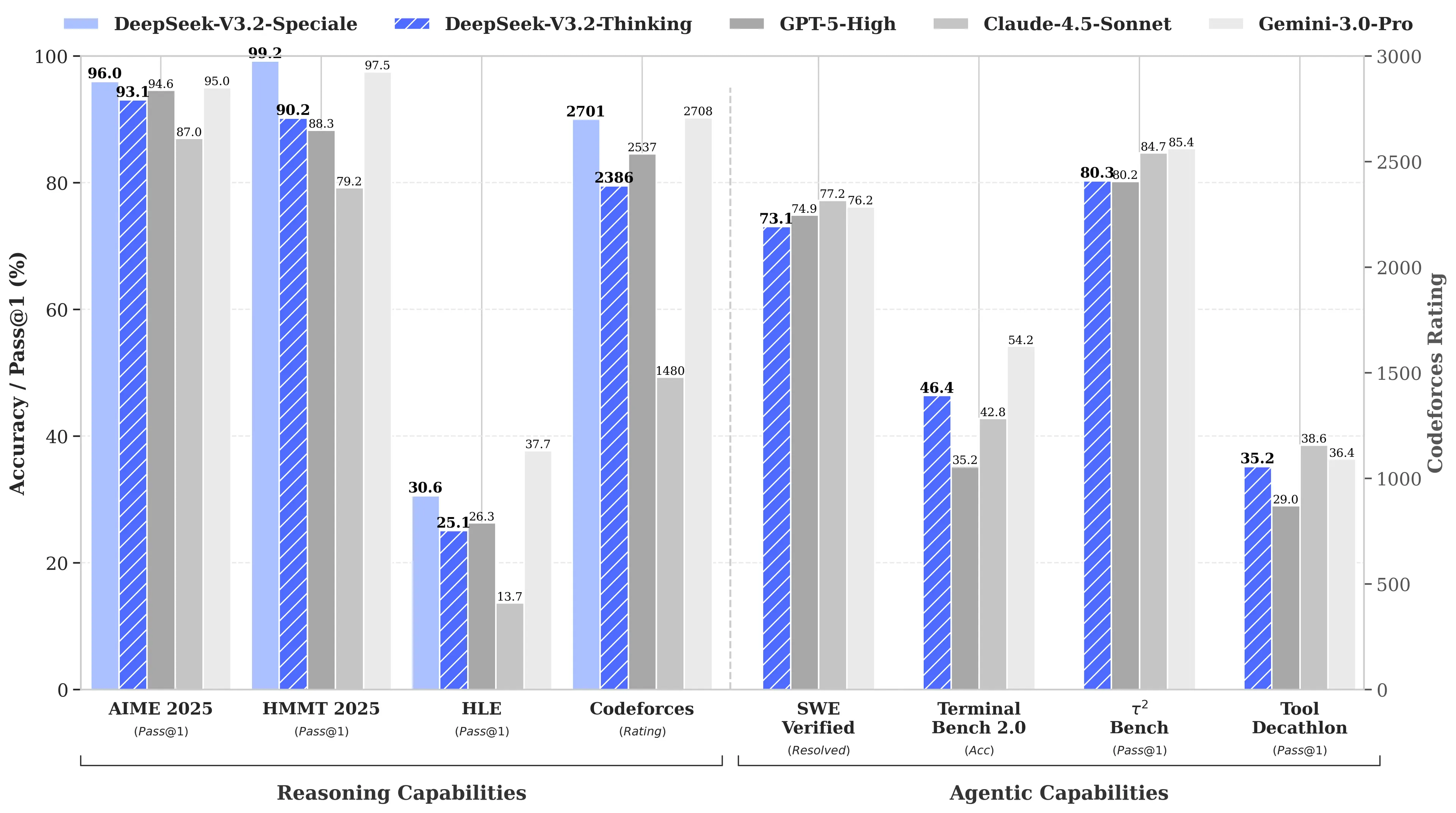
Image: DeepSeek
Зосередження V4 на кодуванні стане стратегічним поворотом. Якщо R1 робила акцент на чистій логіці — математика, логічні докази, — то V4 є гібридною моделлю (міркування та неміркувальні завдання), що орієнтована на ринок корпоративних розробників, де високоточна генерація коду безпосередньо конвертується у прибуток.
Щоб заявити про домінування, V4 має перевершити Claude Opus 4.5, який наразі утримує рекорд SWE-bench Verified з результатом 80,9%. Але якщо взяти до уваги попередні релізи DeepSeek, то досягти цього навіть з усіма обмеженнями, які стоять перед китайською AI-лабораторією, не виглядає неможливим.
Не така вже й секретна “родзинка”
Якщо чутки правдиві, як невеликій лабораторії вдається досягати таких результатів?
Секретна зброя компанії може міститися у дослідницькій статті від 1 січня: Manifold-Constrained Hyper-Connections, або mHC. Співавтором якої є засновник Лян Веньфен, новий метод тренування вирішує фундаментальну проблему масштабування великих мовних моделей — як розширити їхню ємність, не роблячи модель нестабільною чи не даючи їй “вибухати” під час тренування.
Традиційні AI-архітектури змушують всю інформацію проходити через один вузький канал. mHC розширює цей канал до кількох потоків, які можуть обмінюватися інформацією без зриву навчання.
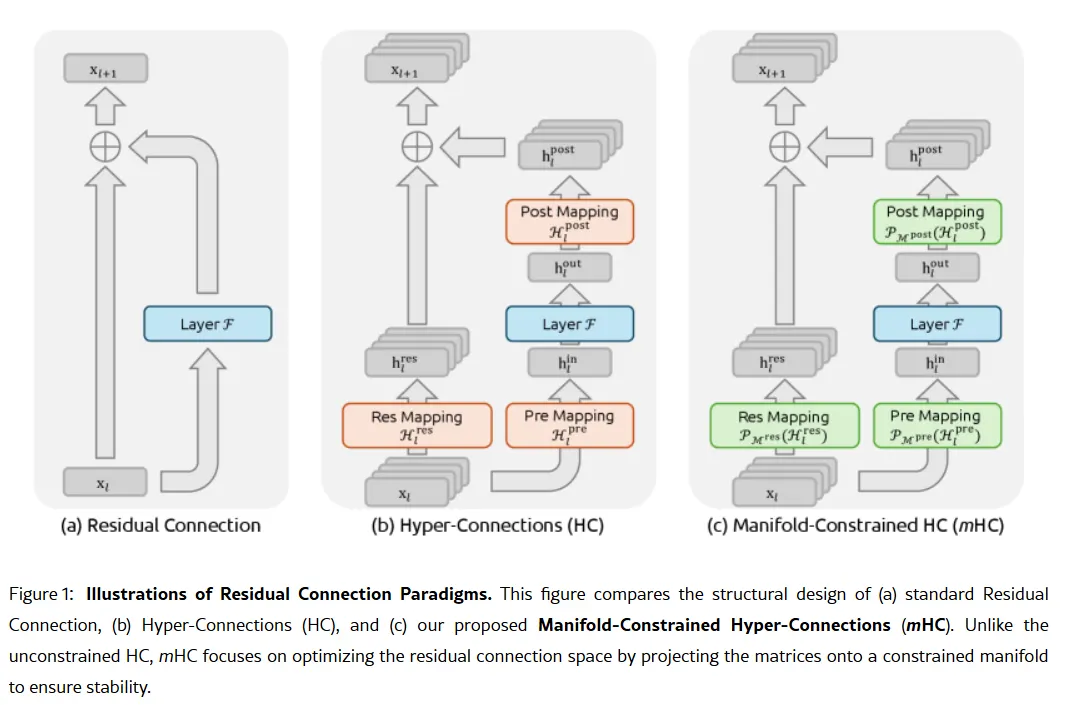
Image: DeepSeek
Вей Сун, головна аналітикиня з AI у Counterpoint Research, назвала mHC “вражаючим проривом” у коментарях для
. За її словами, ця технологія демонструє, що DeepSeek може “обійти обмеження обчислювальних ресурсів та розблокувати стрибки в інтелекті”, навіть за обмеженого доступу до просунутих чипів через експортні обмеження США.
Лян Цзе Су, головний аналітик Omdia, відзначив, що готовність DeepSeek публікувати свої методи сигналізує про “нову впевненість у китайській AI-індустрії”. Відкритий підхід компанії зробив її улюбленцем серед розробників, які бачать у ній втілення того, чим колись була OpenAI, до переходу на закриті моделі й мільярдні раунди фінансування.
Однак не всі переконані. Деякі розробники на Reddit скаржаться, що моделі DeepSeek для міркувань витрачають ресурси на прості завдання, а критики вважають, що бенчмарки компанії не відображають реальної складності задач. Один пост на Medium під назвою "DeepSeek — відстій, і я більше не робитиму вигляд, що це не так" став вірусним у квітні 2025 року, звинувачуючи моделі у створенні “шаблонної нісенітниці з багами” та “вигаданих бібліотек”.
У DeepSeek також є свої проблеми. Компанію переслідують побоювання щодо приватності, деякі уряди забороняли рідний застосунок DeepSeek. Її зв'язки з Китаєм та питання цензури у моделях додають геополітичного напруження до технічних дискусій.
Проте імпульс незаперечний. Deepseek широко використовується в Азії, і якщо V4 виправдає свої обіцянки щодо кодування, корпоративне впровадження на Заході може стати наступним кроком.
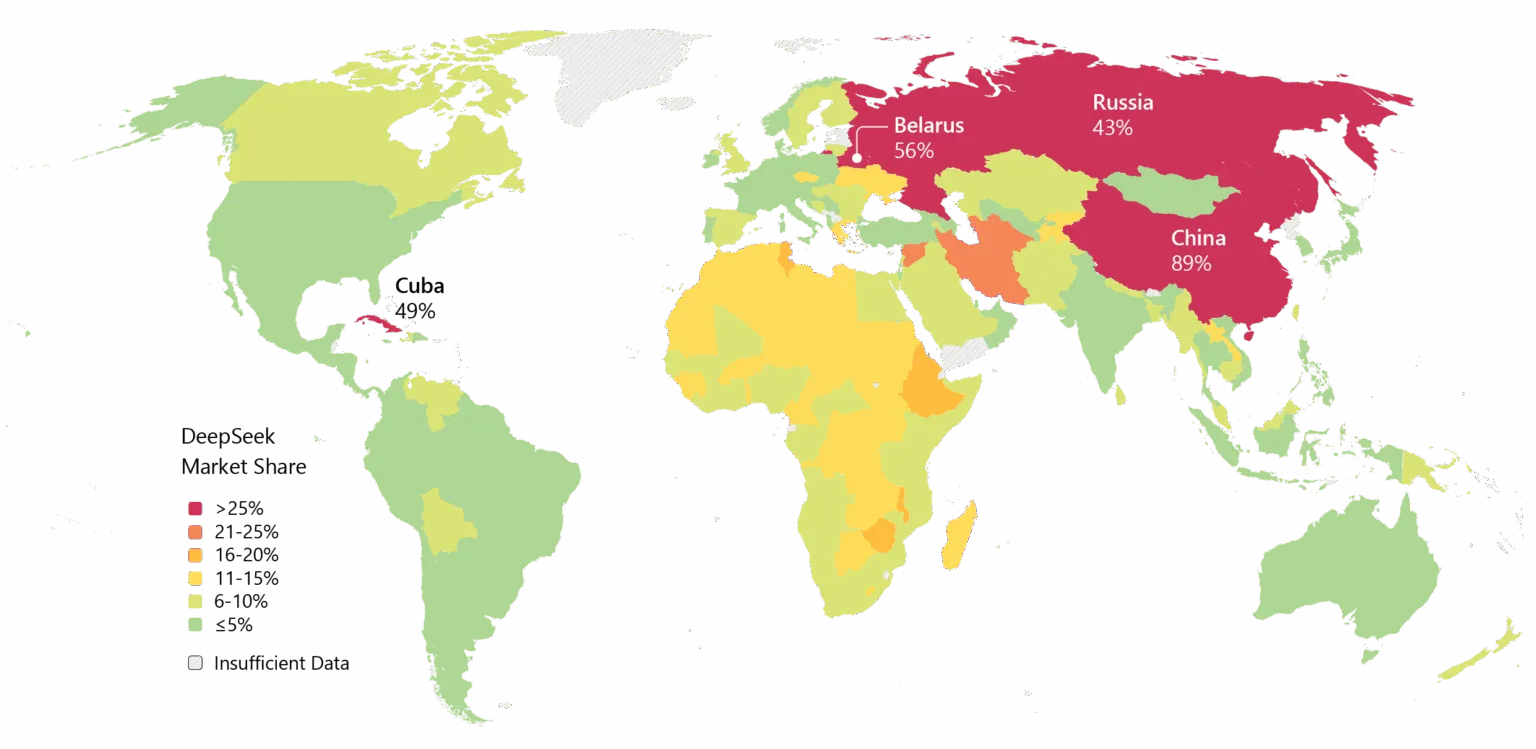
Image: Microsoft
Значення має і таймінг. Згідно з
, DeepSeek спочатку планувала випустити свою модель R2 у травні 2025 року, але відклала запуск після того, як засновник Лян залишився незадоволений її продуктивністю. Тепер, коли V4 орієнтується на лютий, а R2, ймовірно, з’явиться у серпні, компанія рухається у темпі, що свідчить про терміновість — або впевненість. А можливо, і те, й інше.

