
Vitalik: Kiến trúc kết dính và đồng xử lý, ý tưởng mới nâng cao hiệu suất và tính an toàn

Chất kết dính nên được tối ưu hóa để trở thành một chất kết dính tốt, còn bộ xử lý phụ cũng nên được tối ưu hóa để trở thành một bộ xử lý phụ tốt.
Bộ kết dính nên được tối ưu hóa để trở thành một bộ kết dính tốt, trong khi bộ đồng xử lý cũng nên được tối ưu hóa để trở thành một bộ đồng xử lý tốt.
Tiêu đề gốc: "Glue and coprocessor architectures"
Tác giả: Vitalik Buterin, nhà sáng lập Ethereum
Biên dịch: Deng Tong, Jinse Finance
Đặc biệt cảm ơn Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra và các cộng tác viên Flashbots đã cung cấp phản hồi và nhận xét.
Nếu bạn phân tích ở mức độ chi tiết vừa phải bất kỳ tính toán tiêu tốn tài nguyên nào đang diễn ra trong thế giới hiện đại, bạn sẽ nhận thấy một đặc điểm lặp đi lặp lại: tính toán có thể được chia thành hai phần:
- Một lượng nhỏ logic nghiệp vụ phức tạp nhưng không tốn nhiều tính toán;
- Một lượng lớn công việc đắt đỏ nhưng có cấu trúc cao.
Hai hình thức tính toán này nên được xử lý theo những cách khác nhau: loại đầu tiên, kiến trúc có thể kém hiệu quả hơn nhưng cần có tính phổ quát rất cao; loại thứ hai, kiến trúc có thể kém phổ quát hơn, nhưng cần có hiệu suất rất cao.
Những ví dụ thực tiễn về các cách tiếp cận khác nhau này là gì?
Trước tiên, hãy cùng tìm hiểu về môi trường mà tôi quen thuộc nhất: Ethereum Virtual Machine (EVM). Đây là bản theo dõi debug geth của một giao dịch Ethereum mà tôi thực hiện gần đây: cập nhật IPFS hash cho blog của tôi trên ENS. Giao dịch này tiêu tốn tổng cộng 46924 gas, có thể được phân loại như sau:
- Chi phí cơ bản: 21,000
- Dữ liệu gọi: 1,556
- Thực thi EVM: 24,368
- Opcode SLOAD: 6,400
- Opcode SSTORE: 10,100
- Opcode LOG: 2,149
- Khác: 6,719

Theo dõi EVM cập nhật hash ENS. Cột áp chót là mức tiêu thụ gas.
Ý nghĩa của câu chuyện này là: phần lớn việc thực thi (nếu chỉ tính EVM là khoảng 73%, nếu tính cả phần chi phí cơ bản liên quan đến tính toán là khoảng 85%) tập trung vào một số ít các thao tác đắt đỏ có cấu trúc: đọc/ghi bộ nhớ, log và mã hóa (chi phí cơ bản bao gồm 3000 để xác thực chữ ký, EVM còn bao gồm 272 cho hash). Phần còn lại là "logic nghiệp vụ": chuyển đổi calldata để lấy ID bản ghi tôi muốn thiết lập và hash tôi muốn gán, v.v. Trong chuyển token, điều này bao gồm cộng/trừ số dư, trong các ứng dụng cao cấp hơn, có thể bao gồm vòng lặp, v.v.
Trong EVM, hai hình thức thực thi này được xử lý khác nhau. Logic nghiệp vụ cấp cao được viết bằng ngôn ngữ cấp cao hơn, thường là Solidity, có thể biên dịch sang EVM. Công việc đắt đỏ vẫn được kích hoạt bởi opcode EVM (như SLOAD), nhưng hơn 99% tính toán thực tế được thực hiện trong các module chuyên biệt viết trực tiếp trong mã client (thậm chí là thư viện).
Để củng cố sự hiểu biết về mô hình này, hãy khám phá nó trong một bối cảnh khác: mã AI viết bằng python sử dụng torch.
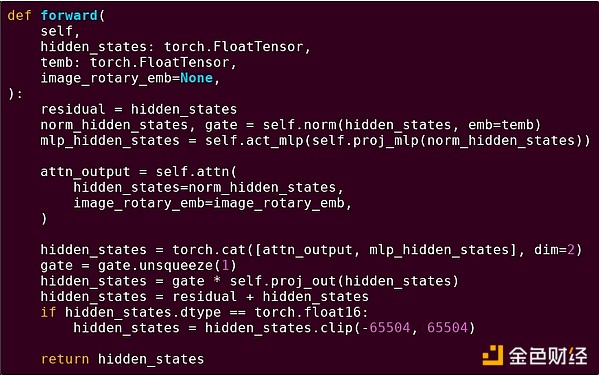
Forward pass của một block trong mô hình transformer
Chúng ta thấy gì ở đây? Một lượng nhỏ "logic nghiệp vụ" viết bằng Python mô tả cấu trúc của thao tác đang thực hiện. Trong thực tế, còn có một loại logic nghiệp vụ khác quyết định chi tiết như lấy input thế nào và xử lý output ra sao. Tuy nhiên, nếu đi sâu vào từng thao tác (self.norm, torch.cat, +, *, các bước trong self.attn...), ta sẽ thấy các phép tính vector hóa: cùng một thao tác được tính song song trên nhiều giá trị. Giống như ví dụ đầu tiên, một phần nhỏ tính toán dành cho logic nghiệp vụ, phần lớn dành cho các phép toán ma trận và vector lớn — thực tế, chủ yếu là nhân ma trận.
Giống như trong ví dụ EVM, hai loại công việc này được xử lý theo hai cách khác nhau. Mã logic nghiệp vụ cấp cao viết bằng Python, một ngôn ngữ rất linh hoạt nhưng chậm, và chúng ta chấp nhận sự kém hiệu quả vì nó chỉ chiếm một phần nhỏ tổng chi phí tính toán. Trong khi đó, các thao tác nặng được viết bằng mã tối ưu hóa cao, thường là mã CUDA chạy trên GPU. Thậm chí ngày càng nhiều inference LLM được thực hiện trên ASIC.
Mật mã học lập trình hiện đại như SNARK lại tuân theo mô hình tương tự ở hai cấp độ. Đầu tiên, prover có thể được viết bằng ngôn ngữ cấp cao, trong đó công việc nặng được thực hiện qua các thao tác vector hóa, giống như ví dụ AI ở trên. Mã STARK hình tròn của tôi ở đây minh họa điều này. Thứ hai, chương trình thực thi bên trong mật mã học cũng có thể được viết theo cách phân chia giữa logic nghiệp vụ tổng quát và công việc đắt đỏ có cấu trúc cao.
Để hiểu cách hoạt động, hãy xem một trong những xu hướng mới nhất của bằng chứng STARK. Để tổng quát và dễ sử dụng, các nhóm ngày càng xây dựng prover STARK cho các máy ảo tối giản được sử dụng rộng rãi như RISC-V. Bất kỳ chương trình nào cần chứng minh thực thi đều có thể biên dịch sang RISC-V, sau đó prover có thể chứng minh việc thực thi mã RISC-V đó.
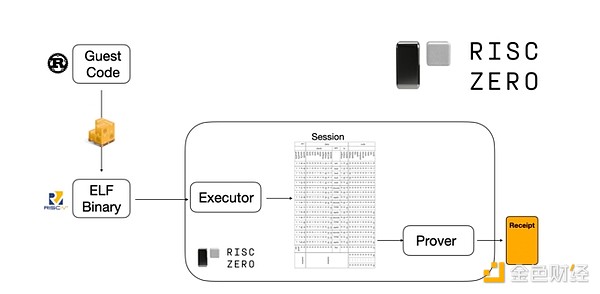
Biểu đồ từ tài liệu RiscZero
Điều này rất tiện lợi: nghĩa là ta chỉ cần viết logic chứng minh một lần, từ đó bất kỳ chương trình nào cần chứng minh đều có thể viết bằng bất kỳ ngôn ngữ lập trình "truyền thống" nào (ví dụ RiskZero hỗ trợ Rust). Nhưng có một vấn đề: phương pháp này tạo ra chi phí lớn. Mật mã học lập trình vốn đã rất đắt đỏ; thêm chi phí chạy mã trong trình thông dịch RISC-V là quá nhiều. Vì vậy, các nhà phát triển đã nghĩ ra một mẹo: xác định các thao tác đắt đỏ cụ thể chiếm phần lớn tính toán (thường là hash và chữ ký), rồi tạo các module chuyên biệt để chứng minh các thao tác này một cách cực kỳ hiệu quả. Sau đó, bạn chỉ cần kết hợp hệ thống chứng minh RISC-V tổng quát nhưng kém hiệu quả với hệ thống chứng minh chuyên biệt nhưng hiệu quả, là có thể đạt được cả hai mặt tốt nhất.
Ngoài ZK-SNARK, các loại mật mã học lập trình khác như tính toán đa bên (MPC) và mã hóa đồng hình hoàn toàn (FHE) cũng có thể được tối ưu hóa theo cách tương tự.
Tổng thể hiện tượng này như thế nào?
Tính toán hiện đại ngày càng tuân theo cái mà tôi gọi là kiến trúc bộ kết dính và bộ đồng xử lý: bạn có một số thành phần "kết dính" trung tâm, có tính phổ quát cao nhưng kém hiệu quả, chịu trách nhiệm truyền dữ liệu giữa một hoặc nhiều thành phần bộ đồng xử lý, các thành phần này kém phổ quát nhưng hiệu quả cao.
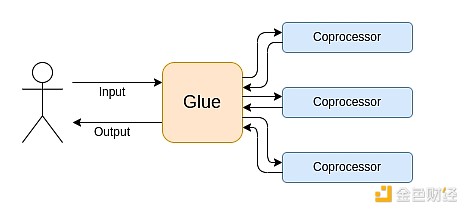
Đây là một sự đơn giản hóa: trên thực tế, đường cong đánh đổi giữa hiệu suất và tính phổ quát gần như luôn có nhiều hơn hai lớp. GPU và các chip thường được gọi là "bộ đồng xử lý" trong ngành không phổ quát bằng CPU, nhưng phổ quát hơn ASIC. Đánh đổi về mức độ chuyên biệt rất phức tạp, phụ thuộc vào dự đoán và trực giác về phần nào của thuật toán sẽ không thay đổi sau 5 năm, phần nào sẽ thay đổi sau 6 tháng. Trong kiến trúc bằng chứng ZK, ta thường thấy các lớp chuyên biệt hóa nhiều tầng tương tự. Nhưng để có mô hình tư duy rộng, chỉ cần nghĩ đến hai tầng là đủ. Trong nhiều lĩnh vực tính toán cũng có tình huống tương tự:
Nhìn từ các ví dụ trên, rõ ràng tính toán có thể được phân chia theo cách này, dường như là một quy luật tự nhiên. Thực tế, bạn có thể tìm thấy các ví dụ về chuyên biệt hóa tính toán trong nhiều thập kỷ. Tuy nhiên, tôi cho rằng sự phân tách này đang gia tăng. Và có lý do cho điều đó:
Chỉ gần đây chúng ta mới đạt đến giới hạn tăng tốc độ xung nhịp CPU, do đó chỉ có thể đạt được lợi ích tiếp theo thông qua song song hóa. Nhưng song song hóa rất khó để suy luận, vì vậy đối với các nhà phát triển, tiếp tục suy luận tuần tự và để song song hóa diễn ra ở backend thường thực tế hơn, và được đóng gói trong các module chuyên biệt cho các thao tác cụ thể.
Tốc độ tính toán gần đây mới trở nên nhanh đến mức chi phí tính toán cho logic nghiệp vụ thực sự có thể bỏ qua. Trong thế giới này, tối ưu hóa VM chạy logic nghiệp vụ cho các mục tiêu ngoài hiệu suất tính toán cũng có ý nghĩa: thân thiện với nhà phát triển, quen thuộc, an toàn và các mục tiêu tương tự khác. Đồng thời, các module "bộ đồng xử lý" chuyên biệt có thể tiếp tục được thiết kế cho hiệu suất, và lấy sự an toàn và thân thiện với nhà phát triển từ "giao diện" tương đối đơn giản với bộ kết dính.
Những thao tác đắt đỏ quan trọng nhất ngày càng trở nên rõ ràng. Điều này rõ ràng nhất trong mật mã học, nơi các loại thao tác đắt đỏ cụ thể có khả năng được sử dụng nhất: phép toán modulo, tổ hợp tuyến tính đường cong elliptic (còn gọi là phép nhân đa vô hướng), biến đổi Fourier nhanh, v.v. Trong AI, điều này cũng ngày càng rõ ràng, hơn hai mươi năm qua, phần lớn tính toán là "chủ yếu là nhân ma trận" (dù mức độ chính xác khác nhau). Các lĩnh vực khác cũng xuất hiện xu hướng tương tự. So với 20 năm trước, số lượng điều chưa biết trong tính toán (tính toán tiêu tốn tài nguyên) đã giảm đi rất nhiều.
Điều này có ý nghĩa gì?
Một điểm then chốt là, bộ kết dính (Glue) nên được tối ưu hóa để trở thành một bộ kết dính tốt, còn bộ đồng xử lý (coprocessor) cũng nên được tối ưu hóa để trở thành một bộ đồng xử lý tốt. Chúng ta có thể khám phá ý nghĩa của điều này trong một số lĩnh vực then chốt.
EVM
Máy ảo blockchain (ví dụ EVM) không cần hiệu quả, chỉ cần quen thuộc. Chỉ cần thêm đúng bộ đồng xử lý (còn gọi là "precompile"), tính toán trong VM kém hiệu quả thực tế có thể hiệu quả như trong VM hiệu quả gốc. Ví dụ, chi phí phát sinh từ thanh ghi 256 bit của EVM là tương đối nhỏ, trong khi lợi ích từ sự quen thuộc của EVM và hệ sinh thái nhà phát triển hiện tại là rất lớn và bền vững. Các nhóm phát triển tối ưu hóa EVM thậm chí còn phát hiện ra rằng, thiếu song song hóa thường không phải là rào cản chính cho khả năng mở rộng.
Cách tốt nhất để cải thiện EVM có thể chỉ là (i) thêm precompile hoặc opcode chuyên biệt tốt hơn, ví dụ sự kết hợp nào đó giữa EVM-MAX và SIMD có thể hợp lý, và (ii) cải thiện bố cục lưu trữ, ví dụ thay đổi Verkle tree như một tác dụng phụ, làm giảm đáng kể chi phí truy cập các slot lưu trữ liền kề nhau.
Tối ưu hóa lưu trữ trong đề xuất Verkle tree của Ethereum, đặt các khóa lưu trữ liền kề lại với nhau và điều chỉnh chi phí gas cho phù hợp. Những tối ưu hóa như vậy, cùng với precompile tốt hơn, có thể quan trọng hơn việc điều chỉnh EVM bản thân nó.
Tính toán an toàn và phần cứng mở
Một thách thức lớn trong việc nâng cao bảo mật tính toán hiện đại ở tầng phần cứng là tính chất quá phức tạp và độc quyền: thiết kế chip để hiệu quả, điều này đòi hỏi tối ưu hóa độc quyền. Cửa hậu dễ bị ẩn giấu, lỗ hổng kênh bên liên tục bị phát hiện.
Mọi người tiếp tục nỗ lực từ nhiều góc độ để thúc đẩy các giải pháp thay thế mở và an toàn hơn. Một số tính toán ngày càng được thực hiện trong môi trường thực thi tin cậy, bao gồm cả trên điện thoại của người dùng, điều này đã nâng cao bảo mật cho người dùng. Phong trào thúc đẩy phần cứng tiêu dùng mã nguồn mở vẫn tiếp tục, gần đây đã có một số thành công như laptop RISC-V chạy Ubuntu.
Laptop RISC-V chạy Debian
Tuy nhiên, hiệu suất vẫn là một vấn đề. Tác giả bài viết liên kết ở trên viết:
Các thiết kế chip mã nguồn mở mới hơn như RISC-V không thể sánh được với công nghệ xử lý đã tồn tại và được cải tiến qua hàng chục năm. Tiến bộ luôn có một điểm khởi đầu.
Những ý tưởng thận trọng hơn, như thiết kế máy tính RISC-V trên FPGA này, còn gặp chi phí lớn hơn. Nhưng nếu kiến trúc bộ kết dính và bộ đồng xử lý có nghĩa là chi phí này thực ra không quan trọng thì sao? Nếu chúng ta chấp nhận rằng chip mở và an toàn sẽ chậm hơn chip độc quyền, thậm chí nếu cần phải từ bỏ các tối ưu hóa phổ biến như thực thi dự đoán và dự đoán nhánh, nhưng cố gắng bù đắp bằng cách thêm các module ASIC (nếu cần, có thể là độc quyền) cho các loại tính toán chuyên biệt nặng nhất thì sao? Tính toán nhạy cảm có thể được thực hiện trên "chip chính", được tối ưu hóa cho bảo mật, thiết kế mở và chống kênh bên. Tính toán nặng hơn (ví dụ ZK proof, AI) sẽ được thực hiện trên các module ASIC, các module này sẽ biết ít thông tin hơn về tính toán đang thực hiện (có thể, thông qua làm mù mã hóa, trong một số trường hợp thậm chí là zero-knowledge).
Mật mã học
Một điểm then chốt khác là, tất cả điều này đều rất lạc quan cho mật mã học, đặc biệt là khi mật mã học lập trình trở thành xu hướng chủ đạo. Chúng ta đã thấy một số triển khai siêu tối ưu cho các phép tính có cấu trúc cao cụ thể trong SNARK, MPC và các thiết lập khác: chi phí cho một số hàm hash chỉ đắt hơn vài trăm lần so với chạy tính toán trực tiếp, và chi phí cho AI (chủ yếu là nhân ma trận) cũng rất thấp. Các cải tiến như GKR có thể còn giảm mức này hơn nữa. Thực thi VM hoàn toàn tổng quát, đặc biệt khi chạy trong trình thông dịch RISC-V, có thể tiếp tục tạo ra chi phí khoảng mười nghìn lần, nhưng vì lý do đã mô tả trong bài này, điều đó không quan trọng: miễn là phần nặng nhất của tính toán được xử lý riêng bằng kỹ thuật chuyên biệt hiệu quả, tổng chi phí vẫn kiểm soát được.
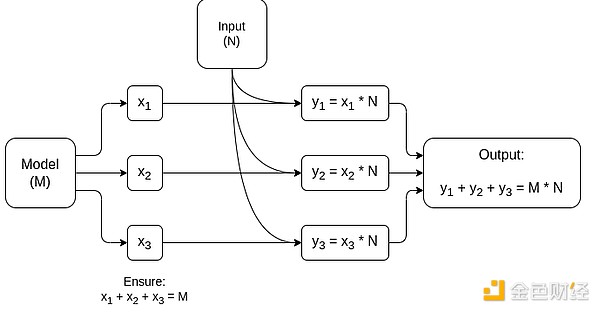
Sơ đồ đơn giản hóa của MPC chuyên dụng cho nhân ma trận, thành phần lớn nhất trong suy luận mô hình AI. Xem bài viết này để biết thêm chi tiết, bao gồm cách giữ bí mật cho mô hình và input.
Một ngoại lệ cho ý tưởng "lớp kết dính chỉ cần quen thuộc, không cần hiệu quả" là độ trễ, và ở mức độ nhỏ hơn là băng thông dữ liệu. Nếu tính toán liên quan đến việc lặp lại hàng chục lần các thao tác nặng trên cùng một dữ liệu (như trong mật mã học và AI), thì bất kỳ độ trễ nào do lớp kết dính kém hiệu quả gây ra đều có thể trở thành nút thắt chính cho thời gian chạy. Do đó, lớp kết dính cũng có yêu cầu về hiệu suất, dù các yêu cầu này cụ thể hơn.
Kết luận
Tổng thể, tôi cho rằng các xu hướng trên là phát triển rất tích cực từ nhiều góc độ. Đầu tiên, đây là cách hợp lý để tối đa hóa hiệu suất tính toán trong khi vẫn giữ được sự thân thiện với nhà phát triển, có thể đồng thời đạt được nhiều hơn cả hai điều này đều có lợi cho mọi người. Đặc biệt, bằng cách chuyên biệt hóa ở phía client để tăng hiệu suất, nó nâng cao khả năng chạy các tính toán nhạy cảm và yêu cầu hiệu suất cao (ví dụ ZK proof, LLM inference) ngay trên phần cứng người dùng. Thứ hai, nó tạo ra một cơ hội lớn để đảm bảo việc theo đuổi hiệu suất không làm tổn hại các giá trị khác, rõ ràng nhất là bảo mật, mở và đơn giản: bảo mật kênh bên và tính mở trong phần cứng máy tính, giảm độ phức tạp mạch trong ZK-SNARK, giảm độ phức tạp trong máy ảo. Lịch sử cho thấy việc theo đuổi hiệu suất thường khiến các yếu tố này bị xem nhẹ. Với kiến trúc bộ kết dính và bộ đồng xử lý, điều đó không còn cần thiết nữa. Một phần của máy được tối ưu hóa cho hiệu suất, phần còn lại tối ưu hóa cho tính phổ quát và các giá trị khác, cả hai phối hợp với nhau.
Xu hướng này cũng rất có lợi cho mật mã học, vì bản thân mật mã học là một ví dụ điển hình về "tính toán cấu trúc đắt đỏ", và xu hướng này thúc đẩy sự phát triển của nó. Điều này lại tạo thêm một cơ hội để tăng cường bảo mật. Trong thế giới blockchain, bảo mật cũng được nâng cao: chúng ta có thể ít lo lắng hơn về việc tối ưu hóa máy ảo, và tập trung hơn vào việc tối ưu hóa precompile và các chức năng khác cùng tồn tại với máy ảo.
Thứ ba, xu hướng này tạo cơ hội cho các bên nhỏ hơn, mới hơn tham gia. Nếu tính toán trở nên ít đơn nhất hơn và mô-đun hóa hơn, ngưỡng gia nhập sẽ giảm đi rất nhiều. Ngay cả ASIC cho một loại tính toán cũng có thể tạo ra sự khác biệt. Điều này cũng đúng trong lĩnh vực ZK proof và tối ưu hóa EVM. Việc viết mã có hiệu suất gần như tiên tiến trở nên dễ dàng và dễ tiếp cận hơn. Việc kiểm toán và xác minh hình thức mã như vậy cũng trở nên dễ dàng và dễ tiếp cận hơn. Cuối cùng, vì các lĩnh vực tính toán rất khác nhau này đang hội tụ về một số mô hình chung, nên có nhiều không gian hơn cho sự hợp tác và học hỏi lẫn nhau giữa chúng.
Tuyên bố miễn trừ trách nhiệm: Mọi thông tin trong bài viết đều thể hiện quan điểm của tác giả và không liên quan đến nền tảng. Bài viết này không nhằm mục đích tham khảo để đưa ra quyết định đầu tư.
Bạn cũng có thể thích
Giám đốc điều hành Google kiếm được hàng triệu đô la chỉ sau một đêm nhờ giao dịch nội gián
Thị trường dự đoán tham chiếu địa chỉ nội bộ thao túng thuật toán Google.

Giám đốc điều hành Google kiếm được hàng triệu USD chỉ sau một đêm nhờ giao dịch nội gián
Địa chỉ nội bộ tham khảo bảng kèo thị trường dự đoán để thao túng thuật toán của Google.
Năm 2025 của stablecoin: Bạn ở Hồng Lâu, tôi ở Tây Du
Nhưng cuối cùng, chúng ta đều có thể đi đến cùng một đích.

Mức độ sợ hãi cực đoan của XRP phản ánh đợt tăng giá 22% trước đây
