
26 年首次亮相,黃仁勳扔出 2.5 噸重的「核彈」炸場|CES2026

顯示原文
作者:爱范儿
*結尾有個小彩蛋影片。 這是NVIDIA五年來,首次在CES上沒有發表消費級顯示卡。 CEO黃仁勳大步走向NVIDIA Live舞台中央,還是去年那件亮面鱷魚皮外套。  與去年單獨主旨演講不同,2026年的黃仁勳密集趕場。從NVIDIA Live到西門子工業AI對話,再到聯想TechWorld大會,48小時內橫跨三場活動。 上一次,他在CES發表了RTX 50系列顯示卡。而這一次,物理AI、機器人技術,以及一台重達2.5噸的「 企業級核彈 」,成為了真正的主角。 Vera Rubin運算平台登場,依舊是買越多省越多 發布會期間,愛搞創意的老黃直接把一台2.5噸重的AI伺服器機架搬上舞台,也因此引出了本次發布會的重點:Vera Rubin運算平台,以發現暗物質的天文學家命名,目標只有一個: 加速AI訓練的速度,讓下一代模型提前到來。
與去年單獨主旨演講不同,2026年的黃仁勳密集趕場。從NVIDIA Live到西門子工業AI對話,再到聯想TechWorld大會,48小時內橫跨三場活動。 上一次,他在CES發表了RTX 50系列顯示卡。而這一次,物理AI、機器人技術,以及一台重達2.5噸的「 企業級核彈 」,成為了真正的主角。 Vera Rubin運算平台登場,依舊是買越多省越多 發布會期間,愛搞創意的老黃直接把一台2.5噸重的AI伺服器機架搬上舞台,也因此引出了本次發布會的重點:Vera Rubin運算平台,以發現暗物質的天文學家命名,目標只有一個: 加速AI訓練的速度,讓下一代模型提前到來。  通常來說,NVIDIA內部有個規矩:每代產品最多只改1-2顆晶片。 但這次Vera Rubin打破了常規,一口氣重新設計了6款晶片,並已全面進入量產階段。
通常來說,NVIDIA內部有個規矩:每代產品最多只改1-2顆晶片。 但這次Vera Rubin打破了常規,一口氣重新設計了6款晶片,並已全面進入量產階段。
究其原因,隨著摩爾定律的放緩,傳統效能提升方式已經跟不上AI模型每年10倍的增長速度,所以NVIDIA選擇了「極致協同設計」——在所有晶片、整個平台各個層級上同時創新。 這6款晶片分別是: 1. Vera CPU: - 88個NVIDIA客製Olympus核心 - 採用NVIDIA空間多執行緒技術,支援176個執行緒 - NVLink C2C頻寬1.8TB/s - 系統記憶體1.5TB(為Grace的3倍) - LPDDR5X頻寬1.2TB/s - 2270億個電晶體
這6款晶片分別是: 1. Vera CPU: - 88個NVIDIA客製Olympus核心 - 採用NVIDIA空間多執行緒技術,支援176個執行緒 - NVLink C2C頻寬1.8TB/s - 系統記憶體1.5TB(為Grace的3倍) - LPDDR5X頻寬1.2TB/s - 2270億個電晶體  2. Rubin GPU: - NVFP4推理算力50PFLOPS,是前代Blackwell的5倍 - 擁有3360億電晶體,比Blackwell電晶體數量增加了1.6倍 - 搭載第三代Transformer引擎,能根據Transformer模型需求動態調整精度
2. Rubin GPU: - NVFP4推理算力50PFLOPS,是前代Blackwell的5倍 - 擁有3360億電晶體,比Blackwell電晶體數量增加了1.6倍 - 搭載第三代Transformer引擎,能根據Transformer模型需求動態調整精度  3. ConnectX-9 網卡: - 基於200G PAM4 SerDes的800Gb/s乙太網 - 可程式化RDMA與資料通路加速器 - 通過CNSA與FIPS認證 - 230億個電晶體
3. ConnectX-9 網卡: - 基於200G PAM4 SerDes的800Gb/s乙太網 - 可程式化RDMA與資料通路加速器 - 通過CNSA與FIPS認證 - 230億個電晶體  4. BlueField-4 DPU: - 專為新一代AI儲存平台而構建的端到端引擎 - 面向SmartNIC與儲存處理器的800G Gb/s DPU - 搭配ConnectX-9的64核Grace CPU - 1260億個電晶體
4. BlueField-4 DPU: - 專為新一代AI儲存平台而構建的端到端引擎 - 面向SmartNIC與儲存處理器的800G Gb/s DPU - 搭配ConnectX-9的64核Grace CPU - 1260億個電晶體  5. NVLink-6 交換晶片: - 連接18個運算節點,支援最多72個Rubin GPU像一個整體協同運作 - 在NVLink 6架構下,每個GPU可獲得3.6TB每秒的all-to-all通訊頻寬 - 採用400G SerDes,支援In-Network SHARP Collectives,可在交換網路內部完成集合通訊操作
5. NVLink-6 交換晶片: - 連接18個運算節點,支援最多72個Rubin GPU像一個整體協同運作 - 在NVLink 6架構下,每個GPU可獲得3.6TB每秒的all-to-all通訊頻寬 - 採用400G SerDes,支援In-Network SHARP Collectives,可在交換網路內部完成集合通訊操作  6. Spectrum-6 光乙太網交換晶片 - 512通道,每通道200Gbps,實現更高速資料傳輸 - 整合台積電COOP工藝的矽光子技術 - 配備共封裝光學介面(copackaged optics) - 3520億個電晶體
6. Spectrum-6 光乙太網交換晶片 - 512通道,每通道200Gbps,實現更高速資料傳輸 - 整合台積電COOP工藝的矽光子技術 - 配備共封裝光學介面(copackaged optics) - 3520億個電晶體  透過6款晶片的深度整合,Vera Rubin NVL72系統效能比上一代Blackwell實現了全方位的提升。 在NVFP4推理任務中,該晶片達到了3.6 EFLOPS的驚人算力,相比上一代Blackwell架構提升了5倍。在NVFP4訓練方面,效能達到2.5 EFLOPS,實現3.5倍的效能提升。 儲存容量方面,NVL72配備了54TB的LPDDR5X記憶體,是前代產品的3倍。HBM(高頻寬記憶體)容量達到20.7TB,提升1.5倍。在頻寬效能上,HBM4頻寬達到1.6PB/s,提升2.8倍;Scale-Up頻寬更是高達260TB/s,實現了2倍成長。 儘管效能提升如此巨大,電晶體數量只增加了1.7倍,達到220兆個,展現了半導體製造技術上的創新能力。
透過6款晶片的深度整合,Vera Rubin NVL72系統效能比上一代Blackwell實現了全方位的提升。 在NVFP4推理任務中,該晶片達到了3.6 EFLOPS的驚人算力,相比上一代Blackwell架構提升了5倍。在NVFP4訓練方面,效能達到2.5 EFLOPS,實現3.5倍的效能提升。 儲存容量方面,NVL72配備了54TB的LPDDR5X記憶體,是前代產品的3倍。HBM(高頻寬記憶體)容量達到20.7TB,提升1.5倍。在頻寬效能上,HBM4頻寬達到1.6PB/s,提升2.8倍;Scale-Up頻寬更是高達260TB/s,實現了2倍成長。 儘管效能提升如此巨大,電晶體數量只增加了1.7倍,達到220兆個,展現了半導體製造技術上的創新能力。  工程設計上,Vera Rubin同樣帶來了技術突破。 以前的超算節點要接43根線纜,組裝要2小時,還容易裝錯。現在Vera Rubin節點採用0根線纜,只有6根液冷管線,5分鐘搞定。 更誇張的是,機架後面布滿了總長近3.2公里的銅纜,5000根銅纜構成NVLink主幹網路,實現400Gbps傳輸速度,用老黃的話來說:「可能有幾百磅重,你得是體格很好的CEO才能勝任這份工作」。 在AI圈裡時間就是金錢,一個關鍵數據是,訓練一個10兆參數模型,Rubin只需Blackwell系統數量的1/4,生成一個Token的成本約為Blackwell的1/10。
工程設計上,Vera Rubin同樣帶來了技術突破。 以前的超算節點要接43根線纜,組裝要2小時,還容易裝錯。現在Vera Rubin節點採用0根線纜,只有6根液冷管線,5分鐘搞定。 更誇張的是,機架後面布滿了總長近3.2公里的銅纜,5000根銅纜構成NVLink主幹網路,實現400Gbps傳輸速度,用老黃的話來說:「可能有幾百磅重,你得是體格很好的CEO才能勝任這份工作」。 在AI圈裡時間就是金錢,一個關鍵數據是,訓練一個10兆參數模型,Rubin只需Blackwell系統數量的1/4,生成一個Token的成本約為Blackwell的1/10。 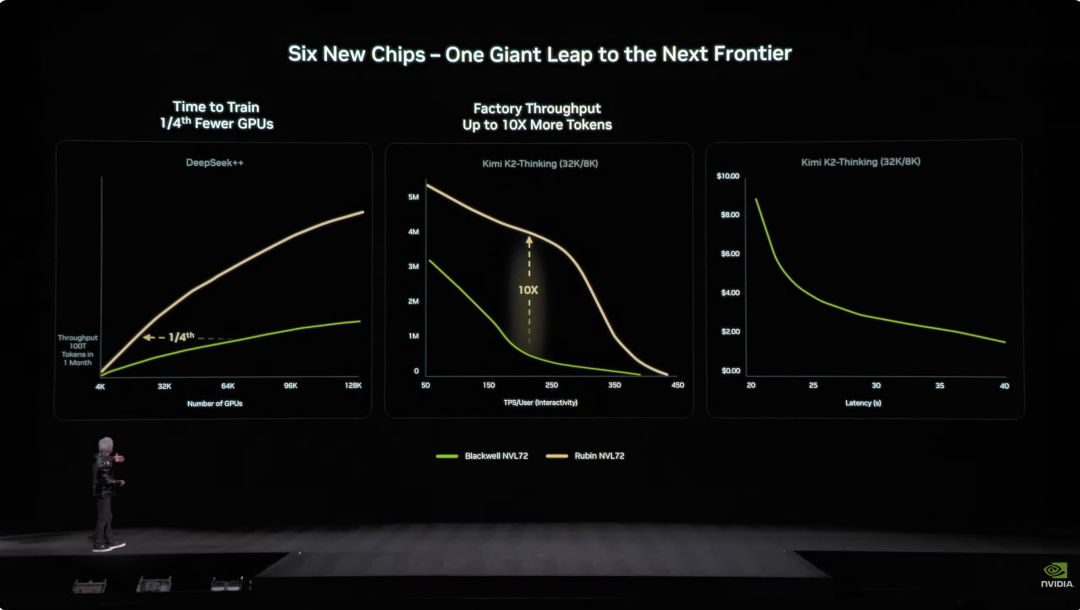 此外,雖然Rubin的功耗是Grace Blackwell的2倍,但效能提升遠超功耗增長,整體推理效能提升5倍,訓練效能提升3.5倍。 更重要的是,Rubin相比Blackwell吞吐量(每瓦-每美元可完成的AI Token數)提升10倍,對於造價500億美元的千兆瓦資料中心來說,這意味著營收能力將迎來直接翻倍。 過去AI產業的最大痛點是,上下文記憶體不夠用。具體來說,AI在工作時會產生「KV Cache」(鍵值快取),這是AI的「工作記憶」。問題是,隨著對話變長、模型變大,HBM記憶體顯得有些捉襟見肘。
此外,雖然Rubin的功耗是Grace Blackwell的2倍,但效能提升遠超功耗增長,整體推理效能提升5倍,訓練效能提升3.5倍。 更重要的是,Rubin相比Blackwell吞吐量(每瓦-每美元可完成的AI Token數)提升10倍,對於造價500億美元的千兆瓦資料中心來說,這意味著營收能力將迎來直接翻倍。 過去AI產業的最大痛點是,上下文記憶體不夠用。具體來說,AI在工作時會產生「KV Cache」(鍵值快取),這是AI的「工作記憶」。問題是,隨著對話變長、模型變大,HBM記憶體顯得有些捉襟見肘。  去年NVIDIA推出Grace-Blackwell架構擴展記憶體,但還是不夠。而Vera Rubin的方案是在機架內部署BlueField-4處理器,專門管理KV Cache。 每個節點配4個BlueField-4,每個背後有150TB上下文記憶體,分配到GPU上,每塊GPU額外獲得16TB記憶體——而GPU自帶記憶體只有約1TB,關鍵是頻寬保持200Gbps,速度不打折。 但僅有容量還不夠,要讓分布在幾十個機架、上萬塊GPU上的「便簽」像同一塊記憶體那樣協同,網路必須同時做到「夠大、夠快、夠穩」。這就輪到Spectrum-X登場了。 Spectrum-X是NVIDIA推出的全球首款「專為生成式AI設計」的端到端乙太網路平台,最新一代的Spectrum-X採用台積電COOP工藝,整合矽光子技術,512通道×200Gbps速率。 老黃算了筆帳:一個千兆瓦資料中心造價500億美元,Spectrum-X能帶來25%吞吐提升,相當於節省50億美元。「你可以說這個網路系統幾乎是『白送』的。」 安全方面,Vera Rubin還支援保密運算(Confidential Computing)。所有資料在傳輸、儲存、運算過程中全程加密,包括PCIe通道、NVLink、CPU-GPU通訊等所有匯流排。 企業可以放心把自己的模型部署到外部系統,不用擔心資料外洩。 DeepSeek震驚了世界,開源和智能體是AI主流 重頭戲看完,回到演講開始。黃仁勳一上台就拋出了一個驚人的數字,過去十年投入的約10兆美元運算資源,正在被徹底現代化。 但這不僅僅是硬體的升級,更多的是軟體範式的轉移。他特別提到了具備自主行為能力(Agentic)的智能體模型,並點名了Cursor,徹底改變了NVIDIA內部的編程方式。
去年NVIDIA推出Grace-Blackwell架構擴展記憶體,但還是不夠。而Vera Rubin的方案是在機架內部署BlueField-4處理器,專門管理KV Cache。 每個節點配4個BlueField-4,每個背後有150TB上下文記憶體,分配到GPU上,每塊GPU額外獲得16TB記憶體——而GPU自帶記憶體只有約1TB,關鍵是頻寬保持200Gbps,速度不打折。 但僅有容量還不夠,要讓分布在幾十個機架、上萬塊GPU上的「便簽」像同一塊記憶體那樣協同,網路必須同時做到「夠大、夠快、夠穩」。這就輪到Spectrum-X登場了。 Spectrum-X是NVIDIA推出的全球首款「專為生成式AI設計」的端到端乙太網路平台,最新一代的Spectrum-X採用台積電COOP工藝,整合矽光子技術,512通道×200Gbps速率。 老黃算了筆帳:一個千兆瓦資料中心造價500億美元,Spectrum-X能帶來25%吞吐提升,相當於節省50億美元。「你可以說這個網路系統幾乎是『白送』的。」 安全方面,Vera Rubin還支援保密運算(Confidential Computing)。所有資料在傳輸、儲存、運算過程中全程加密,包括PCIe通道、NVLink、CPU-GPU通訊等所有匯流排。 企業可以放心把自己的模型部署到外部系統,不用擔心資料外洩。 DeepSeek震驚了世界,開源和智能體是AI主流 重頭戲看完,回到演講開始。黃仁勳一上台就拋出了一個驚人的數字,過去十年投入的約10兆美元運算資源,正在被徹底現代化。 但這不僅僅是硬體的升級,更多的是軟體範式的轉移。他特別提到了具備自主行為能力(Agentic)的智能體模型,並點名了Cursor,徹底改變了NVIDIA內部的編程方式。 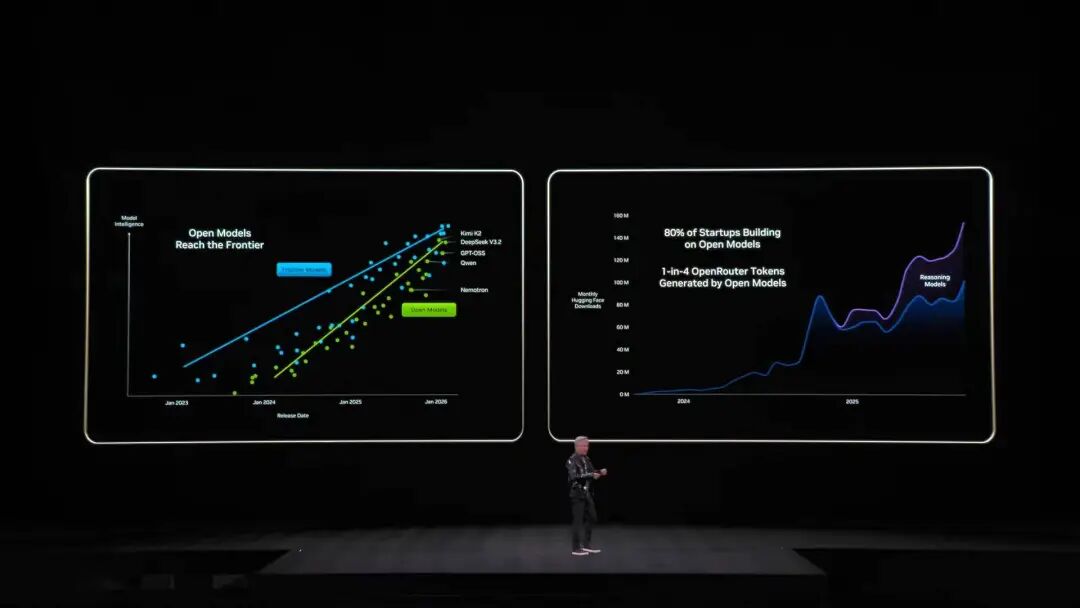 最讓現場沸騰的,是他對開源社群的高度評價。黃仁勳直言,去年DeepSeek V1的突破讓全世界感到意外,它作為第一個開源推理系統,直接激發了整個產業的發展浪潮。PPT上,我們熟悉的國產玩家Kimi k2和DeepSeek V3.2分別是開源第一和第二。 黃仁勳認為,雖然開源模型目前可能落後最頂尖模型約六個月,但每隔六個月就會出現一個新模型。 這種迭代速度讓新創公司、巨頭、研究人員都不願錯過,包括NVIDIA在內。 所以,他們這次也沒有只賣鏟子,推銷顯示卡;NVIDIA構建了價值數十億美元的DGX Cloud超級電腦,開發了像La Proteina(蛋白質合成)和OpenFold 3這樣的前沿模型。
最讓現場沸騰的,是他對開源社群的高度評價。黃仁勳直言,去年DeepSeek V1的突破讓全世界感到意外,它作為第一個開源推理系統,直接激發了整個產業的發展浪潮。PPT上,我們熟悉的國產玩家Kimi k2和DeepSeek V3.2分別是開源第一和第二。 黃仁勳認為,雖然開源模型目前可能落後最頂尖模型約六個月,但每隔六個月就會出現一個新模型。 這種迭代速度讓新創公司、巨頭、研究人員都不願錯過,包括NVIDIA在內。 所以,他們這次也沒有只賣鏟子,推銷顯示卡;NVIDIA構建了價值數十億美元的DGX Cloud超級電腦,開發了像La Proteina(蛋白質合成)和OpenFold 3這樣的前沿模型。  NVIDIA開源模型生態系統,涵蓋了生物醫藥、物理AI、智能體模型、機器人以及自動駕駛等 而NVIDIA Nemotron模型家族的多款開源模型,也成為這次演講的亮點。其中包含語音、多模態、檢索生成增強以及安全等多個方面的開源模型,黃仁勳也提到,Nemotron開源模型在多個測試榜單上表現優秀,並且正在被大量的企業採用。 物理AI是什麼,一口氣連發數十款模型 如果說大語言模型解決了「數位世界」的問題,那麼NVIDIA的下個野心,很明顯是要征服「物理世界」。黃仁勳提到,要讓AI理解物理法則,並在現實中生存,資料是極其稀缺的。 在智能體開源模型Nemotron之外,他提出了構建物理AI(Physical AI)的「三台電腦」核心架構。
NVIDIA開源模型生態系統,涵蓋了生物醫藥、物理AI、智能體模型、機器人以及自動駕駛等 而NVIDIA Nemotron模型家族的多款開源模型,也成為這次演講的亮點。其中包含語音、多模態、檢索生成增強以及安全等多個方面的開源模型,黃仁勳也提到,Nemotron開源模型在多個測試榜單上表現優秀,並且正在被大量的企業採用。 物理AI是什麼,一口氣連發數十款模型 如果說大語言模型解決了「數位世界」的問題,那麼NVIDIA的下個野心,很明顯是要征服「物理世界」。黃仁勳提到,要讓AI理解物理法則,並在現實中生存,資料是極其稀缺的。 在智能體開源模型Nemotron之外,他提出了構建物理AI(Physical AI)的「三台電腦」核心架構。 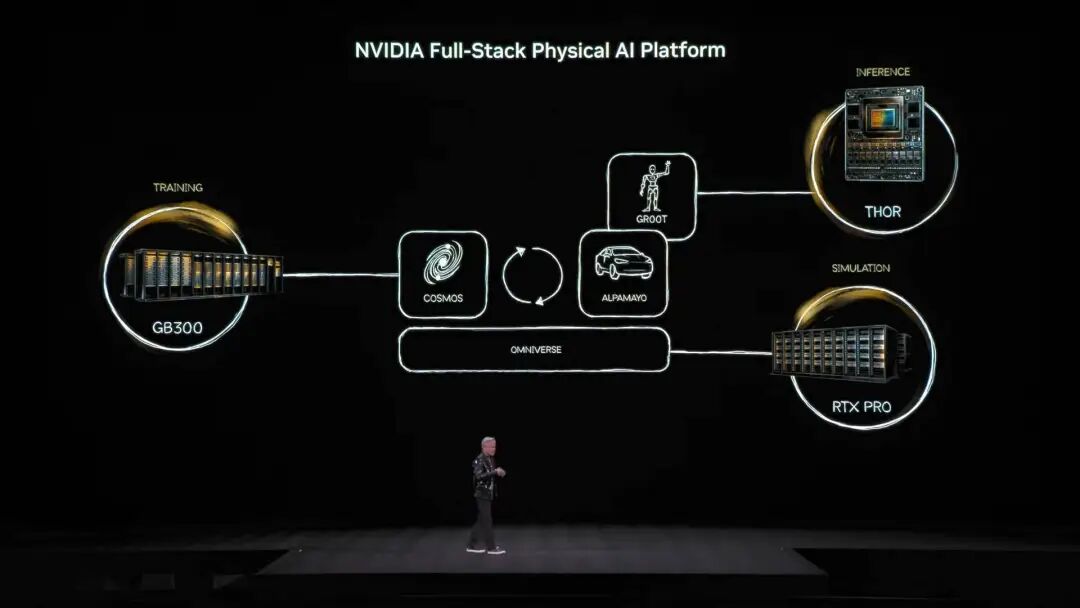
訓練電腦,也就是我們熟知的,由各種訓練級顯示卡構建的電腦,像圖片中提到的GB300架構。
推理電腦,運行在機器人或汽車邊緣端的「小腦」,負責即時執行。
模擬電腦,包括Omniverse和Cosmos,它能為AI提供一個虛擬的訓練環境,讓它在模擬中學習物理反饋。 Cosmos系統能生成大量的物理世界AI訓練環境 基於這套架構,黃仁勳正式發佈了震驚全場的Alpamayo,全球首個具備思考和推理能力的自動駕駛模型。
Cosmos系統能生成大量的物理世界AI訓練環境 基於這套架構,黃仁勳正式發佈了震驚全場的Alpamayo,全球首個具備思考和推理能力的自動駕駛模型。  與傳統自動駕駛不同,Alpamayo是端到端訓練的系統。它的突破性在於解決了自動駕駛的「長尾問題」。面對從未見過的複雜路況,Alpamayo不再是死板地執行程式碼,而是能像人類駕駛一樣進行推理。 「它會告訴你接下來會做什麼,以及它為什麼會做出這樣的決策」。在演示中,車輛的駕駛方式驚人地自然,能夠將極端複雜的場景,拆解為基礎常識來處理。 演示之外,這一切也不是紙上談兵。黃仁勳宣布,搭載Alpamayo技術棧的賓士CLA,將在今年第一季度於美國正式上線,隨後陸續登陸歐洲和亞洲市場。
與傳統自動駕駛不同,Alpamayo是端到端訓練的系統。它的突破性在於解決了自動駕駛的「長尾問題」。面對從未見過的複雜路況,Alpamayo不再是死板地執行程式碼,而是能像人類駕駛一樣進行推理。 「它會告訴你接下來會做什麼,以及它為什麼會做出這樣的決策」。在演示中,車輛的駕駛方式驚人地自然,能夠將極端複雜的場景,拆解為基礎常識來處理。 演示之外,這一切也不是紙上談兵。黃仁勳宣布,搭載Alpamayo技術棧的賓士CLA,將在今年第一季度於美國正式上線,隨後陸續登陸歐洲和亞洲市場。  這輛車被NCAP評為全球最安全的汽車,底氣就是來自於NVIDIA獨特的「雙重安全棧」設計。當端到端的AI模型對路況信心不足時,系統會立即切換回傳統的、更穩妥的安全防護模式,確保絕對安全。 發布會上,老黃還特地展示了NVIDIA的機器人戰略。
這輛車被NCAP評為全球最安全的汽車,底氣就是來自於NVIDIA獨特的「雙重安全棧」設計。當端到端的AI模型對路況信心不足時,系統會立即切換回傳統的、更穩妥的安全防護模式,確保絕對安全。 發布會上,老黃還特地展示了NVIDIA的機器人戰略。 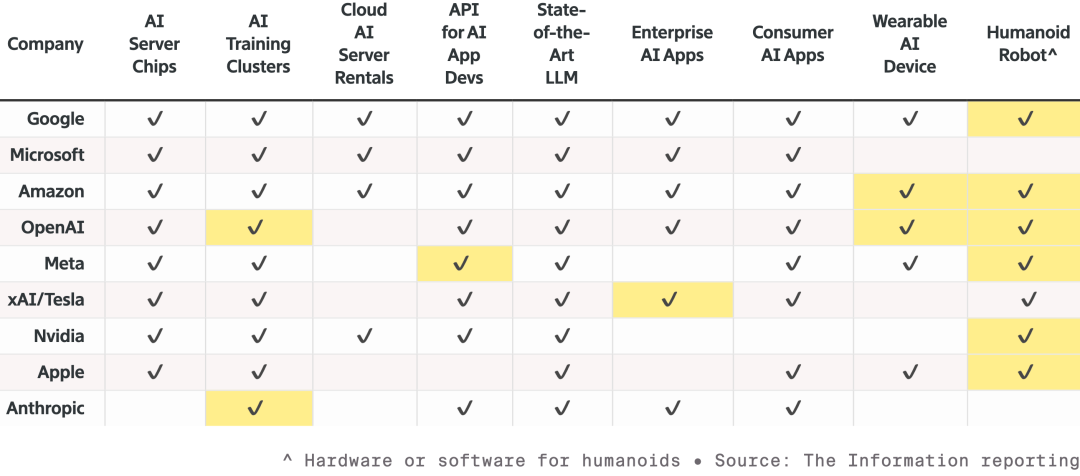 九大頂級AI及相關硬體製造商之間的競爭,他們都在擴大產品線,尤其是要搶奪機器人賽道,高亮的單元格為自去年以來的新產品 所有機器人都將搭載Jetson小型電腦,在Omniverse平台的Isaac模擬器中接受訓練。並且NVIDIA正在把這套技術整合進Synopsys、Cadence、西門子等工業體系。
九大頂級AI及相關硬體製造商之間的競爭,他們都在擴大產品線,尤其是要搶奪機器人賽道,高亮的單元格為自去年以來的新產品 所有機器人都將搭載Jetson小型電腦,在Omniverse平台的Isaac模擬器中接受訓練。並且NVIDIA正在把這套技術整合進Synopsys、Cadence、西門子等工業體系。  黃仁勳邀請了包括波士頓動力、Agility等人形機器人、四足機器人「登台」,他強調,最大的機器人其實是工廠本身 自下而上,NVIDIA的願景是,未來晶片設計、系統設計、工廠模擬,都將由NVIDIA物理AI加速。發布上,又是迪士尼機器人閃亮登場,老黃還因此對著這群超萌機器人調侃道: 「你們會在電腦中被設計、在電腦中被製造,甚至在真正面對重力之前,就會在電腦中被測試和驗證。」
黃仁勳邀請了包括波士頓動力、Agility等人形機器人、四足機器人「登台」,他強調,最大的機器人其實是工廠本身 自下而上,NVIDIA的願景是,未來晶片設計、系統設計、工廠模擬,都將由NVIDIA物理AI加速。發布上,又是迪士尼機器人閃亮登場,老黃還因此對著這群超萌機器人調侃道: 「你們會在電腦中被設計、在電腦中被製造,甚至在真正面對重力之前,就會在電腦中被測試和驗證。」  如果不說是黃仁勳,整場主題演講看下來甚至會以為是某個模型廠商的發布會。 在AI泡沫論甚囂塵上的今天,除了摩爾定律的放緩,黃仁勳似乎也需要用AI到底能做什麼,來提升我們每個人對AI的信心。 除了發布全新AI超算平台Vera Rubin的強悍效能,來安撫算力飢渴,他在應用和軟體上也比以往花了更多的功夫,拼盡全力讓我們看到,AI將會帶來哪些直觀改變。 此外,就像黃仁勳說的一樣,過去他們為虛擬世界造芯,現在他們也下場親自演示,將注意力放在以自動駕駛、人形機器人為代表的物理AI,走進產業競爭更激烈的真實物理世界。 畢竟,只有戰爭開打,軍火才能持續賣下去。 *最後,送上彩蛋影片:因為CES演講時間限制,黃仁勳有很多頁PPT來不及講。於是,他乾脆把沒放出來的PPT做了一條搞笑短片。請欣賞⬇️
如果不說是黃仁勳,整場主題演講看下來甚至會以為是某個模型廠商的發布會。 在AI泡沫論甚囂塵上的今天,除了摩爾定律的放緩,黃仁勳似乎也需要用AI到底能做什麼,來提升我們每個人對AI的信心。 除了發布全新AI超算平台Vera Rubin的強悍效能,來安撫算力飢渴,他在應用和軟體上也比以往花了更多的功夫,拼盡全力讓我們看到,AI將會帶來哪些直觀改變。 此外,就像黃仁勳說的一樣,過去他們為虛擬世界造芯,現在他們也下場親自演示,將注意力放在以自動駕駛、人形機器人為代表的物理AI,走進產業競爭更激烈的真實物理世界。 畢竟,只有戰爭開打,軍火才能持續賣下去。 *最後,送上彩蛋影片:因為CES演講時間限制,黃仁勳有很多頁PPT來不及講。於是,他乾脆把沒放出來的PPT做了一條搞笑短片。請欣賞⬇️ 
與去年單獨主旨演講不同,2026年的黃仁勳密集趕場。從NVIDIA Live到西門子工業AI對話,再到聯想TechWorld大會,48小時內橫跨三場活動。 上一次,他在CES發表了RTX 50系列顯示卡。而這一次,物理AI、機器人技術,以及一台重達2.5噸的「 企業級核彈 」,成為了真正的主角。 Vera Rubin運算平台登場,依舊是買越多省越多 發布會期間,愛搞創意的老黃直接把一台2.5噸重的AI伺服器機架搬上舞台,也因此引出了本次發布會的重點:Vera Rubin運算平台,以發現暗物質的天文學家命名,目標只有一個: 加速AI訓練的速度,讓下一代模型提前到來。 通常來說,NVIDIA內部有個規矩:每代產品最多只改1-2顆晶片。 但這次Vera Rubin打破了常規,一口氣重新設計了6款晶片,並已全面進入量產階段。 究其原因,隨著摩爾定律的放緩,傳統效能提升方式已經跟不上AI模型每年10倍的增長速度,所以NVIDIA選擇了「極致協同設計」——在所有晶片、整個平台各個層級上同時創新。
這6款晶片分別是: 1. Vera CPU: - 88個NVIDIA客製Olympus核心 - 採用NVIDIA空間多執行緒技術,支援176個執行緒 - NVLink C2C頻寬1.8TB/s - 系統記憶體1.5TB(為Grace的3倍) - LPDDR5X頻寬1.2TB/s - 2270億個電晶體 2. Rubin GPU: - NVFP4推理算力50PFLOPS,是前代Blackwell的5倍 - 擁有3360億電晶體,比Blackwell電晶體數量增加了1.6倍 - 搭載第三代Transformer引擎,能根據Transformer模型需求動態調整精度 3. ConnectX-9 網卡: - 基於200G PAM4 SerDes的800Gb/s乙太網 - 可程式化RDMA與資料通路加速器 - 通過CNSA與FIPS認證 - 230億個電晶體 4. BlueField-4 DPU: - 專為新一代AI儲存平台而構建的端到端引擎 - 面向SmartNIC與儲存處理器的800G Gb/s DPU - 搭配ConnectX-9的64核Grace CPU - 1260億個電晶體 5. NVLink-6 交換晶片: - 連接18個運算節點,支援最多72個Rubin GPU像一個整體協同運作 - 在NVLink 6架構下,每個GPU可獲得3.6TB每秒的all-to-all通訊頻寬 - 採用400G SerDes,支援In-Network SHARP Collectives,可在交換網路內部完成集合通訊操作 6. Spectrum-6 光乙太網交換晶片 - 512通道,每通道200Gbps,實現更高速資料傳輸 - 整合台積電COOP工藝的矽光子技術 - 配備共封裝光學介面(copackaged optics) - 3520億個電晶體 透過6款晶片的深度整合,Vera Rubin NVL72系統效能比上一代Blackwell實現了全方位的提升。 在NVFP4推理任務中,該晶片達到了3.6 EFLOPS的驚人算力,相比上一代Blackwell架構提升了5倍。在NVFP4訓練方面,效能達到2.5 EFLOPS,實現3.5倍的效能提升。 儲存容量方面,NVL72配備了54TB的LPDDR5X記憶體,是前代產品的3倍。HBM(高頻寬記憶體)容量達到20.7TB,提升1.5倍。在頻寬效能上,HBM4頻寬達到1.6PB/s,提升2.8倍;Scale-Up頻寬更是高達260TB/s,實現了2倍成長。 儘管效能提升如此巨大,電晶體數量只增加了1.7倍,達到220兆個,展現了半導體製造技術上的創新能力。 工程設計上,Vera Rubin同樣帶來了技術突破。 以前的超算節點要接43根線纜,組裝要2小時,還容易裝錯。現在Vera Rubin節點採用0根線纜,只有6根液冷管線,5分鐘搞定。 更誇張的是,機架後面布滿了總長近3.2公里的銅纜,5000根銅纜構成NVLink主幹網路,實現400Gbps傳輸速度,用老黃的話來說:「可能有幾百磅重,你得是體格很好的CEO才能勝任這份工作」。 在AI圈裡時間就是金錢,一個關鍵數據是,訓練一個10兆參數模型,Rubin只需Blackwell系統數量的1/4,生成一個Token的成本約為Blackwell的1/10。 此外,雖然Rubin的功耗是Grace Blackwell的2倍,但效能提升遠超功耗增長,整體推理效能提升5倍,訓練效能提升3.5倍。 更重要的是,Rubin相比Blackwell吞吐量(每瓦-每美元可完成的AI Token數)提升10倍,對於造價500億美元的千兆瓦資料中心來說,這意味著營收能力將迎來直接翻倍。 過去AI產業的最大痛點是,上下文記憶體不夠用。具體來說,AI在工作時會產生「KV Cache」(鍵值快取),這是AI的「工作記憶」。問題是,隨著對話變長、模型變大,HBM記憶體顯得有些捉襟見肘。 去年NVIDIA推出Grace-Blackwell架構擴展記憶體,但還是不夠。而Vera Rubin的方案是在機架內部署BlueField-4處理器,專門管理KV Cache。 每個節點配4個BlueField-4,每個背後有150TB上下文記憶體,分配到GPU上,每塊GPU額外獲得16TB記憶體——而GPU自帶記憶體只有約1TB,關鍵是頻寬保持200Gbps,速度不打折。 但僅有容量還不夠,要讓分布在幾十個機架、上萬塊GPU上的「便簽」像同一塊記憶體那樣協同,網路必須同時做到「夠大、夠快、夠穩」。這就輪到Spectrum-X登場了。 Spectrum-X是NVIDIA推出的全球首款「專為生成式AI設計」的端到端乙太網路平台,最新一代的Spectrum-X採用台積電COOP工藝,整合矽光子技術,512通道×200Gbps速率。 老黃算了筆帳:一個千兆瓦資料中心造價500億美元,Spectrum-X能帶來25%吞吐提升,相當於節省50億美元。「你可以說這個網路系統幾乎是『白送』的。」 安全方面,Vera Rubin還支援保密運算(Confidential Computing)。所有資料在傳輸、儲存、運算過程中全程加密,包括PCIe通道、NVLink、CPU-GPU通訊等所有匯流排。 企業可以放心把自己的模型部署到外部系統,不用擔心資料外洩。 DeepSeek震驚了世界,開源和智能體是AI主流 重頭戲看完,回到演講開始。黃仁勳一上台就拋出了一個驚人的數字,過去十年投入的約10兆美元運算資源,正在被徹底現代化。 但這不僅僅是硬體的升級,更多的是軟體範式的轉移。他特別提到了具備自主行為能力(Agentic)的智能體模型,並點名了Cursor,徹底改變了NVIDIA內部的編程方式。 最讓現場沸騰的,是他對開源社群的高度評價。黃仁勳直言,去年DeepSeek V1的突破讓全世界感到意外,它作為第一個開源推理系統,直接激發了整個產業的發展浪潮。PPT上,我們熟悉的國產玩家Kimi k2和DeepSeek V3.2分別是開源第一和第二。 黃仁勳認為,雖然開源模型目前可能落後最頂尖模型約六個月,但每隔六個月就會出現一個新模型。 這種迭代速度讓新創公司、巨頭、研究人員都不願錯過,包括NVIDIA在內。 所以,他們這次也沒有只賣鏟子,推銷顯示卡;NVIDIA構建了價值數十億美元的DGX Cloud超級電腦,開發了像La Proteina(蛋白質合成)和OpenFold 3這樣的前沿模型。 NVIDIA開源模型生態系統,涵蓋了生物醫藥、物理AI、智能體模型、機器人以及自動駕駛等 而NVIDIA Nemotron模型家族的多款開源模型,也成為這次演講的亮點。其中包含語音、多模態、檢索生成增強以及安全等多個方面的開源模型,黃仁勳也提到,Nemotron開源模型在多個測試榜單上表現優秀,並且正在被大量的企業採用。 物理AI是什麼,一口氣連發數十款模型 如果說大語言模型解決了「數位世界」的問題,那麼NVIDIA的下個野心,很明顯是要征服「物理世界」。黃仁勳提到,要讓AI理解物理法則,並在現實中生存,資料是極其稀缺的。 在智能體開源模型Nemotron之外,他提出了構建物理AI(Physical AI)的「三台電腦」核心架構。 訓練電腦,也就是我們熟知的,由各種訓練級顯示卡構建的電腦,像圖片中提到的GB300架構。
推理電腦,運行在機器人或汽車邊緣端的「小腦」,負責即時執行。
模擬電腦,包括Omniverse和Cosmos,它能為AI提供一個虛擬的訓練環境,讓它在模擬中學習物理反饋。
Cosmos系統能生成大量的物理世界AI訓練環境 基於這套架構,黃仁勳正式發佈了震驚全場的Alpamayo,全球首個具備思考和推理能力的自動駕駛模型。 與傳統自動駕駛不同,Alpamayo是端到端訓練的系統。它的突破性在於解決了自動駕駛的「長尾問題」。面對從未見過的複雜路況,Alpamayo不再是死板地執行程式碼,而是能像人類駕駛一樣進行推理。 「它會告訴你接下來會做什麼,以及它為什麼會做出這樣的決策」。在演示中,車輛的駕駛方式驚人地自然,能夠將極端複雜的場景,拆解為基礎常識來處理。 演示之外,這一切也不是紙上談兵。黃仁勳宣布,搭載Alpamayo技術棧的賓士CLA,將在今年第一季度於美國正式上線,隨後陸續登陸歐洲和亞洲市場。 這輛車被NCAP評為全球最安全的汽車,底氣就是來自於NVIDIA獨特的「雙重安全棧」設計。當端到端的AI模型對路況信心不足時,系統會立即切換回傳統的、更穩妥的安全防護模式,確保絕對安全。 發布會上,老黃還特地展示了NVIDIA的機器人戰略。 九大頂級AI及相關硬體製造商之間的競爭,他們都在擴大產品線,尤其是要搶奪機器人賽道,高亮的單元格為自去年以來的新產品 所有機器人都將搭載Jetson小型電腦,在Omniverse平台的Isaac模擬器中接受訓練。並且NVIDIA正在把這套技術整合進Synopsys、Cadence、西門子等工業體系。 黃仁勳邀請了包括波士頓動力、Agility等人形機器人、四足機器人「登台」,他強調,最大的機器人其實是工廠本身 自下而上,NVIDIA的願景是,未來晶片設計、系統設計、工廠模擬,都將由NVIDIA物理AI加速。發布上,又是迪士尼機器人閃亮登場,老黃還因此對著這群超萌機器人調侃道: 「你們會在電腦中被設計、在電腦中被製造,甚至在真正面對重力之前,就會在電腦中被測試和驗證。」 如果不說是黃仁勳,整場主題演講看下來甚至會以為是某個模型廠商的發布會。 在AI泡沫論甚囂塵上的今天,除了摩爾定律的放緩,黃仁勳似乎也需要用AI到底能做什麼,來提升我們每個人對AI的信心。 除了發布全新AI超算平台Vera Rubin的強悍效能,來安撫算力飢渴,他在應用和軟體上也比以往花了更多的功夫,拼盡全力讓我們看到,AI將會帶來哪些直觀改變。 此外,就像黃仁勳說的一樣,過去他們為虛擬世界造芯,現在他們也下場親自演示,將注意力放在以自動駕駛、人形機器人為代表的物理AI,走進產業競爭更激烈的真實物理世界。 畢竟,只有戰爭開打,軍火才能持續賣下去。 *最後,送上彩蛋影片:因為CES演講時間限制,黃仁勳有很多頁PPT來不及講。於是,他乾脆把沒放出來的PPT做了一條搞笑短片。請欣賞⬇️ 0
0
免責聲明:文章中的所有內容僅代表作者的觀點,與本平台無關。用戶不應以本文作為投資決策的參考。
PoolX: 鎖倉獲得新代幣空投
不要錯過熱門新幣,且APR 高達 10%+
立即參與
您也可能喜歡
山寨幣動能增強,Ethereum領漲——更廣泛的採用即將到來嗎?
AMBCrypto•2026/01/18 23:04
川普對格陵蘭徵收關稅已徹底破壞歐盟的綏靖策略
101 finance•2026/01/18 22:38
歐洲理事會將召開緊急會議討論特朗普關稅及歐盟報復選項
Cointelegraph•2026/01/18 22:32
隨著Apple與Google合作以AI強化Siri,現在是投資AAPL股票的合適時機嗎?
101 finance•2026/01/18 22:05
加密貨幣價格
更多Bitcoin
BTC
$95,472.66
+0.40%
Ethereum
ETH
$3,348.55
+1.40%
Tether USDt
USDT
$0.9997
+0.01%
BNB
BNB
$950.79
+0.39%
XRP
XRP
$2.06
-0.20%
Solana
SOL
$142.63
-0.71%
USDC
USDC
$0.9999
+0.02%
TRON
TRX
$0.3202
+0.55%
Dogecoin
DOGE
$0.1376
-0.05%
Cardano
ADA
$0.3958
-0.11%
如何出售 PI
Bitget 上架 PI:在 Bitget 上快速購買或出售 PI!
立即交易
還不是 Bitget 用戶嗎?新用戶可獲得價值 6,200 USDT 的�迎新大禮包
立即註冊