
الظهور الأول في عام 26، جنسن هوانغ يفجر المكان بـ"قنبلة نووية" تزن 2.5 طن|معرض الإلكترونيات الاستهلاكية CES2026

عرض النسخة الأصلية
By:爱范儿
*يوجد فيديو مفاجأة في النهاية. هذه هي المرة الأولى منذ خمس سنوات التي لم تعلن فيها NVIDIA عن بطاقة شاشة موجهة للمستهلكين في CES. تقدم الرئيس التنفيذي Jensen Huang نحو وسط مسرح NVIDIA Live بخطوات واثقة، مرتديًا نفس سترة جلد التمساح اللامعة التي ارتداها العام الماضي.  على عكس خطاب العام الماضي المنفرد، كان جدول Jensen Huang لعام 2026 مزدحمًا. من NVIDIA Live إلى حوار الذكاء الصناعي مع Siemens ثم مؤتمر Lenovo TechWorld، شارك في ثلاث فعاليات خلال 48 ساعة فقط. في المرة السابقة، أعلن عن سلسلة بطاقات RTX 50 في CES.أما هذه المرة، فقد كانت تقنيات الذكاء الاصطناعي الفيزيائي، والروبوتات، وجهاز " القنبلة النووية المؤسسية " التي تزن 2.5 طن، هي الحدث الرئيسي. ظهور منصة الحوسبة Vera Rubin، وكلما اشتريت أكثر وفرت أكثر خلال المؤتمر، قام Jensen Huang المعروف بحركاته الاستعراضية، بجلب خادم ذكاء صناعي يزن 2.5 طن إلى المسرح، ليكشف بذلك عن محور المؤتمر: منصة الحوسبة Vera Rubin، التي سُميت تيمنًا بعالمة الفلك التي اكتشفت المادة المظلمة وتهدف إلى هدف واحد فقط: تسريع سرعة تدريب الذكاء الاصطناعي، وجلب الجيل القادم من النماذج في وقت أبكر.
على عكس خطاب العام الماضي المنفرد، كان جدول Jensen Huang لعام 2026 مزدحمًا. من NVIDIA Live إلى حوار الذكاء الصناعي مع Siemens ثم مؤتمر Lenovo TechWorld، شارك في ثلاث فعاليات خلال 48 ساعة فقط. في المرة السابقة، أعلن عن سلسلة بطاقات RTX 50 في CES.أما هذه المرة، فقد كانت تقنيات الذكاء الاصطناعي الفيزيائي، والروبوتات، وجهاز " القنبلة النووية المؤسسية " التي تزن 2.5 طن، هي الحدث الرئيسي. ظهور منصة الحوسبة Vera Rubin، وكلما اشتريت أكثر وفرت أكثر خلال المؤتمر، قام Jensen Huang المعروف بحركاته الاستعراضية، بجلب خادم ذكاء صناعي يزن 2.5 طن إلى المسرح، ليكشف بذلك عن محور المؤتمر: منصة الحوسبة Vera Rubin، التي سُميت تيمنًا بعالمة الفلك التي اكتشفت المادة المظلمة وتهدف إلى هدف واحد فقط: تسريع سرعة تدريب الذكاء الاصطناعي، وجلب الجيل القادم من النماذج في وقت أبكر.  عادة، لدى NVIDIA قاعدة: في كل جيل من المنتجات، يتم تعديل 1-2 شرائح فقط كحد أقصى. لكن Vera Rubin كسرت هذه القاعدة هذه المرة، حيث أعادت تصميم 6 شرائح دفعة واحدة، ودخلت جميعها مرحلة الإنتاج الضخم.
عادة، لدى NVIDIA قاعدة: في كل جيل من المنتجات، يتم تعديل 1-2 شرائح فقط كحد أقصى. لكن Vera Rubin كسرت هذه القاعدة هذه المرة، حيث أعادت تصميم 6 شرائح دفعة واحدة، ودخلت جميعها مرحلة الإنتاج الضخم.
والسبب في ذلك أنه مع تباطؤ قانون مور، لم تعد طرق تحسين الأداء التقليدية تواكب نمو نماذج الذكاء الاصطناعي بمعدل 10 أضعاف سنويًا، لذلك اختارت NVIDIA "تصميماً تعاونيًا متطرفًا" — أي الابتكار على جميع مستويات الشرائح والمنصة بالكامل في آن واحد. هذه الشرائح الست هي: 1. Vera CPU: - 88 نواة Olympus مخصصة من NVIDIA - تقنية المعالجة المتعددة الخيوط من NVIDIA، تدعم 176 خيط معالجة - عرض نطاق NVLink C2C يصل إلى 1.8 تيرابايت/ثانية - ذاكرة النظام 1.5 تيرابايت (ثلاثة أضعاف Grace) - عرض نطاق LPDDR5X يصل إلى 1.2 تيرابايت/ثانية - 227 مليار ترانزستور
هذه الشرائح الست هي: 1. Vera CPU: - 88 نواة Olympus مخصصة من NVIDIA - تقنية المعالجة المتعددة الخيوط من NVIDIA، تدعم 176 خيط معالجة - عرض نطاق NVLink C2C يصل إلى 1.8 تيرابايت/ثانية - ذاكرة النظام 1.5 تيرابايت (ثلاثة أضعاف Grace) - عرض نطاق LPDDR5X يصل إلى 1.2 تيرابايت/ثانية - 227 مليار ترانزستور  2. Rubin GPU: - قوة معالجة استنتاجية NVFP4 تبلغ 50 بيتافلوبس، خمسة أضعاف الجيل السابق Blackwell - 336 مليار ترانزستور، بزيادة 1.6 مرة عن Blackwell - مزود بمحرك Transformer من الجيل الثالث، قادر على ضبط الدقة ديناميكيًا وفقًا لاحتياجات نموذج Transformer
2. Rubin GPU: - قوة معالجة استنتاجية NVFP4 تبلغ 50 بيتافلوبس، خمسة أضعاف الجيل السابق Blackwell - 336 مليار ترانزستور، بزيادة 1.6 مرة عن Blackwell - مزود بمحرك Transformer من الجيل الثالث، قادر على ضبط الدقة ديناميكيًا وفقًا لاحتياجات نموذج Transformer  3. بطاقة الشبكة ConnectX-9: - إيثرنت بسرعة 800 جيجابت/ثانية مبنية على SerDes PAM4 بسرعة 200G - معجل RDMA ومسار بيانات قابل للبرمجة - معتمد من CNSA و FIPS - 23 مليار ترانزستور
3. بطاقة الشبكة ConnectX-9: - إيثرنت بسرعة 800 جيجابت/ثانية مبنية على SerDes PAM4 بسرعة 200G - معجل RDMA ومسار بيانات قابل للبرمجة - معتمد من CNSA و FIPS - 23 مليار ترانزستور  4. BlueField-4 DPU: - محرك شامل مصمم خصيصًا لمنصات تخزين الذكاء الاصطناعي من الجيل الجديد - DPU بسرعة 800G Gb/s موجهة لـ SmartNIC ومعالجات التخزين - مزود بـ 64 نواة Grace CPU متوافقة مع ConnectX-9 - 126 مليار ترانزستور
4. BlueField-4 DPU: - محرك شامل مصمم خصيصًا لمنصات تخزين الذكاء الاصطناعي من الجيل الجديد - DPU بسرعة 800G Gb/s موجهة لـ SmartNIC ومعالجات التخزين - مزود بـ 64 نواة Grace CPU متوافقة مع ConnectX-9 - 126 مليار ترانزستور  5. شريحة تبديل NVLink-6: - تربط 18 عقدة حوسبة، وتدعم ما يصل إلى 72 Rubin GPU للعمل كوحدة واحدة - في بنية NVLink 6، يمكن لكل GPU الحصول على 3.6 تيرابايت في الثانية من عرض النطاق الترددي للتواصل الشامل - تعتمد على SerDes بسرعة 400G، وتدعم In-Network SHARP Collectives، مما يتيح إجراء عمليات التواصل الجماعي داخل شبكة التبديل
5. شريحة تبديل NVLink-6: - تربط 18 عقدة حوسبة، وتدعم ما يصل إلى 72 Rubin GPU للعمل كوحدة واحدة - في بنية NVLink 6، يمكن لكل GPU الحصول على 3.6 تيرابايت في الثانية من عرض النطاق الترددي للتواصل الشامل - تعتمد على SerDes بسرعة 400G، وتدعم In-Network SHARP Collectives، مما يتيح إجراء عمليات التواصل الجماعي داخل شبكة التبديل  6. شريحة تبديل Spectrum-6 إيثرنت الضوئية - 512 قناة، كل قناة بسرعة 200 جيجابت/ثانية لنقل بيانات أسرع - مجهزة بتقنية السيليكون الضوئي من TSMC COOP - مزودة بواجهات بصرية مدمجة (copackaged optics) - 352 مليار ترانزستور
6. شريحة تبديل Spectrum-6 إيثرنت الضوئية - 512 قناة، كل قناة بسرعة 200 جيجابت/ثانية لنقل بيانات أسرع - مجهزة بتقنية السيليكون الضوئي من TSMC COOP - مزودة بواجهات بصرية مدمجة (copackaged optics) - 352 مليار ترانزستور  من خلال التكامل العميق بين هذه الشرائح الست، حقق نظام Vera Rubin NVL72 أداءً أعلى بكثير من الجيل السابق Blackwell في جميع الجوانب. في مهام الاستنتاج NVFP4، وصلت قوة معالجة هذه الشريحة إلى 3.6 إكسافلوبس، أي بزيادة قدرها 5 أضعاف عن بنية Blackwell السابقة. أما في تدريب NVFP4، فقد بلغ الأداء 2.5 إكسافلوبس، أي بزيادة 3.5 أضعاف. في ما يخص سعة التخزين، يأتي NVL72 مزودًا بذاكرة LPDDR5X بسعة 54 تيرابايت، أي ثلاثة أضعاف الجيل السابق. سعة HBM (الذاكرة ذات النطاق الترددي العالي) تبلغ 20.7 تيرابايت، بزيادة 1.5 مرة. أما في الأداء، فوصل عرض نطاق HBM4 إلى 1.6 بيتابايت/ثانية، بزيادة 2.8 مرة؛ بينما ارتفع عرض النطاق الترددي Scale-Up إلى 260 تيرابايت/ثانية، بزيادة بلغت الضعف. رغم هذا التحسن الهائل في الأداء، لم يزد عدد الترانزستورات إلا بمقدار 1.7 مرة ليصل إلى 220 تريليون، مما يظهر قدرة ابتكارية هائلة في تصنيع أشباه الموصلات.
من خلال التكامل العميق بين هذه الشرائح الست، حقق نظام Vera Rubin NVL72 أداءً أعلى بكثير من الجيل السابق Blackwell في جميع الجوانب. في مهام الاستنتاج NVFP4، وصلت قوة معالجة هذه الشريحة إلى 3.6 إكسافلوبس، أي بزيادة قدرها 5 أضعاف عن بنية Blackwell السابقة. أما في تدريب NVFP4، فقد بلغ الأداء 2.5 إكسافلوبس، أي بزيادة 3.5 أضعاف. في ما يخص سعة التخزين، يأتي NVL72 مزودًا بذاكرة LPDDR5X بسعة 54 تيرابايت، أي ثلاثة أضعاف الجيل السابق. سعة HBM (الذاكرة ذات النطاق الترددي العالي) تبلغ 20.7 تيرابايت، بزيادة 1.5 مرة. أما في الأداء، فوصل عرض نطاق HBM4 إلى 1.6 بيتابايت/ثانية، بزيادة 2.8 مرة؛ بينما ارتفع عرض النطاق الترددي Scale-Up إلى 260 تيرابايت/ثانية، بزيادة بلغت الضعف. رغم هذا التحسن الهائل في الأداء، لم يزد عدد الترانزستورات إلا بمقدار 1.7 مرة ليصل إلى 220 تريليون، مما يظهر قدرة ابتكارية هائلة في تصنيع أشباه الموصلات.  على مستوى التصميم الهندسي، قدمت Vera Rubin أيضًا اختراقًا تقنيًا. كان يتطلب توصيل عقدة الحوسبة الفائقة سابقًا 43 كابلًا، ويستغرق التجميع ساعتين مع احتمالية وقوع أخطاء. الآن، تستخدم عقدة Vera Rubin صفر كابلات، فقط 6 أنابيب تبريد سائل، ويستغرق التجميع 5 دقائق فقط. والأكثر إثارة أن الجزء الخلفي من الرف ممتلئ بكابلات نحاسية طولها الإجمالي 3.2 كيلومتر تقريبًا، 5000 كابل نحاسي يشكلون العمود الفقري لشبكة NVLink بسرعة نقل 400 جيجابت/ثانية، وكما قال Jensen Huang: "قد تزن عدة مئات من الأرطال، يجب أن تكون الرئيس التنفيذي بقوة بدنية جيدة لتناسب هذه الوظيفة". في عالم الذكاء الاصطناعي، الوقت يعني المال. تشير بيانات مهمة إلى أن تدريب نموذج يحتوي على 100 تريليون معلمة يتطلب من Rubin فقط ربع عدد أنظمة Blackwell، بينما تكلفة توليد Token واحدة تقارب عُشر تكلفة Blackwell.
على مستوى التصميم الهندسي، قدمت Vera Rubin أيضًا اختراقًا تقنيًا. كان يتطلب توصيل عقدة الحوسبة الفائقة سابقًا 43 كابلًا، ويستغرق التجميع ساعتين مع احتمالية وقوع أخطاء. الآن، تستخدم عقدة Vera Rubin صفر كابلات، فقط 6 أنابيب تبريد سائل، ويستغرق التجميع 5 دقائق فقط. والأكثر إثارة أن الجزء الخلفي من الرف ممتلئ بكابلات نحاسية طولها الإجمالي 3.2 كيلومتر تقريبًا، 5000 كابل نحاسي يشكلون العمود الفقري لشبكة NVLink بسرعة نقل 400 جيجابت/ثانية، وكما قال Jensen Huang: "قد تزن عدة مئات من الأرطال، يجب أن تكون الرئيس التنفيذي بقوة بدنية جيدة لتناسب هذه الوظيفة". في عالم الذكاء الاصطناعي، الوقت يعني المال. تشير بيانات مهمة إلى أن تدريب نموذج يحتوي على 100 تريليون معلمة يتطلب من Rubin فقط ربع عدد أنظمة Blackwell، بينما تكلفة توليد Token واحدة تقارب عُشر تكلفة Blackwell. 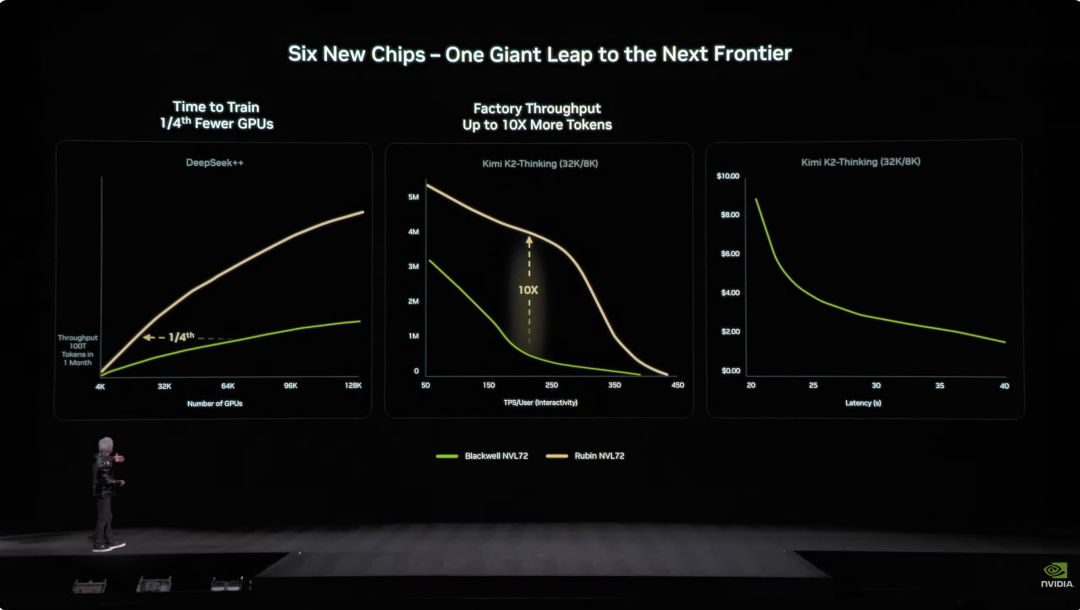 بالإضافة إلى ذلك، رغم أن استهلاك الطاقة في Rubin هو ضعف Grace Blackwell، إلا أن التحسن في الأداء يفوق الزيادة في الاستهلاك بكثير، حيث زاد الأداء الاستنتاجي 5 أضعاف والتدريبي 3.5 أضعاف. والأهم من ذلك، أن إنتاجية Rubin (عدد Tokens لكل واط-لكل دولار) ارتفعت بمقدار 10 أضعاف مقارنة بـ Blackwell، مما يعني أن مركز بيانات بسعة 1 جيجاوات وتكلفة 50 مليار دولار سيضاعف قدرته الربحية مباشرة. أكبر مشكلة في صناعة الذكاء الاصطناعي سابقًا كانت عدم توفر ذاكرة سياقية كافية. فعند عمل الذكاء الاصطناعي، ينشئ "KV Cache" (ذاكرة المفتاح والقيمة)، وهي بمثابة "ذاكرة العمل" للذكاء الاصطناعي. ومع زيادة حجم المحادثة والنموذج، أصبحت ذاكرة HBM غير كافية.
بالإضافة إلى ذلك، رغم أن استهلاك الطاقة في Rubin هو ضعف Grace Blackwell، إلا أن التحسن في الأداء يفوق الزيادة في الاستهلاك بكثير، حيث زاد الأداء الاستنتاجي 5 أضعاف والتدريبي 3.5 أضعاف. والأهم من ذلك، أن إنتاجية Rubin (عدد Tokens لكل واط-لكل دولار) ارتفعت بمقدار 10 أضعاف مقارنة بـ Blackwell، مما يعني أن مركز بيانات بسعة 1 جيجاوات وتكلفة 50 مليار دولار سيضاعف قدرته الربحية مباشرة. أكبر مشكلة في صناعة الذكاء الاصطناعي سابقًا كانت عدم توفر ذاكرة سياقية كافية. فعند عمل الذكاء الاصطناعي، ينشئ "KV Cache" (ذاكرة المفتاح والقيمة)، وهي بمثابة "ذاكرة العمل" للذكاء الاصطناعي. ومع زيادة حجم المحادثة والنموذج، أصبحت ذاكرة HBM غير كافية.  أطلقت NVIDIA العام الماضي بنية Grace-Blackwell لتوسيع الذاكرة، لكنها لم تكن كافية. أما حل Vera Rubin فهو نشر معالجات BlueField-4 داخل الرف لإدارة KV Cache تحديدًا. كل عقدة مزودة بـ 4 BlueField-4، وكل منها مزود بـ 150 تيرابايت من الذاكرة السياقية، توزع على وحدات GPU، ليحصل كل GPU على 16 تيرابايت إضافية — في حين أن ذاكرة GPU الأصلية حوالي 1 تيرابايت فقط، والأهم أن عرض النطاق يبقى عند 200 جيجابت/ثانية دون أي انخفاض في السرعة. لكن السعة وحدها لا تكفي، إذ يجب أن تتعاون "الملاحظات" الموزعة عبر عشرات الرفوف وآلاف وحدات GPU كما لو كانت ذاكرة واحدة، لذا يجب أن تكون الشبكة "كبيرة وسريعة ومستقرة" في آن واحد. وهنا يأتي دور Spectrum-X. Spectrum-X هو أول منصة شبكة إيثرنت شاملة في العالم "مصممة خصيصًا للذكاء الاصطناعي التوليدي"، ويعتمد الجيل الجديد من Spectrum-X على تقنية السيليكون الضوئي من TSMC COOP، مع 512 قناة × 200 جيجابت/ثانية. حسب حسابات Jensen Huang: مركز بيانات بسعة 1 جيجاوات يكلف 50 مليار دولار، ويمكن لـ Spectrum-X تحسين الإنتاجية بنسبة 25%، ما يعني توفير 5 مليارات دولار. "يمكنك القول إن هذا النظام الشبكي يكاد يكون مجانيًا". أما من الناحية الأمنية، تدعم Vera Rubin الحوسبة السرية (Confidential Computing)، حيث يتم تشفير جميع البيانات أثناء النقل والتخزين والمعالجة، بما في ذلك قنوات PCIe و NVLink والتواصل بين CPU و GPU وجميع الحافلات. يمكن للشركات نشر نماذجها على أنظمة خارجية دون القلق بشأن تسرب البيانات. DeepSeek أدهشت العالم، والمصادر المفتوحة والوكلاء هي الاتجاه السائد للذكاء الاصطناعي بعد العرض الرئيسي، نعود إلى بداية الخطاب. بمجرد صعود Jensen Huang إلى المسرح، أعلن رقمًا مذهلًا: تقدر الموارد الحاسوبية التي استُثمرت خلال العقد الماضي بـ 10 تريليون دولار، وهي في طور التحديث الجذري. لكن الأمر لا يتعلق فقط بترقية الأجهزة، بل أيضًا بتحول نماذج البرمجيات. فقد أشار بشكل خاص إلى نماذج الذكاء الاصطناعي القادرة على التصرف بشكل وكيل (Agentic) وذكر نموذج Cursor بالاسم، الذي غير طريقة البرمجة داخل NVIDIA بالكامل.
أطلقت NVIDIA العام الماضي بنية Grace-Blackwell لتوسيع الذاكرة، لكنها لم تكن كافية. أما حل Vera Rubin فهو نشر معالجات BlueField-4 داخل الرف لإدارة KV Cache تحديدًا. كل عقدة مزودة بـ 4 BlueField-4، وكل منها مزود بـ 150 تيرابايت من الذاكرة السياقية، توزع على وحدات GPU، ليحصل كل GPU على 16 تيرابايت إضافية — في حين أن ذاكرة GPU الأصلية حوالي 1 تيرابايت فقط، والأهم أن عرض النطاق يبقى عند 200 جيجابت/ثانية دون أي انخفاض في السرعة. لكن السعة وحدها لا تكفي، إذ يجب أن تتعاون "الملاحظات" الموزعة عبر عشرات الرفوف وآلاف وحدات GPU كما لو كانت ذاكرة واحدة، لذا يجب أن تكون الشبكة "كبيرة وسريعة ومستقرة" في آن واحد. وهنا يأتي دور Spectrum-X. Spectrum-X هو أول منصة شبكة إيثرنت شاملة في العالم "مصممة خصيصًا للذكاء الاصطناعي التوليدي"، ويعتمد الجيل الجديد من Spectrum-X على تقنية السيليكون الضوئي من TSMC COOP، مع 512 قناة × 200 جيجابت/ثانية. حسب حسابات Jensen Huang: مركز بيانات بسعة 1 جيجاوات يكلف 50 مليار دولار، ويمكن لـ Spectrum-X تحسين الإنتاجية بنسبة 25%، ما يعني توفير 5 مليارات دولار. "يمكنك القول إن هذا النظام الشبكي يكاد يكون مجانيًا". أما من الناحية الأمنية، تدعم Vera Rubin الحوسبة السرية (Confidential Computing)، حيث يتم تشفير جميع البيانات أثناء النقل والتخزين والمعالجة، بما في ذلك قنوات PCIe و NVLink والتواصل بين CPU و GPU وجميع الحافلات. يمكن للشركات نشر نماذجها على أنظمة خارجية دون القلق بشأن تسرب البيانات. DeepSeek أدهشت العالم، والمصادر المفتوحة والوكلاء هي الاتجاه السائد للذكاء الاصطناعي بعد العرض الرئيسي، نعود إلى بداية الخطاب. بمجرد صعود Jensen Huang إلى المسرح، أعلن رقمًا مذهلًا: تقدر الموارد الحاسوبية التي استُثمرت خلال العقد الماضي بـ 10 تريليون دولار، وهي في طور التحديث الجذري. لكن الأمر لا يتعلق فقط بترقية الأجهزة، بل أيضًا بتحول نماذج البرمجيات. فقد أشار بشكل خاص إلى نماذج الذكاء الاصطناعي القادرة على التصرف بشكل وكيل (Agentic) وذكر نموذج Cursor بالاسم، الذي غير طريقة البرمجة داخل NVIDIA بالكامل. 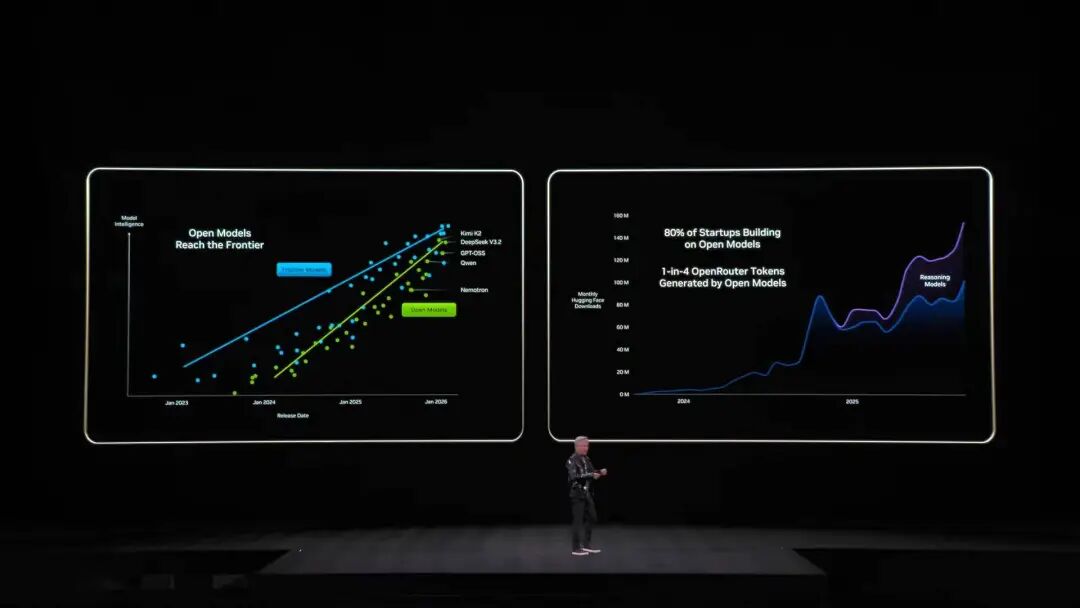 وكان أكثر ما أشعل الحضور هو تقييمه العالي لمجتمع المصادر المفتوحة. حيث قال صراحة إن اختراق DeepSeek V1 العام الماضي كان مفاجأة للعالم، إذ كان أول نظام استنتاج مفتوح المصدر، وأشعل موجة تطوير في الصناعة بأكملها. وعلى شريحة PPT، كان اللاعبان الصينيان Kimi k2 و DeepSeek V3.2 هما الأول والثاني في المصادر المفتوحة. يعتقد Jensen Huang أن نماذج المصادر المفتوحة قد تتأخر حاليًا عن النماذج الرائدة بحوالي ستة أشهر، لكن كل ستة أشهر يظهر نموذج جديد. هذا التسارع في التطور يدفع الشركات الناشئة والعمالقة والباحثين — بما فيهم NVIDIA — إلى عدم تفويت الفرصة. لذا، لم يكتفوا هذه المرة ببيع "المجرفة" أو تسويق بطاقات الشاشة؛ بل بنت NVIDIA حاسوبًا فائقًا في السحابة بقيمة مليارات الدولارات يسمى DGX Cloud، وطورت نماذج رائدة مثل La Proteina (تخليق البروتين) و OpenFold 3.
وكان أكثر ما أشعل الحضور هو تقييمه العالي لمجتمع المصادر المفتوحة. حيث قال صراحة إن اختراق DeepSeek V1 العام الماضي كان مفاجأة للعالم، إذ كان أول نظام استنتاج مفتوح المصدر، وأشعل موجة تطوير في الصناعة بأكملها. وعلى شريحة PPT، كان اللاعبان الصينيان Kimi k2 و DeepSeek V3.2 هما الأول والثاني في المصادر المفتوحة. يعتقد Jensen Huang أن نماذج المصادر المفتوحة قد تتأخر حاليًا عن النماذج الرائدة بحوالي ستة أشهر، لكن كل ستة أشهر يظهر نموذج جديد. هذا التسارع في التطور يدفع الشركات الناشئة والعمالقة والباحثين — بما فيهم NVIDIA — إلى عدم تفويت الفرصة. لذا، لم يكتفوا هذه المرة ببيع "المجرفة" أو تسويق بطاقات الشاشة؛ بل بنت NVIDIA حاسوبًا فائقًا في السحابة بقيمة مليارات الدولارات يسمى DGX Cloud، وطورت نماذج رائدة مثل La Proteina (تخليق البروتين) و OpenFold 3.  يغطي نظام نماذج المصادر المفتوحة من NVIDIA مجالات الطب الحيوي، والذكاء الاصطناعي الفيزيائي، ونماذج الوكلاء، والروبوتات، والقيادة الذاتية، وغيرها كما أن العديد من النماذج المفتوحة المصدر من عائلة نماذج NVIDIA Nemotron كانت من أبرز ما في هذا الخطاب. وتشمل هذه النماذج الصوت، والنماذج متعددة الوسائط، ونماذج الاسترجاع والتوليد المعزز، والنماذج الآمنة، حيث أشار Jensen Huang إلى أن نماذج Nemotron المفتوحة المصدر أحرزت نتائج ممتازة في العديد من قوائم الاختبار، وتبنتها العديد من الشركات. ما هو الذكاء الاصطناعي الفيزيائي؟ إصدار عشرات النماذج دفعة واحدة إذا كانت النماذج اللغوية الكبرى حلت مشاكل "العالم الرقمي"، فإن طموح NVIDIA التالي أصبح واضحًا: غزو "العالم الفيزيائي". أشار Jensen Huang إلى أنه لجعل الذكاء الاصطناعي يفهم قوانين الفيزياء ويعيش في الواقع، فإن البيانات شحيحة للغاية. وبالإضافة إلى نماذج الوكلاء المفتوحة المصدر Nemotron، قدم بنية أساسية لـ "ثلاثة حواسيب" لبناء الذكاء الاصطناعي الفيزيائي (Physical AI).
يغطي نظام نماذج المصادر المفتوحة من NVIDIA مجالات الطب الحيوي، والذكاء الاصطناعي الفيزيائي، ونماذج الوكلاء، والروبوتات، والقيادة الذاتية، وغيرها كما أن العديد من النماذج المفتوحة المصدر من عائلة نماذج NVIDIA Nemotron كانت من أبرز ما في هذا الخطاب. وتشمل هذه النماذج الصوت، والنماذج متعددة الوسائط، ونماذج الاسترجاع والتوليد المعزز، والنماذج الآمنة، حيث أشار Jensen Huang إلى أن نماذج Nemotron المفتوحة المصدر أحرزت نتائج ممتازة في العديد من قوائم الاختبار، وتبنتها العديد من الشركات. ما هو الذكاء الاصطناعي الفيزيائي؟ إصدار عشرات النماذج دفعة واحدة إذا كانت النماذج اللغوية الكبرى حلت مشاكل "العالم الرقمي"، فإن طموح NVIDIA التالي أصبح واضحًا: غزو "العالم الفيزيائي". أشار Jensen Huang إلى أنه لجعل الذكاء الاصطناعي يفهم قوانين الفيزياء ويعيش في الواقع، فإن البيانات شحيحة للغاية. وبالإضافة إلى نماذج الوكلاء المفتوحة المصدر Nemotron، قدم بنية أساسية لـ "ثلاثة حواسيب" لبناء الذكاء الاصطناعي الفيزيائي (Physical AI). 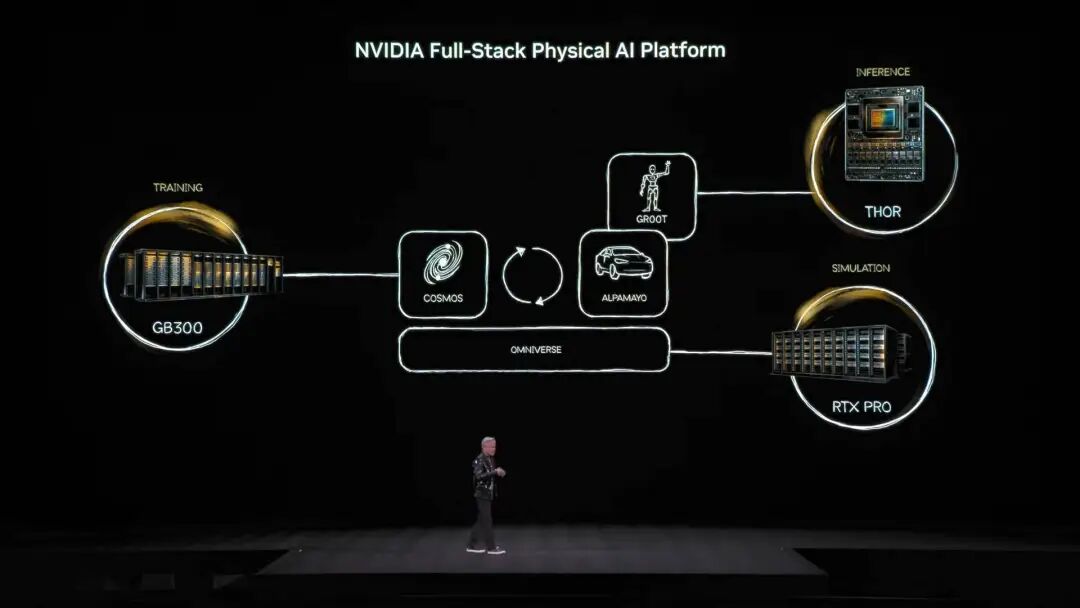
حاسوب التدريب، وهو الحاسوب الذي نعرفه، المبني من بطاقات الشاشة المخصصة للتدريب مثل بنية GB300 المذكورة في الصورة.
حاسوب الاستنتاج، وهو "المخيخ" الذي يعمل على أطراف الروبوت أو السيارة، مسؤول عن التنفيذ الفوري.
حاسوب المحاكاة، ويشمل Omniverse و Cosmos، حيث يوفر بيئة تدريب افتراضية للذكاء الاصطناعي ليتعلم منها التغذية الراجعة الفيزيائية. يستطيع نظام Cosmos إنشاء العديد من بيئات تدريب الذكاء الاصطناعي للعالم الفيزيائي استنادًا إلى هذه البنية، أعلن Jensen Huang رسميًا عن Alpamayo، أول نموذج قيادة ذاتية في العالم يتمتع بقدرة على التفكير والاستنتاج.
يستطيع نظام Cosmos إنشاء العديد من بيئات تدريب الذكاء الاصطناعي للعالم الفيزيائي استنادًا إلى هذه البنية، أعلن Jensen Huang رسميًا عن Alpamayo، أول نموذج قيادة ذاتية في العالم يتمتع بقدرة على التفكير والاستنتاج.  على عكس النماذج التقليدية للقيادة الذاتية، فإن Alpamayo هو نظام مدرَّب من طرف إلى طرف، وميزته الأساسية هي حل "مشكلة الذيل الطويل" في القيادة الذاتية. فعند مواجهة ظروف طريق معقدة وغير مسبوقة، لم يعد Alpamayo ينفذ الشيفرة حرفيًا، بل يستنتج كما يفعل السائق البشري. "سوف يخبرك بما سيفعله بعد ذلك ولماذا اتخذ هذا القرار." وأثناء العرض التوضيحي، كانت طريقة القيادة طبيعية بشكل مذهل، حيث قام النموذج بتقسيم المشاهد المعقدة للغاية إلى معارف أساسية للتعامل معها. وليس الأمر مجرد عرض نظري؛ فقد أعلن Jensen Huang أن سيارة Mercedes CLA المزودة بتقنية Alpamayo ستنطلق رسميًا في الولايات المتحدة خلال الربع الأول من هذا العام، ثم تتبعها أوروبا وآسيا.
على عكس النماذج التقليدية للقيادة الذاتية، فإن Alpamayo هو نظام مدرَّب من طرف إلى طرف، وميزته الأساسية هي حل "مشكلة الذيل الطويل" في القيادة الذاتية. فعند مواجهة ظروف طريق معقدة وغير مسبوقة، لم يعد Alpamayo ينفذ الشيفرة حرفيًا، بل يستنتج كما يفعل السائق البشري. "سوف يخبرك بما سيفعله بعد ذلك ولماذا اتخذ هذا القرار." وأثناء العرض التوضيحي، كانت طريقة القيادة طبيعية بشكل مذهل، حيث قام النموذج بتقسيم المشاهد المعقدة للغاية إلى معارف أساسية للتعامل معها. وليس الأمر مجرد عرض نظري؛ فقد أعلن Jensen Huang أن سيارة Mercedes CLA المزودة بتقنية Alpamayo ستنطلق رسميًا في الولايات المتحدة خلال الربع الأول من هذا العام، ثم تتبعها أوروبا وآسيا.  حصلت هذه السيارة على لقب أكثر السيارات أمانًا في العالم من NCAP، وذلك بفضل التصميم الفريد لـ NVIDIA المتمثل في "طبقة الأمان المزدوجة". فعندما يفقد نموذج الذكاء الاصطناعي الثقة في ظروف الطريق، يتحول النظام فورًا إلى وضع الأمان التقليدي الأكثر استقرارًا لضمان السلامة المطلقة. خلال المؤتمر، عرض Jensen Huang أيضًا استراتيجية NVIDIA في مجال الروبوتات.
حصلت هذه السيارة على لقب أكثر السيارات أمانًا في العالم من NCAP، وذلك بفضل التصميم الفريد لـ NVIDIA المتمثل في "طبقة الأمان المزدوجة". فعندما يفقد نموذج الذكاء الاصطناعي الثقة في ظروف الطريق، يتحول النظام فورًا إلى وضع الأمان التقليدي الأكثر استقرارًا لضمان السلامة المطلقة. خلال المؤتمر، عرض Jensen Huang أيضًا استراتيجية NVIDIA في مجال الروبوتات. 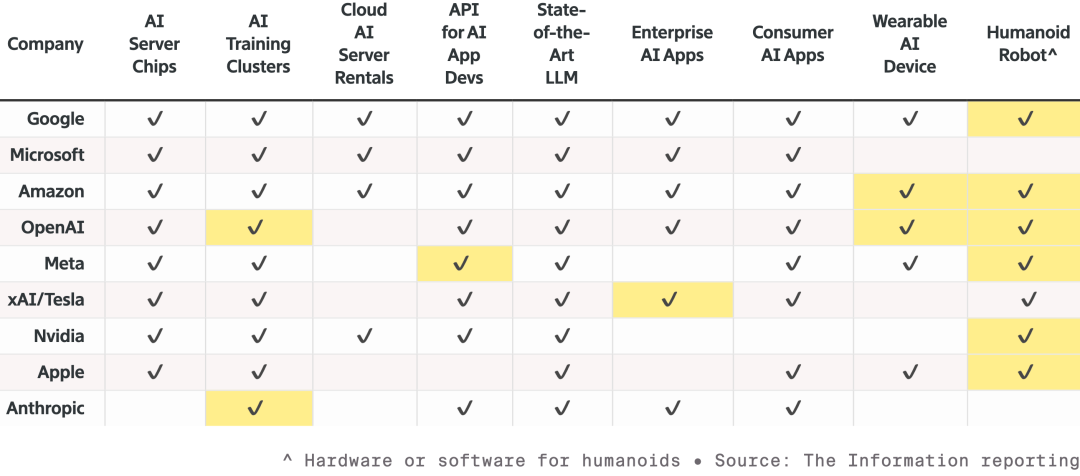 المنافسة بين تسعة من أكبر مصنعي الذكاء الاصطناعي والأجهزة ذات الصلة، جميعهم يوسعون خطوط الإنتاج، خاصة في مجال الروبوتات. الخانات المميزة تمثل المنتجات الجديدة منذ العام الماضي سيتم تزويد جميع الروبوتات بحاسوب Jetson صغير، وستتلقى تدريبها في محاكي Isaac على منصة Omniverse. وتعمل NVIDIA على دمج هذه التقنية في أنظمة صناعية مثل Synopsys وCadence وSiemens.
المنافسة بين تسعة من أكبر مصنعي الذكاء الاصطناعي والأجهزة ذات الصلة، جميعهم يوسعون خطوط الإنتاج، خاصة في مجال الروبوتات. الخانات المميزة تمثل المنتجات الجديدة منذ العام الماضي سيتم تزويد جميع الروبوتات بحاسوب Jetson صغير، وستتلقى تدريبها في محاكي Isaac على منصة Omniverse. وتعمل NVIDIA على دمج هذه التقنية في أنظمة صناعية مثل Synopsys وCadence وSiemens.  دعا Jensen Huang روبوتات بشرية مثل Boston Dynamics وAgility وروبوتات رباعية الأرجل للصعود إلى المنصة، مؤكدًا أن أكبر روبوت هو المصنع نفسه من الأسفل إلى الأعلى، رؤية NVIDIA هي أن تصميم الرقائق، وتصميم الأنظمة، ومحاكاة المصانع في المستقبل كلها ستتم تسريعها بواسطة الذكاء الاصطناعي الفيزيائي من NVIDIA. وخلال المؤتمر، ظهر روبوت Disney مرة أخرى، ليمازح Jensen Huang هذه المجموعة من الروبوتات اللطيفة قائلًا: "سيتم تصميمكم في الحاسوب، وتصنيعكم في الحاسوب، بل وستُختبرون وتُعتمدون في الحاسوب حتى قبل مواجهة الجاذبية الحقيقية."
دعا Jensen Huang روبوتات بشرية مثل Boston Dynamics وAgility وروبوتات رباعية الأرجل للصعود إلى المنصة، مؤكدًا أن أكبر روبوت هو المصنع نفسه من الأسفل إلى الأعلى، رؤية NVIDIA هي أن تصميم الرقائق، وتصميم الأنظمة، ومحاكاة المصانع في المستقبل كلها ستتم تسريعها بواسطة الذكاء الاصطناعي الفيزيائي من NVIDIA. وخلال المؤتمر، ظهر روبوت Disney مرة أخرى، ليمازح Jensen Huang هذه المجموعة من الروبوتات اللطيفة قائلًا: "سيتم تصميمكم في الحاسوب، وتصنيعكم في الحاسوب، بل وستُختبرون وتُعتمدون في الحاسوب حتى قبل مواجهة الجاذبية الحقيقية."  لولا أن Jensen Huang هو من ألقى الخطاب، لظننت أن العرض خاص بأحد مصنعي النماذج. في ظل جدل "فقاعة الذكاء الاصطناعي" اليوم، وبالإضافة إلى تباطؤ قانون مور، يبدو أن Jensen Huang بحاجة إلى استعراض ما يمكن أن يحققه الذكاء الاصطناعي لتعزيز ثقة الجميع فيه. إلى جانب الإعلان عن أداء منصة الحوسبة الفائقة الجديدة Vera Rubin، سعى بقوة لإظهار التغييرات الملموسة التي سيحدثها الذكاء الاصطناعي، ليس فقط لتهدئة "عطش الحوسبة"، بل أيضًا بالتركيز أكثر من أي وقت مضى على التطبيقات والبرمجيات. وكما قال Jensen Huang، بعد أن صنعوا رقائق للعالم الافتراضي في الماضي، قرروا الآن الدخول بأنفسهم للتركيز على الذكاء الاصطناعي الفيزيائي المتمثل في القيادة الذاتية والروبوتات البشرية، والانخراط في العالم الفيزيائي الحقيقي ذي المنافسة الصناعية الأشد. ففي النهاية، لا يمكن بيع الأسلحة إلا حين تبدأ المعركة فعليًا. *وأخيرًا، إليكم فيديو المفاجأة: بسبب ضيق الوقت في خطاب CES، لم يتمكن Jensen Huang من عرض العديد من شرائح PPT. فقرر ببساطة تحويل الشرائح غير المعروضة إلى مقطع فيديو فكاهي. استمتعوا بالمشاهدة⬇️
لولا أن Jensen Huang هو من ألقى الخطاب، لظننت أن العرض خاص بأحد مصنعي النماذج. في ظل جدل "فقاعة الذكاء الاصطناعي" اليوم، وبالإضافة إلى تباطؤ قانون مور، يبدو أن Jensen Huang بحاجة إلى استعراض ما يمكن أن يحققه الذكاء الاصطناعي لتعزيز ثقة الجميع فيه. إلى جانب الإعلان عن أداء منصة الحوسبة الفائقة الجديدة Vera Rubin، سعى بقوة لإظهار التغييرات الملموسة التي سيحدثها الذكاء الاصطناعي، ليس فقط لتهدئة "عطش الحوسبة"، بل أيضًا بالتركيز أكثر من أي وقت مضى على التطبيقات والبرمجيات. وكما قال Jensen Huang، بعد أن صنعوا رقائق للعالم الافتراضي في الماضي، قرروا الآن الدخول بأنفسهم للتركيز على الذكاء الاصطناعي الفيزيائي المتمثل في القيادة الذاتية والروبوتات البشرية، والانخراط في العالم الفيزيائي الحقيقي ذي المنافسة الصناعية الأشد. ففي النهاية، لا يمكن بيع الأسلحة إلا حين تبدأ المعركة فعليًا. *وأخيرًا، إليكم فيديو المفاجأة: بسبب ضيق الوقت في خطاب CES، لم يتمكن Jensen Huang من عرض العديد من شرائح PPT. فقرر ببساطة تحويل الشرائح غير المعروضة إلى مقطع فيديو فكاهي. استمتعوا بالمشاهدة⬇️ 
على عكس خطاب العام الماضي المنفرد، كان جدول Jensen Huang لعام 2026 مزدحمًا. من NVIDIA Live إلى حوار الذكاء الصناعي مع Siemens ثم مؤتمر Lenovo TechWorld، شارك في ثلاث فعاليات خلال 48 ساعة فقط. في المرة السابقة، أعلن عن سلسلة بطاقات RTX 50 في CES.أما هذه المرة، فقد كانت تقنيات الذكاء الاصطناعي الفيزيائي، والروبوتات، وجهاز " القنبلة النووية المؤسسية " التي تزن 2.5 طن، هي الحدث الرئيسي. ظهور منصة الحوسبة Vera Rubin، وكلما اشتريت أكثر وفرت أكثر خلال المؤتمر، قام Jensen Huang المعروف بحركاته الاستعراضية، بجلب خادم ذكاء صناعي يزن 2.5 طن إلى المسرح، ليكشف بذلك عن محور المؤتمر: منصة الحوسبة Vera Rubin، التي سُميت تيمنًا بعالمة الفلك التي اكتشفت المادة المظلمة وتهدف إلى هدف واحد فقط: تسريع سرعة تدريب الذكاء الاصطناعي، وجلب الجيل القادم من النماذج في وقت أبكر. عادة، لدى NVIDIA قاعدة: في كل جيل من المنتجات، يتم تعديل 1-2 شرائح فقط كحد أقصى. لكن Vera Rubin كسرت هذه القاعدة هذه المرة، حيث أعادت تصميم 6 شرائح دفعة واحدة، ودخلت جميعها مرحلة الإنتاج الضخم. والسبب في ذلك أنه مع تباطؤ قانون مور، لم تعد طرق تحسين الأداء التقليدية تواكب نمو نماذج الذكاء الاصطناعي بمعدل 10 أضعاف سنويًا، لذلك اختارت NVIDIA "تصميماً تعاونيًا متطرفًا" — أي الابتكار على جميع مستويات الشرائح والمنصة بالكامل في آن واحد.
هذه الشرائح الست هي: 1. Vera CPU: - 88 نواة Olympus مخصصة من NVIDIA - تقنية المعالجة المتعددة الخيوط من NVIDIA، تدعم 176 خيط معالجة - عرض نطاق NVLink C2C يصل إلى 1.8 تيرابايت/ثانية - ذاكرة النظام 1.5 تيرابايت (ثلاثة أضعاف Grace) - عرض نطاق LPDDR5X يصل إلى 1.2 تيرابايت/ثانية - 227 مليار ترانزستور 2. Rubin GPU: - قوة معالجة استنتاجية NVFP4 تبلغ 50 بيتافلوبس، خمسة أضعاف الجيل السابق Blackwell - 336 مليار ترانزستور، بزيادة 1.6 مرة عن Blackwell - مزود بمحرك Transformer من الجيل الثالث، قادر على ضبط الدقة ديناميكيًا وفقًا لاحتياجات نموذج Transformer 3. بطاقة الشبكة ConnectX-9: - إيثرنت بسرعة 800 جيجابت/ثانية مبنية على SerDes PAM4 بسرعة 200G - معجل RDMA ومسار بيانات قابل للبرمجة - معتمد من CNSA و FIPS - 23 مليار ترانزستور 4. BlueField-4 DPU: - محرك شامل مصمم خصيصًا لمنصات تخزين الذكاء الاصطناعي من الجيل الجديد - DPU بسرعة 800G Gb/s موجهة لـ SmartNIC ومعالجات التخزين - مزود بـ 64 نواة Grace CPU متوافقة مع ConnectX-9 - 126 مليار ترانزستور 5. شريحة تبديل NVLink-6: - تربط 18 عقدة حوسبة، وتدعم ما يصل إلى 72 Rubin GPU للعمل كوحدة واحدة - في بنية NVLink 6، يمكن لكل GPU الحصول على 3.6 تيرابايت في الثانية من عرض النطاق الترددي للتواصل الشامل - تعتمد على SerDes بسرعة 400G، وتدعم In-Network SHARP Collectives، مما يتيح إجراء عمليات التواصل الجماعي داخل شبكة التبديل 6. شريحة تبديل Spectrum-6 إيثرنت الضوئية - 512 قناة، كل قناة بسرعة 200 جيجابت/ثانية لنقل بيانات أسرع - مجهزة بتقنية السيليكون الضوئي من TSMC COOP - مزودة بواجهات بصرية مدمجة (copackaged optics) - 352 مليار ترانزستور من خلال التكامل العميق بين هذه الشرائح الست، حقق نظام Vera Rubin NVL72 أداءً أعلى بكثير من الجيل السابق Blackwell في جميع الجوانب. في مهام الاستنتاج NVFP4، وصلت قوة معالجة هذه الشريحة إلى 3.6 إكسافلوبس، أي بزيادة قدرها 5 أضعاف عن بنية Blackwell السابقة. أما في تدريب NVFP4، فقد بلغ الأداء 2.5 إكسافلوبس، أي بزيادة 3.5 أضعاف. في ما يخص سعة التخزين، يأتي NVL72 مزودًا بذاكرة LPDDR5X بسعة 54 تيرابايت، أي ثلاثة أضعاف الجيل السابق. سعة HBM (الذاكرة ذات النطاق الترددي العالي) تبلغ 20.7 تيرابايت، بزيادة 1.5 مرة. أما في الأداء، فوصل عرض نطاق HBM4 إلى 1.6 بيتابايت/ثانية، بزيادة 2.8 مرة؛ بينما ارتفع عرض النطاق الترددي Scale-Up إلى 260 تيرابايت/ثانية، بزيادة بلغت الضعف. رغم هذا التحسن الهائل في الأداء، لم يزد عدد الترانزستورات إلا بمقدار 1.7 مرة ليصل إلى 220 تريليون، مما يظهر قدرة ابتكارية هائلة في تصنيع أشباه الموصلات. على مستوى التصميم الهندسي، قدمت Vera Rubin أيضًا اختراقًا تقنيًا. كان يتطلب توصيل عقدة الحوسبة الفائقة سابقًا 43 كابلًا، ويستغرق التجميع ساعتين مع احتمالية وقوع أخطاء. الآن، تستخدم عقدة Vera Rubin صفر كابلات، فقط 6 أنابيب تبريد سائل، ويستغرق التجميع 5 دقائق فقط. والأكثر إثارة أن الجزء الخلفي من الرف ممتلئ بكابلات نحاسية طولها الإجمالي 3.2 كيلومتر تقريبًا، 5000 كابل نحاسي يشكلون العمود الفقري لشبكة NVLink بسرعة نقل 400 جيجابت/ثانية، وكما قال Jensen Huang: "قد تزن عدة مئات من الأرطال، يجب أن تكون الرئيس التنفيذي بقوة بدنية جيدة لتناسب هذه الوظيفة". في عالم الذكاء الاصطناعي، الوقت يعني المال. تشير بيانات مهمة إلى أن تدريب نموذج يحتوي على 100 تريليون معلمة يتطلب من Rubin فقط ربع عدد أنظمة Blackwell، بينما تكلفة توليد Token واحدة تقارب عُشر تكلفة Blackwell. بالإضافة إلى ذلك، رغم أن استهلاك الطاقة في Rubin هو ضعف Grace Blackwell، إلا أن التحسن في الأداء يفوق الزيادة في الاستهلاك بكثير، حيث زاد الأداء الاستنتاجي 5 أضعاف والتدريبي 3.5 أضعاف. والأهم من ذلك، أن إنتاجية Rubin (عدد Tokens لكل واط-لكل دولار) ارتفعت بمقدار 10 أضعاف مقارنة بـ Blackwell، مما يعني أن مركز بيانات بسعة 1 جيجاوات وتكلفة 50 مليار دولار سيضاعف قدرته الربحية مباشرة. أكبر مشكلة في صناعة الذكاء الاصطناعي سابقًا كانت عدم توفر ذاكرة سياقية كافية. فعند عمل الذكاء الاصطناعي، ينشئ "KV Cache" (ذاكرة المفتاح والقيمة)، وهي بمثابة "ذاكرة العمل" للذكاء الاصطناعي. ومع زيادة حجم المحادثة والنموذج، أصبحت ذاكرة HBM غير كافية. أطلقت NVIDIA العام الماضي بنية Grace-Blackwell لتوسيع الذاكرة، لكنها لم تكن كافية. أما حل Vera Rubin فهو نشر معالجات BlueField-4 داخل الرف لإدارة KV Cache تحديدًا. كل عقدة مزودة بـ 4 BlueField-4، وكل منها مزود بـ 150 تيرابايت من الذاكرة السياقية، توزع على وحدات GPU، ليحصل كل GPU على 16 تيرابايت إضافية — في حين أن ذاكرة GPU الأصلية حوالي 1 تيرابايت فقط، والأهم أن عرض النطاق يبقى عند 200 جيجابت/ثانية دون أي انخفاض في السرعة. لكن السعة وحدها لا تكفي، إذ يجب أن تتعاون "الملاحظات" الموزعة عبر عشرات الرفوف وآلاف وحدات GPU كما لو كانت ذاكرة واحدة، لذا يجب أن تكون الشبكة "كبيرة وسريعة ومستقرة" في آن واحد. وهنا يأتي دور Spectrum-X. Spectrum-X هو أول منصة شبكة إيثرنت شاملة في العالم "مصممة خصيصًا للذكاء الاصطناعي التوليدي"، ويعتمد الجيل الجديد من Spectrum-X على تقنية السيليكون الضوئي من TSMC COOP، مع 512 قناة × 200 جيجابت/ثانية. حسب حسابات Jensen Huang: مركز بيانات بسعة 1 جيجاوات يكلف 50 مليار دولار، ويمكن لـ Spectrum-X تحسين الإنتاجية بنسبة 25%، ما يعني توفير 5 مليارات دولار. "يمكنك القول إن هذا النظام الشبكي يكاد يكون مجانيًا". أما من الناحية الأمنية، تدعم Vera Rubin الحوسبة السرية (Confidential Computing)، حيث يتم تشفير جميع البيانات أثناء النقل والتخزين والمعالجة، بما في ذلك قنوات PCIe و NVLink والتواصل بين CPU و GPU وجميع الحافلات. يمكن للشركات نشر نماذجها على أنظمة خارجية دون القلق بشأن تسرب البيانات. DeepSeek أدهشت العالم، والمصادر المفتوحة والوكلاء هي الاتجاه السائد للذكاء الاصطناعي بعد العرض الرئيسي، نعود إلى بداية الخطاب. بمجرد صعود Jensen Huang إلى المسرح، أعلن رقمًا مذهلًا: تقدر الموارد الحاسوبية التي استُثمرت خلال العقد الماضي بـ 10 تريليون دولار، وهي في طور التحديث الجذري. لكن الأمر لا يتعلق فقط بترقية الأجهزة، بل أيضًا بتحول نماذج البرمجيات. فقد أشار بشكل خاص إلى نماذج الذكاء الاصطناعي القادرة على التصرف بشكل وكيل (Agentic) وذكر نموذج Cursor بالاسم، الذي غير طريقة البرمجة داخل NVIDIA بالكامل. وكان أكثر ما أشعل الحضور هو تقييمه العالي لمجتمع المصادر المفتوحة. حيث قال صراحة إن اختراق DeepSeek V1 العام الماضي كان مفاجأة للعالم، إذ كان أول نظام استنتاج مفتوح المصدر، وأشعل موجة تطوير في الصناعة بأكملها. وعلى شريحة PPT، كان اللاعبان الصينيان Kimi k2 و DeepSeek V3.2 هما الأول والثاني في المصادر المفتوحة. يعتقد Jensen Huang أن نماذج المصادر المفتوحة قد تتأخر حاليًا عن النماذج الرائدة بحوالي ستة أشهر، لكن كل ستة أشهر يظهر نموذج جديد. هذا التسارع في التطور يدفع الشركات الناشئة والعمالقة والباحثين — بما فيهم NVIDIA — إلى عدم تفويت الفرصة. لذا، لم يكتفوا هذه المرة ببيع "المجرفة" أو تسويق بطاقات الشاشة؛ بل بنت NVIDIA حاسوبًا فائقًا في السحابة بقيمة مليارات الدولارات يسمى DGX Cloud، وطورت نماذج رائدة مثل La Proteina (تخليق البروتين) و OpenFold 3. يغطي نظام نماذج المصادر المفتوحة من NVIDIA مجالات الطب الحيوي، والذكاء الاصطناعي الفيزيائي، ونماذج الوكلاء، والروبوتات، والقيادة الذاتية، وغيرها كما أن العديد من النماذج المفتوحة المصدر من عائلة نماذج NVIDIA Nemotron كانت من أبرز ما في هذا الخطاب. وتشمل هذه النماذج الصوت، والنماذج متعددة الوسائط، ونماذج الاسترجاع والتوليد المعزز، والنماذج الآمنة، حيث أشار Jensen Huang إلى أن نماذج Nemotron المفتوحة المصدر أحرزت نتائج ممتازة في العديد من قوائم الاختبار، وتبنتها العديد من الشركات. ما هو الذكاء الاصطناعي الفيزيائي؟ إصدار عشرات النماذج دفعة واحدة إذا كانت النماذج اللغوية الكبرى حلت مشاكل "العالم الرقمي"، فإن طموح NVIDIA التالي أصبح واضحًا: غزو "العالم الفيزيائي". أشار Jensen Huang إلى أنه لجعل الذكاء الاصطناعي يفهم قوانين الفيزياء ويعيش في الواقع، فإن البيانات شحيحة للغاية. وبالإضافة إلى نماذج الوكلاء المفتوحة المصدر Nemotron، قدم بنية أساسية لـ "ثلاثة حواسيب" لبناء الذكاء الاصطناعي الفيزيائي (Physical AI). حاسوب التدريب، وهو الحاسوب الذي نعرفه، المبني من بطاقات الشاشة المخصصة للتدريب مثل بنية GB300 المذكورة في الصورة.
حاسوب الاستنتاج، وهو "المخيخ" الذي يعمل على أطراف الروبوت أو السيارة، مسؤول عن التنفيذ الفوري.
حاسوب المحاكاة، ويشمل Omniverse و Cosmos، حيث يوفر بيئة تدريب افتراضية للذكاء الاصطناعي ليتعلم منها التغذية الراجعة الفيزيائية.
يستطيع نظام Cosmos إنشاء العديد من بيئات تدريب الذكاء الاصطناعي للعالم الفيزيائي استنادًا إلى هذه البنية، أعلن Jensen Huang رسميًا عن Alpamayo، أول نموذج قيادة ذاتية في العالم يتمتع بقدرة على التفكير والاستنتاج. على عكس النماذج التقليدية للقيادة الذاتية، فإن Alpamayo هو نظام مدرَّب من طرف إلى طرف، وميزته الأساسية هي حل "مشكلة الذيل الطويل" في القيادة الذاتية. فعند مواجهة ظروف طريق معقدة وغير مسبوقة، لم يعد Alpamayo ينفذ الشيفرة حرفيًا، بل يستنتج كما يفعل السائق البشري. "سوف يخبرك بما سيفعله بعد ذلك ولماذا اتخذ هذا القرار." وأثناء العرض التوضيحي، كانت طريقة القيادة طبيعية بشكل مذهل، حيث قام النموذج بتقسيم المشاهد المعقدة للغاية إلى معارف أساسية للتعامل معها. وليس الأمر مجرد عرض نظري؛ فقد أعلن Jensen Huang أن سيارة Mercedes CLA المزودة بتقنية Alpamayo ستنطلق رسميًا في الولايات المتحدة خلال الربع الأول من هذا العام، ثم تتبعها أوروبا وآسيا. حصلت هذه السيارة على لقب أكثر السيارات أمانًا في العالم من NCAP، وذلك بفضل التصميم الفريد لـ NVIDIA المتمثل في "طبقة الأمان المزدوجة". فعندما يفقد نموذج الذكاء الاصطناعي الثقة في ظروف الطريق، يتحول النظام فورًا إلى وضع الأمان التقليدي الأكثر استقرارًا لضمان السلامة المطلقة. خلال المؤتمر، عرض Jensen Huang أيضًا استراتيجية NVIDIA في مجال الروبوتات. المنافسة بين تسعة من أكبر مصنعي الذكاء الاصطناعي والأجهزة ذات الصلة، جميعهم يوسعون خطوط الإنتاج، خاصة في مجال الروبوتات. الخانات المميزة تمثل المنتجات الجديدة منذ العام الماضي سيتم تزويد جميع الروبوتات بحاسوب Jetson صغير، وستتلقى تدريبها في محاكي Isaac على منصة Omniverse. وتعمل NVIDIA على دمج هذه التقنية في أنظمة صناعية مثل Synopsys وCadence وSiemens. دعا Jensen Huang روبوتات بشرية مثل Boston Dynamics وAgility وروبوتات رباعية الأرجل للصعود إلى المنصة، مؤكدًا أن أكبر روبوت هو المصنع نفسه من الأسفل إلى الأعلى، رؤية NVIDIA هي أن تصميم الرقائق، وتصميم الأنظمة، ومحاكاة المصانع في المستقبل كلها ستتم تسريعها بواسطة الذكاء الاصطناعي الفيزيائي من NVIDIA. وخلال المؤتمر، ظهر روبوت Disney مرة أخرى، ليمازح Jensen Huang هذه المجموعة من الروبوتات اللطيفة قائلًا: "سيتم تصميمكم في الحاسوب، وتصنيعكم في الحاسوب، بل وستُختبرون وتُعتمدون في الحاسوب حتى قبل مواجهة الجاذبية الحقيقية." لولا أن Jensen Huang هو من ألقى الخطاب، لظننت أن العرض خاص بأحد مصنعي النماذج. في ظل جدل "فقاعة الذكاء الاصطناعي" اليوم، وبالإضافة إلى تباطؤ قانون مور، يبدو أن Jensen Huang بحاجة إلى استعراض ما يمكن أن يحققه الذكاء الاصطناعي لتعزيز ثقة الجميع فيه. إلى جانب الإعلان عن أداء منصة الحوسبة الفائقة الجديدة Vera Rubin، سعى بقوة لإظهار التغييرات الملموسة التي سيحدثها الذكاء الاصطناعي، ليس فقط لتهدئة "عطش الحوسبة"، بل أيضًا بالتركيز أكثر من أي وقت مضى على التطبيقات والبرمجيات. وكما قال Jensen Huang، بعد أن صنعوا رقائق للعالم الافتراضي في الماضي، قرروا الآن الدخول بأنفسهم للتركيز على الذكاء الاصطناعي الفيزيائي المتمثل في القيادة الذاتية والروبوتات البشرية، والانخراط في العالم الفيزيائي الحقيقي ذي المنافسة الصناعية الأشد. ففي النهاية، لا يمكن بيع الأسلحة إلا حين تبدأ المعركة فعليًا. *وأخيرًا، إليكم فيديو المفاجأة: بسبب ضيق الوقت في خطاب CES، لم يتمكن Jensen Huang من عرض العديد من شرائح PPT. فقرر ببساطة تحويل الشرائح غير المعروضة إلى مقطع فيديو فكاهي. استمتعوا بالمشاهدة⬇️ 0
0
إخلاء المسؤولية: يعكس محتوى هذه المقالة رأي المؤلف فقط ولا يمثل المنصة بأي صفة. لا يُقصد من هذه المقالة أن تكون بمثابة مرجع لاتخاذ قرارات الاستثمار.
منصة PoolX: احتفظ بالعملات لتربح
ما يصل إلى 10% + معدل الفائدة السنوي. عزز أرباحك بزيادة رصيدك من العملات
احتفظ بالعملة الآن!
You may also like
مورغان ستانلي يدخل سوق العملات الرقمية لكن Digitap ($TAP) هي أفضل عملة رقمية للشراء في عام 2026 للمستثمرين الأفراد
BlockchainReporter•2026/01/18 14:02
أرمسترونج ينفي وجود توتر مع البيت الأبيض بشأن قانون CLARITY
Cointribune•2026/01/18 13:43

مؤسس Ethereum فيتاليك بوتيرين يدعو إلى "جمع النفايات" لإنقاذ البلوكشين
Coinpedia•2026/01/18 13:32

هل لا تزال XRP صفقة استثمارية لعام 2026 أم أن استخدامها الأساسي قد تلاشى؟
Coinpedia•2026/01/18 13:32

Trending news
المزيدأسعار العملات المشفرة
المزيدBitcoin
BTC
$95,125.3
%0.25-
Ethereum
ETH
$3,324.79
%0.70+
Tether USDt
USDT
$0.9997
%0.00+
BNB
BNB
$947.03
%0.48+
XRP
XRP
$2.05
%0.44-
Solana
SOL
$142.37
%1.03-
USDC
USDC
$0.9999
%0.01+
TRON
TRX
$0.3166
%0.99+
Dogecoin
DOGE
$0.1371
%0.44-
Cardano
ADA
$0.3931
%1.12-
كيفية بيع PI
منصة Bitget تُدرج عملة PI - يُمكنك شراء PI أو بيعها بسرعة على Bitget!
تداول الآن
ألم تنضم لمنصة Bitget بعد؟حزمة ترحيب بقيمة 6200 USDT لمستخدمي Bitget الجُدد!
تسجيل الاشتراك الآن