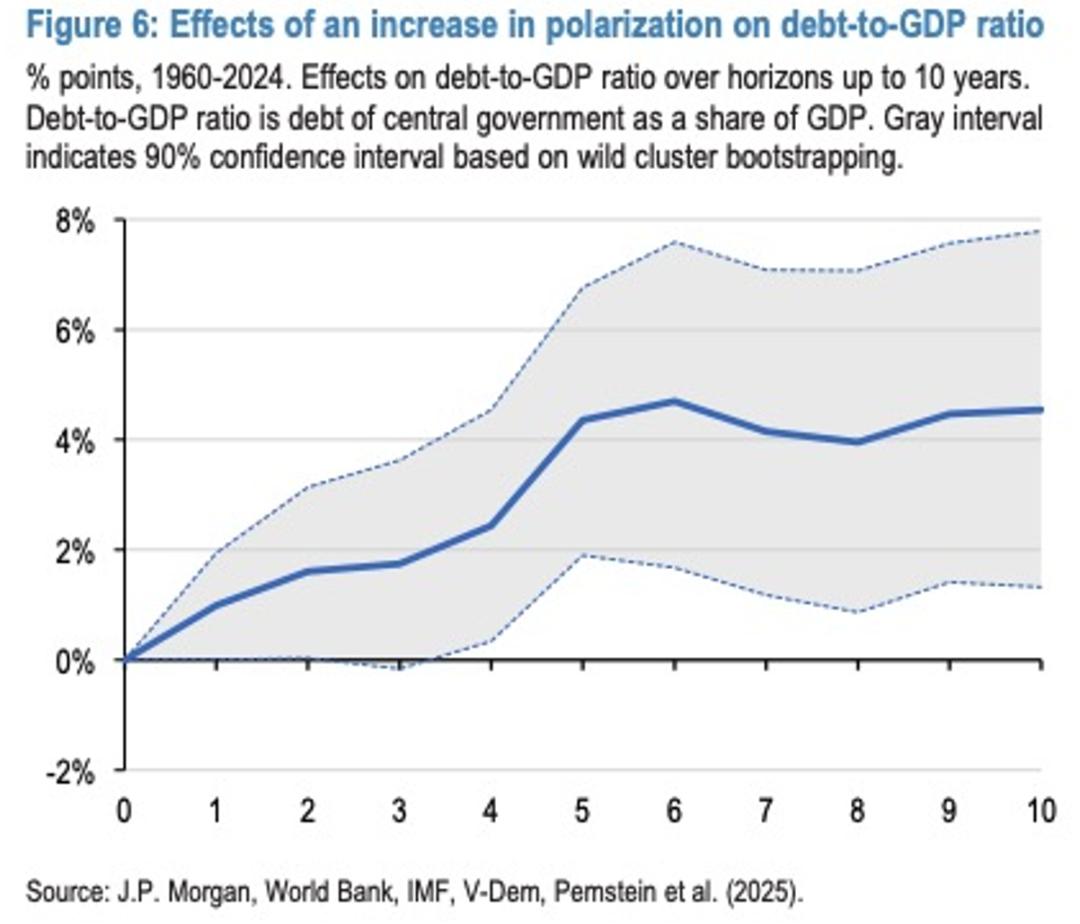
Kurz gefasst
- Die Wikimedia Foundation hat eine Reihe von Partnerschaften mit KI-Unternehmen angekündigt, um ihre Inhalte für das Training von LLMs zu nutzen.
- Die KI-Unternehmen haben sich für das Enterprise-Produkt angemeldet, um die Inhalte von Wikipedia in großem Maßstab wiederzuverwenden.
- Im Oktober letzten Jahres erklärte die Foundation, dass die Seitenaufrufe zurückgehen, da Menschen KI-Zusammenfassungen nutzen, anstatt die Seite zu besuchen.
Die Wikimedia Foundation hat eine Reihe neuer Partnerschaften mit Unternehmen aus dem Bereich künstliche Intelligenz angekündigt, die es diesen erlauben, Wikipedia-Inhalte zum Trainieren und Betreiben ihrer KI-Modelle zu verwenden. Damit möchte die gemeinnützige Organisation angesichts sich verändernder Online-Gewohnheiten ihre langfristige Nachhaltigkeit sichern.
Die Vereinbarungen wurden über Wikimedia Enterprise getroffen, das kommerzielle Produkt der Foundation, das für Großnutzer und Distributoren von Inhalten aus Wikimedia-Projekten entwickelt wurde. Zu den neuen Partnern gehören Ecosia, Microsoft, Mistral AI, Perplexity, Pleias und ProRata. Sie gesellen sich zu bestehenden Partnern wie Amazon, Google und Meta.
„Im KI-Zeitalter war Wikipedia und das von Menschen geschaffene und kuratierte Wissen noch nie so wertvoll“, erklärte die Foundation in einer Stellungnahme.
„Dieses Wissen treibt generative KI-Chatbots, Suchmaschinen, Sprachassistenten und mehr an. Wikipedia ist eines der qualitativ hochwertigsten Datensätze, die für das Training von Large Language Models verwendet werden.“
Die Bekanntgabe erfolgte im Rahmen eines Updates zum 25-jährigen Jubiläum von Wikipedia.
Die Online-Enzyklopädie gehört laut Foundation zu den zehn meistbesuchten Webseiten weltweit und ist die einzige in dieser Gruppe, die von einer gemeinnützigen Organisation betrieben wird. Über 65 Millionen Artikel in mehr als 300 Sprachen werden monatlich fast 15 Milliarden Mal aufgerufen.
Allerdings hat die Foundation gewarnt, dass sich die Zugriffsmuster ändern. Im Oktober wurde mitgeteilt, dass die menschlichen Besuche auf Wikipedia im Jahresvergleich um 8% zurückgingen, wobei der Rückgang darauf zurückgeführt wird, dass Nutzer sich auf KI-generierte Zusammenfassungen verlassen, anstatt die Seite direkt zu besuchen. Fast 60% der Google-Suchen enden inzwischen ohne einen Klick, wobei die Antworten auf der Suchseite häufig auf Wikipedia-Inhalten basieren.
KI vs. Verlage
Die Vereinbarungen erfolgen vor dem Hintergrund einer breiteren Debatte darüber, wie KI-Unternehmen Trainingsdaten erhalten. Large Language Models werden typischerweise mit riesigen Mengen an Online-Material trainiert – eine Praxis, die von Autoren, Verlagen und anderen Rechteinhabern kritisiert wird, da die Nutzung urheberrechtlich geschützter Werke ohne Erlaubnis als Urheberrechtsverletzung angesehen wird.
Unter anderem ist Reddit in mehrere Klagen mit KI-Unternehmen verwickelt, weil deren Inhalte zum Training von Modellen genutzt werden – allerdings wurden mit Unternehmen wie Google Lizenzvereinbarungen getroffen.
Am Donnerstag reichten die großen Buchverlage Hachette Book Group und Cengage Group einen Antrag ein, sich einer laufenden Sammelklage gegen Google anzuschließen. Sie werfen dem Unternehmen vor, „historische Urheberrechtsverletzungen“ zu begehen, um seine Gemini KI-Plattform aufzubauen. Der Klage zufolge kopierte Google Bücher während des KI-Trainings ohne die erforderlichen Lizenzen. Die Klage wurde ursprünglich 2023 von einer Gruppe von Autoren eingereicht.
OpenAI sieht sich einer ähnlichen Klage von Klägern gegenüber, zu denen auch der „Game of Thrones“-Autor George R.R. Martin gehört.
Auch Unterhaltungsunternehmen verschärfen das Thema. Mitte Dezember schickte Disney Google eine Unterlassungsaufforderung wegen Urheberrechtsverletzungen, auch wenn Disney ein separates Lizenzabkommen mit OpenAI über Hunderte von Charakteren für KI-generierte Videos abschloss. Disney hat ähnliche Hinweise an andere KI-Unternehmen verschickt und ist gemeinsam mit großen Filmstudios an Rechtsstreitigkeiten gegen das Bildgenerierungsunternehmen Midjourney beteiligt.
Im selben Monat gründete ein Bündnis aus Autoren, Schauspielern und Technologen eine neue Brancheninitiative, die sich für durchsetzbare Standards im Umgang mit KI-Training und -Einsatz in der Unterhaltungsbranche einsetzt. Mehr als 500 prominente Persönlichkeiten unterstützen die Initiative, darunter Natalie Portman, Cate Blanchett, Ben Affleck, Guillermo del Toro und Taika Waititi.
Auch die Europäische Kommission hat eine formelle Kartelluntersuchung eingeleitet, um zu prüfen, ob Google gegen die EU-Wettbewerbsregeln verstoßen hat, indem es Inhalte von Verlagen und YouTube für KI-Dienste ohne angemessene Vergütung oder Zustimmung verwendet hat.
Ob Rechteinhaber letztlich Recht bekommen, ist ungewiss. Bundesrichter in den USA haben Meta und Anthropic kürzlich teilweise Recht gegeben und entschieden, dass die Nutzung urheberrechtlich geschützter Bücher zum Trainieren von KI-Modellen als „Fair Use“ gilt, während sie die Unternehmen jedoch für das Vorhalten dauerhafter Bibliotheken mit Raubkopien kritisierten.