
Deepseek v3.2... nuevo SOTA de código abierto (1 de diciembre)

 Un flujo de información simplificado
Un flujo de información simplificado Recién estuve investigando el lanzamiento de deepseek en el subte...
A continuación, un resumen rápido,
1/ El lanzamiento de Deepseek esta vez produjo resultados realmente impresionantes.
- Sin dudas, es el sota open source;
- En casi todas sus capacidades está al nivel de los modelos cerrados más avanzados;
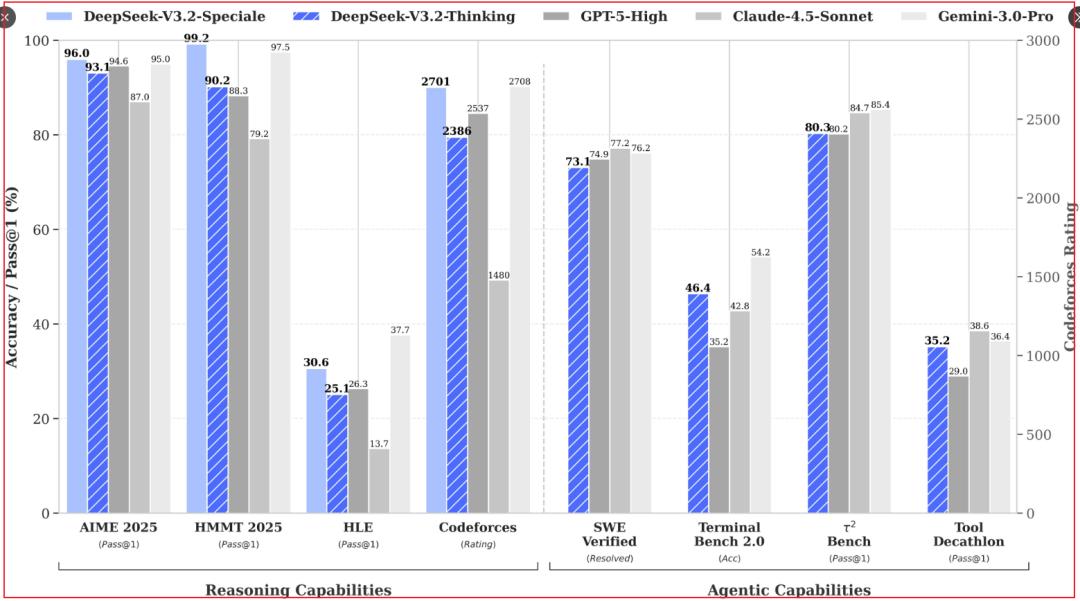
2/ En términos tecnológicos, no es algo totalmente nuevo,
- Sigue utilizando DSA + post train, y que este último supere el 10% tampoco es noticia;
- La novedad es que, usando lo del experimento v3.2, los resultados son tan buenos, compitiendo directamente con SOTA como gemini3.0, recién lanzado;
- Ahora la literatura académica ya no impulsa tanto la narrativa del mercado; el rendimiento de las capacidades es mucho más intuitivo.
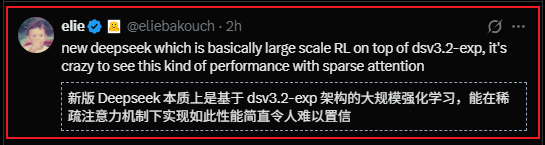
3/ ¿El mayor miedo era el colapso de la capacidad de cómputo? No existe tal cosa.
Según Deepseek, todavía hay una brecha con los modelos más avanzados.

Visto desde otra perspectiva, la "muralla de conocimiento" a nivel de modelo es bastante difusa, la capacidad de cómputo sigue siendo un factor diferenciador.
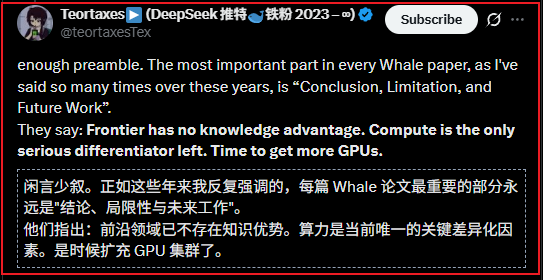
Opinión del investigador de Deepseek, Zhibin Gou; gemini3 demuestra pretrain... deepseek 3.2 demuestra RL;
Seguir escalando en todos los niveles; que el ruido de los que chocan contra la pared no te distraiga.

Más RL, cadenas de pensamiento más largas, mayor consumo de cómputo en inferencia; no se puede concluir una narrativa de deflación de cómputo.
4/ Desde el punto de vista de las aplicaciones... claramente es algo positivo. Citando a un usuario de la comunidad,
-
"La demanda de cómputo es infinita, y el costo de tokens actual tiene poco valor práctico; solo con innovaciones en hardware y modelos para reducir el costo geométricamente se podrá lograr una aplicación masiva"
-
Para las empresas que quieren construir una "muralla de defensa" en sus apps basadas en la capacidad de modelo (como cierta OAI), de hecho, esto debilita bastante esa narrativa.
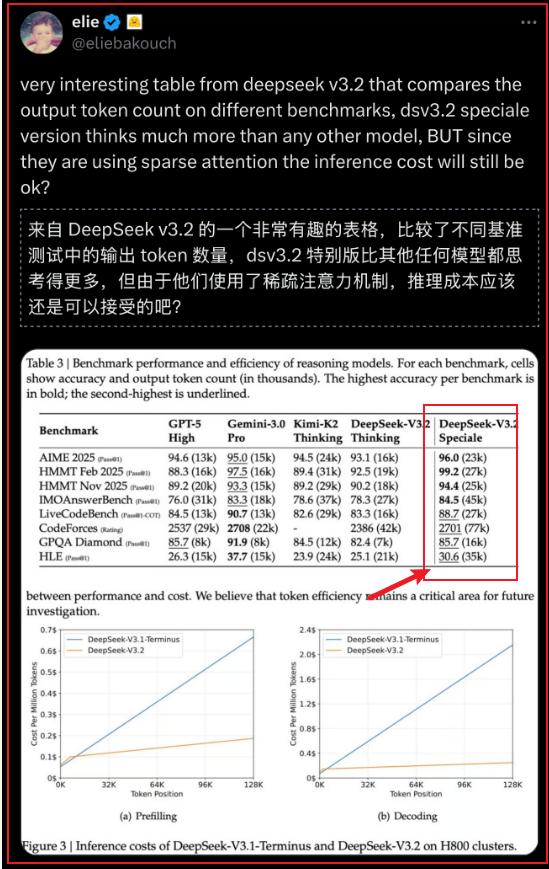
5/ Deepseek admite que la eficiencia del uso de tokens es “inferior”... aquí en la versión Speciale, la cantidad de tokens usada es mayor...(el recuadro rojo)...
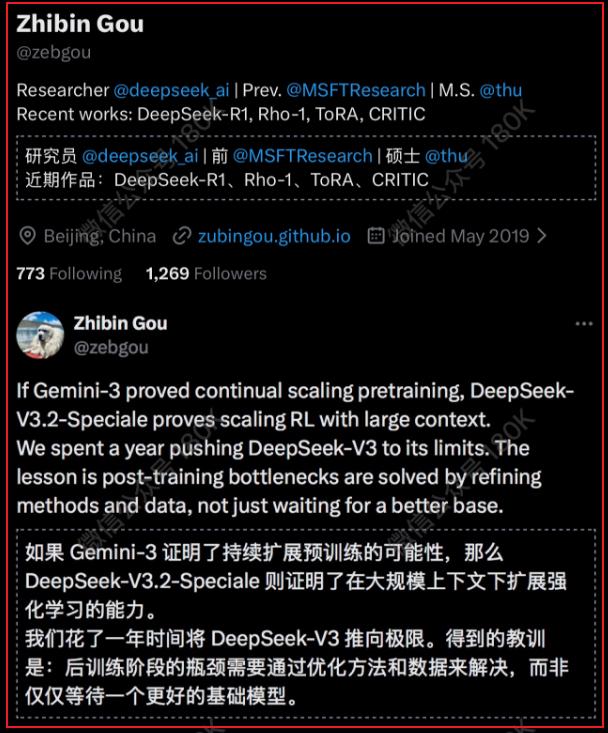
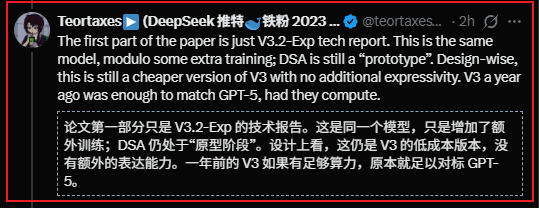
6/ Bonus: Zhibin Gou dijo que estuvieron un año llevando v3 al límite... Algunos amigos en los grupos de la comunidad piensan que, después de exprimir v3,¿finalmente vendrá v4 en la próxima versión??
7/ Hoy parece ser el tercer aniversario del lanzamiento de ChatGPT...
Esta noche el mercado debería estar bastante volátil... Algunos factores macroeconómicos en Japón + BTC generando movimientos;
El próximo pequeño evento catalizador podría ser el re:invent de Amazon; también se discutió un poco esta mañana en el grupo.
Descargo de responsabilidad: El contenido de este artículo refleja únicamente la opinión del autor y no representa en modo alguno a la plataforma. Este artículo no se pretende servir de referencia para tomar decisiones de inversión.
También te puede gustar
Macron planea invocar el mecanismo comercial de la UE ante el aumento de demandas de represalias
Intel apuesta por los fundamentos mientras sus rivales impulsan la inteligencia artificial en el mercado de laptops
TechCrunch Movilidad: “IA física” se convierte en la nueva palabra de moda

¿Puede Trip.com recuperarse después de enfrentar una represión al estilo 'Jack Ma' por parte de Pekín?