
Menjadi trending! Model besar Meituan menjadi populer karena "kecepatannya"

Pengembang dalam dan luar negeri: Sudah diuji, model open source baru Meituan sangat cepat!
Ketika AI benar-benar menjadi seumum air dan listrik, kekuatan model bukan lagi satu-satunya hal yang menjadi perhatian semua orang.
Dari Claude 3.7 Sonnet, Gemini 2.5 Flash di awal tahun hingga GPT-5, DeepSeek V3.1 baru-baru ini, para produsen model terdepan semuanya memikirkan: dengan tetap menjaga akurasi, bagaimana membuat AI dapat menyelesaikan setiap masalah dengan daya komputasi seminimal mungkin, dan memberikan respons secepat mungkin? Dengan kata lain, bagaimana caranya agar tidak membuang-buang token maupun waktu.
Bagi perusahaan dan pengembang yang membangun aplikasi di atas model, perubahan dari "sekadar membangun model terkuat menjadi membangun model yang lebih praktis dan cepat" adalah kabar baik. Lebih menggembirakan lagi, model open source terkait juga semakin banyak bermunculan.
Beberapa hari lalu, kami menemukan model baru di HuggingFace — LongCat-Flash-Chat.

Model ini berasal dari seri LongCat-Flash milik Meituan, dapat langsung digunakan di situs resminya.
Model ini secara alami memahami bahwa "tidak semua token itu sama", sehingga akan memberikan anggaran komputasi dinamis untuk token yang penting sesuai tingkat kepentingannya. Dengan hanya mengaktifkan sedikit parameter, performanya sudah bisa menyamai model open source terdepan saat ini.

LongCat-Flash menjadi trending setelah open source.
Pada saat yang sama, kecepatan model ini juga meninggalkan kesan mendalam — pada kartu grafis H800, kecepatan inferensi melebihi 100 token per detik. Pengujian nyata dari pengembang dalam dan luar negeri membuktikan hal ini — ada yang mencapai kecepatan 95 tokens/s, ada juga yang mendapat jawaban setara Claude dalam waktu sangat singkat.
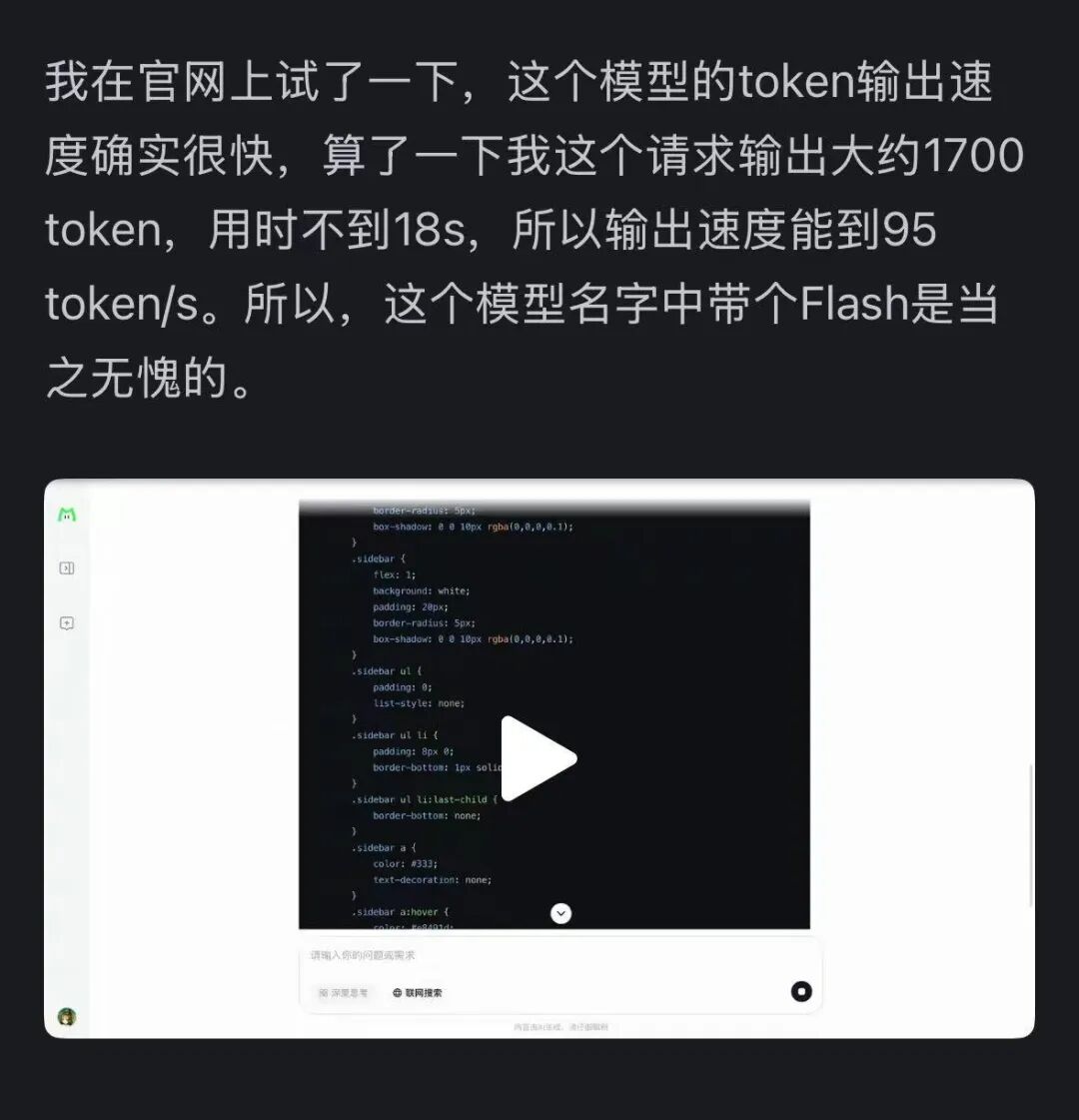
Sumber gambar: pengguna Zhihu @小小将.
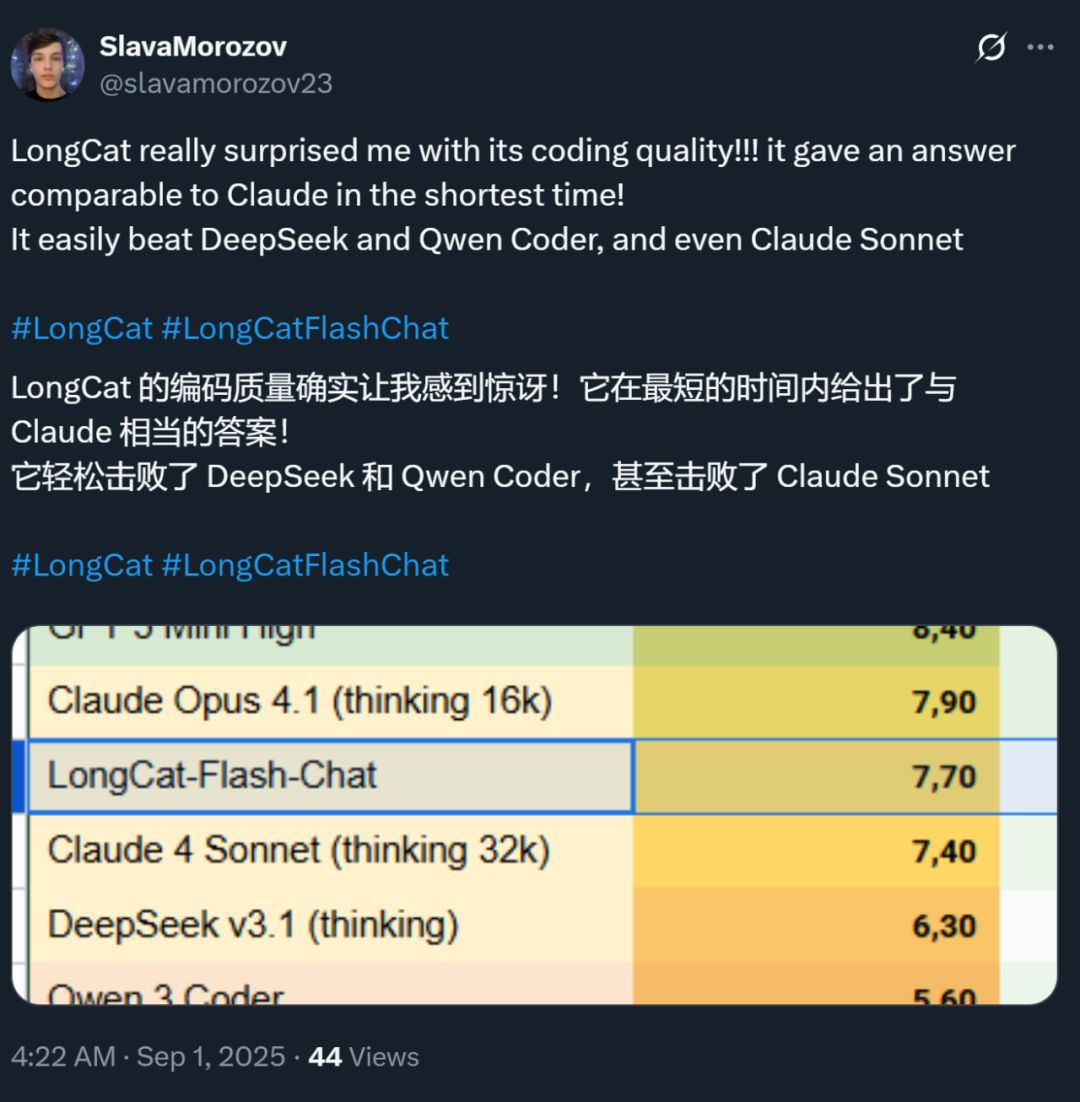
Sumber gambar: pengguna X @SlavaMorozov.
Bersamaan dengan open source model, Meituan juga merilis laporan teknis LongCat-Flash, di mana kita dapat melihat banyak detail teknis.

Laporan Teknis: LongCat-Flash Technical Report
Pada artikel ini, kami akan membahas secara detail.
Bagaimana model besar menghemat daya komputasi?
Lihat inovasi arsitektur dan metode pelatihan LongCat-Flash
LongCat-Flash adalah model expert campuran dengan total parameter 560 billions, dapat mengaktifkan 18.6 billions hingga 31.3 billions (rata-rata 27 billions) parameter sesuai kebutuhan konteks.
Data yang digunakan untuk melatih model ini lebih dari 20 triliun token, namun waktu pelatihannya hanya kurang dari 30 hari. Selain itu, selama periode ini, sistem mencapai 98,48% tingkat ketersediaan waktu, hampir tanpa intervensi manusia untuk menangani kegagalan — artinya seluruh proses pelatihan pada dasarnya berjalan otomatis tanpa campur tangan manusia.
Yang lebih mengesankan, model yang dilatih dengan cara ini juga menunjukkan performa luar biasa saat diterapkan secara nyata.
Seperti terlihat pada gambar di bawah, sebagai model non-reflektif, LongCat-Flash mencapai performa setara dengan model non-reflektif SOTA, termasuk DeepSeek-V3.1 dan Kimi-K2, dengan parameter lebih sedikit dan kecepatan inferensi lebih tinggi. Ini membuatnya sangat kompetitif dan praktis di bidang umum, pemrograman, serta penggunaan alat cerdas.
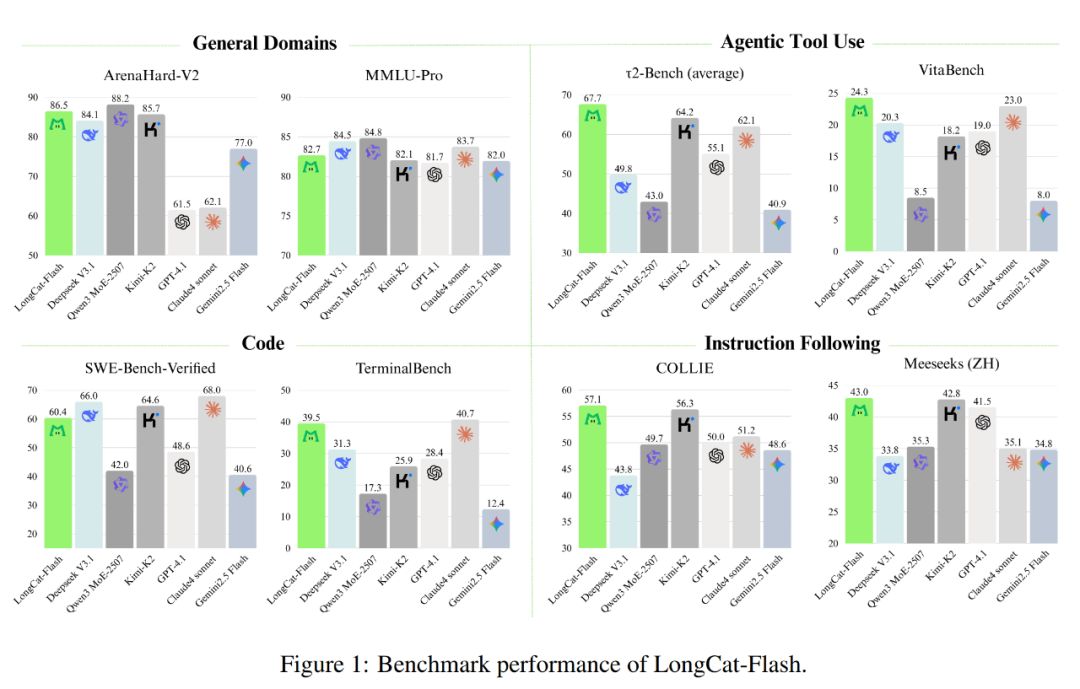
Selain itu, biayanya juga sangat menarik, hanya 0,7 dolar AS per satu juta output token. Harga ini sangat ekonomis dibandingkan model sekelas di pasaran.
Dari sisi teknis, LongCat-Flash terutama menargetkan dua tujuan model bahasa: efisiensi komputasi dan kemampuan agen cerdas, serta menggabungkan inovasi arsitektur dan metode pelatihan multi-tahap untuk mewujudkan sistem model yang dapat diskalakan dan cerdas.
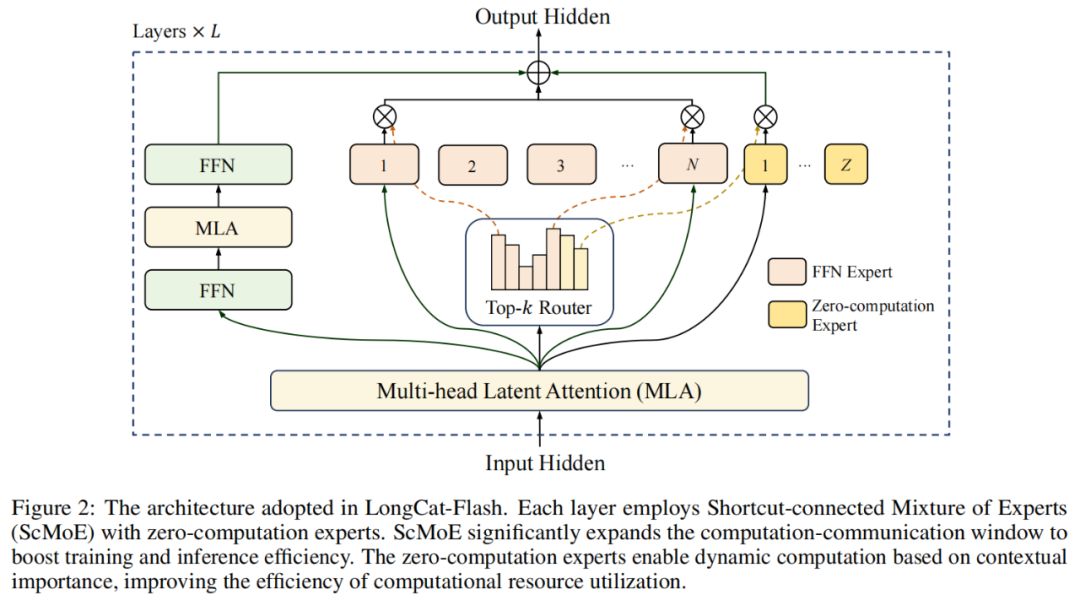
Dari sisi arsitektur model, LongCat-Flash mengadopsi arsitektur MoE (Mixture of Experts) yang inovatif (Gambar 2), dengan dua keunggulan utama:
Zero-computation Experts;
Shortcut-connected MoE (ScMoE).
Zero-computation Experts
Inti dari zero-computation experts adalah tidak semua token itu "setara".
Kita bisa memahaminya seperti ini: dalam sebuah kalimat, ada kata yang sangat mudah diprediksi, seperti "di", "adalah", hampir tidak butuh komputasi, sementara kata seperti "nama orang" butuh komputasi besar untuk diprediksi secara akurat.
Pada penelitian sebelumnya, umumnya digunakan cara: baik token itu sederhana atau kompleks, tetap mengaktifkan jumlah expert tetap (K), yang menyebabkan pemborosan komputasi besar. Untuk token sederhana, tidak perlu memanggil banyak expert, sementara untuk token kompleks, mungkin justru kekurangan alokasi komputasi.
Terinspirasi dari hal ini, LongCat-Flash mengusulkan mekanisme alokasi sumber daya komputasi dinamis: melalui zero-computation experts, setiap token secara dinamis mengaktifkan jumlah FFN (Feed-Forward Network) expert yang berbeda, sehingga alokasi komputasi lebih rasional sesuai tingkat kepentingan konteks.
Secara spesifik, dalam pool expert LongCat-Flash, selain N expert FFN standar, juga ditambahkan Z zero-computation experts. Zero-computation experts hanya mengembalikan input sebagai output, sehingga tidak menambah beban komputasi.
Modul MoE pada LongCat-Flash dapat diformalkan sebagai berikut:
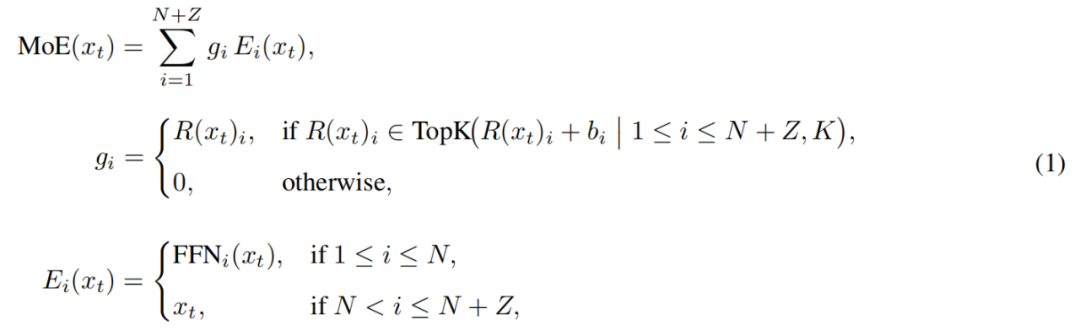
Di mana x_t adalah token ke-t pada urutan input, R adalah softmax router, b_i adalah bias expert ke-i, K adalah jumlah expert yang dipilih setiap token. Router akan mendistribusikan setiap token ke K expert, di mana jumlah FFN expert yang diaktifkan akan berubah sesuai tingkat kepentingan konteks token tersebut. Dengan mekanisme alokasi adaptif ini, model dapat belajar untuk mendistribusikan lebih banyak sumber daya komputasi pada token yang lebih penting dalam konteks, sehingga menghasilkan performa lebih baik pada beban komputasi yang sama, seperti ditunjukkan pada Gambar 3a.
Selain itu, saat memproses input, model harus belajar untuk memutuskan apakah perlu mengalokasikan lebih banyak sumber daya komputasi sesuai tingkat kepentingan token. Jika tidak mengontrol frekuensi pemilihan zero-computation experts, model mungkin cenderung memilih expert yang melakukan komputasi, mengabaikan peran zero-computation experts, sehingga efisiensi sumber daya komputasi menjadi rendah.
Untuk mengatasi masalah ini, Meituan memperbaiki mekanisme bias expert pada strategi aux-loss-free: dengan menambahkan bias khusus expert, bias ini dapat menyesuaikan skor routing secara dinamis sesuai penggunaan expert terbaru, sekaligus tetap terpisah dari tujuan pelatihan model bahasa.
Aturan pembaruan menggunakan PID controller dari teori kontrol untuk menyesuaikan bias expert secara real-time. Berkat ini, saat memproses setiap token, model hanya perlu mengaktifkan 18.6 billions hingga 31.3 billions (rata-rata sekitar 27 billions) parameter, sehingga mengoptimalkan konfigurasi sumber daya.
Shortcut-connected MoE
Keunggulan lain LongCat-Flash adalah mekanisme shortcut-connected MoE.
Secara umum, efisiensi model MoE skala besar sangat dipengaruhi oleh overhead komunikasi. Pada paradigma eksekusi tradisional, expert parallelism akan memperkenalkan workflow berurutan, yaitu harus melakukan komunikasi global untuk merutekan token ke expert yang ditentukan sebelum komputasi dapat dimulai.
Urutan komunikasi lalu komputasi ini menambah waktu tunggu ekstra, terutama pada pelatihan terdistribusi skala besar, latensi komunikasi akan meningkat signifikan dan menjadi bottleneck performa.
Sebelumnya, beberapa peneliti menggunakan arsitektur shared expert, mencoba mengatasi masalah dengan menumpuk komunikasi dan komputasi expert tunggal, namun efisiensinya terbatas oleh window komputasi expert tunggal yang terlalu kecil.
Meituan mengatasi batasan ini dengan memperkenalkan arsitektur ScMoE, yang menambahkan shortcut antar layer, inovasi kunci ini memungkinkan: komputasi FFN dense pada layer sebelumnya dapat berjalan paralel dengan operasi komunikasi distribusi/agregasi pada layer MoE saat ini, dibandingkan arsitektur shared expert, membentuk window overlap komunikasi-komputasi yang lebih besar.
Desain arsitektur ini telah divalidasi dalam berbagai eksperimen.
Pertama, desain ScMoE tidak menurunkan kualitas model. Seperti terlihat pada Gambar 4, performa kurva loss pelatihan arsitektur ScMoE hampir identik dengan baseline tanpa ScMoE, membuktikan bahwa cara eksekusi yang diurutkan ulang ini tidak merusak performa model. Kesimpulan ini konsisten pada berbagai konfigurasi.
Lebih penting lagi, hasil ini menunjukkan: stabilitas dan keunggulan performa ScMoE bersifat orthogonal terhadap pilihan mekanisme atensi (artinya, apapun mekanisme atensi yang digunakan, tetap stabil dan menguntungkan).
Kedua, arsitektur ScMoE memberikan banyak peningkatan efisiensi sistem pada pelatihan dan inferensi. Secara spesifik:
Pada pelatihan skala besar: window overlap yang diperluas memungkinkan komputasi blok sebelumnya berjalan paralel penuh dengan tahap komunikasi distribusi dan agregasi pada layer MoE, ini dicapai dengan membagi operasi ke blok granularitas halus sepanjang dimensi token.
Pada inferensi efisien: ScMoE mendukung pipeline overlap single batch, dibandingkan model terdepan seperti DeepSeek-V3, menurunkan waktu output token per detik (TPOT) teoritis hampir 50%. Lebih penting lagi, memungkinkan eksekusi paralel mode komunikasi berbeda: komunikasi tensor paralel dalam node pada FFN dense (melalui NVLink) dapat overlap penuh dengan komunikasi expert paralel antar node (melalui RDMA), memaksimalkan utilisasi jaringan secara keseluruhan.
Singkatnya, ScMoE memberikan banyak peningkatan performa tanpa mengorbankan kualitas model.
Strategi ekspansi model dan pelatihan multi-tahap
Meituan juga mengusulkan strategi ekspansi model yang efisien, yang secara signifikan meningkatkan performa model saat skalanya diperbesar.
Pertama adalah transfer hyperparameter, saat melatih model skala sangat besar, mencoba berbagai konfigurasi hyperparameter secara langsung sangat mahal dan tidak stabil. Maka Meituan lebih dulu bereksperimen pada model kecil, menemukan kombinasi hyperparameter terbaik, lalu mentransfer parameter tersebut ke model besar. Ini menghemat biaya dan memastikan hasil. Aturan transfer seperti pada Tabel 1:
Kedua adalah inisialisasi pertumbuhan model (Model Growth), Meituan memulai dari model setengah skala yang sudah pretraining pada ratusan miliar token, setelah selesai pelatihan disimpan checkpoint-nya. Berdasarkan itu, model diperluas ke skala penuh dan pelatihan dilanjutkan.
Berdasarkan cara ini, model menunjukkan kurva loss khas: loss naik sebentar, lalu cepat konvergen, dan akhirnya jauh lebih baik dari baseline inisialisasi acak. Gambar 5b menunjukkan hasil representatif pada eksperimen 6B parameter aktif, menampilkan keunggulan inisialisasi pertumbuhan model.
Poin ketiga adalah paket stabilitas multi-level, Meituan meningkatkan stabilitas pelatihan LongCat-Flash dari tiga aspek: stabilitas router, stabilitas aktivasi, dan stabilitas optimizer.
Poin keempat adalah komputasi deterministik, metode ini memastikan hasil eksperimen sepenuhnya dapat direproduksi, serta mendeteksi kerusakan data diam-diam (Silent Data Corruption, SDC) selama pelatihan.
Dengan langkah-langkah ini, proses pelatihan LongCat-Flash selalu sangat stabil, tanpa lonjakan loss yang tidak dapat dipulihkan.
Dengan menjaga stabilitas pelatihan, Meituan juga merancang pipeline pelatihan dengan cermat, sehingga LongCat-Flash memiliki perilaku agen cerdas tingkat lanjut, proses ini mencakup pretraining skala besar, pelatihan menengah untuk kemampuan penalaran dan kode, serta pelatihan akhir yang fokus pada dialog dan penggunaan alat.
Pada tahap awal, membangun model dasar yang lebih cocok untuk pelatihan akhir agen cerdas, untuk itu Meituan merancang strategi penggabungan data pretraining dua tahap untuk memusatkan data pada domain intensif penalaran.
Pada tahap menengah pelatihan, Meituan lebih lanjut meningkatkan kemampuan penalaran dan kode model; sekaligus memperluas panjang konteks hingga 128k, untuk memenuhi kebutuhan pelatihan akhir agen cerdas.
Terakhir, Meituan melakukan pelatihan akhir multi-tahap. Mengingat kelangkaan data pelatihan berkualitas tinggi dan sulit di bidang agen cerdas, Meituan merancang kerangka sintesis multi-agen: kerangka ini mendefinisikan tingkat kesulitan tugas dari tiga dimensi, yaitu pemrosesan informasi, kompleksitas alat, dan interaksi pengguna, menggunakan controller khusus untuk menghasilkan tugas kompleks yang membutuhkan penalaran iteratif dan interaksi lingkungan.
Desain ini membuatnya unggul dalam menjalankan tugas kompleks yang membutuhkan pemanggilan alat dan interaksi lingkungan.
Berjalan cepat dan murah
Bagaimana LongCat-Flash melakukannya?
Seperti disebutkan sebelumnya, LongCat-Flash dapat melakukan inferensi pada kartu grafis H800 dengan kecepatan lebih dari 100 token per detik, dan biaya hanya 0,7 dolar AS per satu juta output token — benar-benar cepat dan murah.
Bagaimana caranya? Pertama, mereka memiliki arsitektur inferensi paralel yang dirancang selaras dengan arsitektur model; kedua, mereka juga menambahkan optimasi seperti kuantisasi dan kernel kustom.
Optimasi khusus: Membuat model "berjalan lancar sendiri"
Kita tahu, untuk membangun sistem inferensi yang efisien, harus menyelesaikan dua masalah kunci: koordinasi komputasi dan komunikasi, serta pembacaan dan penyimpanan cache KV.
Untuk tantangan pertama, metode yang ada biasanya memanfaatkan paralelisme pada tiga granularitas: overlap tingkat operator, overlap tingkat expert, dan overlap tingkat layer. Arsitektur ScMoE LongCat-Flash memperkenalkan dimensi keempat — overlap tingkat modul. Untuk itu, tim merancang strategi penjadwalan SBO (Single Batch Overlap) untuk mengoptimalkan latensi dan throughput.
SBO adalah eksekusi pipeline empat tahap, overlap tingkat modul ini memaksimalkan potensi LongCat-Flash, seperti pada Gambar 9. Perbedaan SBO dengan TBO adalah menyembunyikan overhead komunikasi dalam satu batch. Pada tahap pertama dilakukan komputasi MLA, menyediakan input untuk tahap berikutnya; tahap kedua meng-overlap Dense FFN dan Attn 0 (proyeksi QKV) dengan komunikasi dispatch all-to-all; tahap ketiga menjalankan MoE GEMM secara independen, latensinya diuntungkan oleh strategi deployment EP yang luas; tahap keempat meng-overlap Attn 1 (core attention dan output projection) serta Dense FFN dengan combine all-to-all. Desain ini secara efektif mengurangi overhead komunikasi, memastikan inferensi LongCat-Flash tetap efisien.
Untuk tantangan kedua — pembacaan dan penyimpanan cache KV — LongCat-Flash mengatasinya melalui inovasi arsitektur pada mekanisme atensi dan struktur MTP, untuk mengurangi overhead I/O yang efektif.
Pertama adalah percepatan decoding spekulatif. LongCat-Flash menggunakan MTP sebagai model draft, melalui analisis sistem mengoptimalkan tiga faktor kunci pada formula percepatan decoding spekulatif: panjang penerimaan yang diharapkan, rasio biaya antara model draft dan target, serta rasio biaya verifikasi dan decoding target. Dengan mengintegrasikan satu kepala MTP dan memperkenalkannya pada tahap akhir pretraining, dicapai tingkat penerimaan sekitar 90%. Untuk menyeimbangkan kualitas draft dan kecepatan, digunakan arsitektur MTP ringan untuk mengurangi parameter, serta metode C2T untuk memfilter token yang tidak mungkin diterima melalui model klasifikasi.
Kedua adalah optimasi cache KV, melalui mekanisme atensi 64-head MLA. MLA menjaga keseimbangan performa dan efisiensi, secara signifikan mengurangi beban komputasi dan mencapai kompresi cache KV yang luar biasa, mengurangi tekanan penyimpanan dan bandwidth. Ini sangat penting untuk koordinasi pipeline LongCat-Flash, karena model selalu memiliki komputasi atensi yang tidak bisa di-overlap dengan komunikasi.
Optimasi tingkat sistem: Membuat hardware "bekerja sama"
Untuk meminimalkan overhead penjadwalan, tim riset LongCat-Flash mengatasi masalah launch-bound yang disebabkan overhead kernel start pada sistem inferensi LLM. Khususnya setelah memperkenalkan decoding spekulatif, penjadwalan terpisah antara kernel verifikasi dan forward draft menghasilkan overhead signifikan. Melalui strategi TVD fusion, mereka menggabungkan forward target, verifikasi, dan forward draft ke dalam satu CUDA graph. Untuk lebih meningkatkan utilisasi GPU, mereka menerapkan overlapped scheduler, serta memperkenalkan multi-step overlapped scheduler yang meluncurkan beberapa langkah forward kernel dalam satu iterasi penjadwalan, secara efektif menyembunyikan overhead penjadwalan dan sinkronisasi CPU.
Optimasi kernel kustom ditujukan pada tantangan efisiensi unik dari sifat autoregresif inferensi LLM. Tahap prefill sangat intensif komputasi, sedangkan tahap decoding seringkali terbatas memori karena ukuran batch kecil dan tidak teratur akibat pola aliran. Untuk MoE GEMM, mereka menggunakan teknik SwapAB yang memperlakukan bobot sebagai matriks kiri dan aktivasi sebagai matriks kanan, memanfaatkan fleksibilitas granularitas 8 elemen pada dimensi n untuk memaksimalkan utilisasi tensor core. Kernel komunikasi memanfaatkan akselerasi hardware NVLink Sharp untuk broadcast dan in-switch reduction, meminimalkan perpindahan data dan occupancy SM, hanya dengan 4 thread block dapat terus mengungguli NCCL dan MSCCL++ pada rentang ukuran pesan 4KB hingga 96MB.
Dari sisi kuantisasi, LongCat-Flash menggunakan skema kuantisasi blok granularitas halus yang sama dengan DeepSeek-V3. Untuk mencapai trade-off performa-akurasi terbaik, diterapkan kuantisasi presisi campuran tingkat layer berdasarkan dua skema: skema pertama mengidentifikasi beberapa layer linear (terutama Downproj) dengan aktivasi input ekstrem hingga 10^6; skema kedua menghitung error kuantisasi blok FP8 per layer, menemukan error signifikan pada layer expert tertentu. Dengan mengambil irisan kedua skema, diperoleh peningkatan akurasi signifikan.
Data nyata: Seberapa cepat? Seberapa murah?
Performa nyata menunjukkan LongCat-Flash tampil luar biasa pada berbagai pengaturan. Dibandingkan DeepSeek-V3, pada panjang konteks serupa, LongCat-Flash mencapai throughput generasi lebih tinggi dan kecepatan generasi lebih cepat.
Pada aplikasi Agent, dengan mempertimbangkan perbedaan kebutuhan antara konten inferensi (terlihat pengguna, harus sesuai kecepatan baca manusia sekitar 20 tokens/s) dan perintah aksi (tidak terlihat pengguna tapi langsung mempengaruhi waktu mulai pemanggilan alat, butuh kecepatan maksimal), kecepatan generasi LongCat-Flash hampir 100 tokens/s membuat latensi pemanggilan alat per putaran kurang dari 1 detik, sangat meningkatkan interaktivitas aplikasi Agent. Dengan asumsi biaya H800 GPU 2 dolar AS per jam, ini berarti harga per satu juta output token adalah 0,7 dolar AS.
Analisis performa teoritis menunjukkan, latensi LongCat-Flash terutama ditentukan oleh tiga komponen: MLA, all-to-all dispatch/combine, dan MoE. Pada EP=128, batch per kartu=96, tingkat penerimaan MTP≈80%, batas teoritis TPOT LongCat-Flash adalah 16ms, jauh lebih baik dibandingkan DeepSeek-V3 (30ms) dan Qwen3-235B-A22B (26,2ms). Dengan asumsi biaya H800 GPU 2 dolar AS per jam, biaya output LongCat-Flash adalah 0,09 dolar AS per satu juta token, jauh lebih rendah dari DeepSeek-V3 (0,17 dolar AS). Namun, angka ini hanya batas teoritis.
Pada halaman uji coba gratis LongCat-Flash, kami juga melakukan pengujian.
Kami pertama-tama meminta model besar ini menulis artikel tentang musim gugur, sekitar 1000 kata.
Begitu kami mengajukan permintaan dan mulai merekam layar, LongCat-Flash langsung menuliskan jawabannya, bahkan rekaman belum sempat dimatikan tepat waktu.
Jika diperhatikan, kecepatan output token pertama LongCat-Flash sangat cepat. Biasanya saat menggunakan model dialog lain, seringkali harus menunggu lama, sangat menguji kesabaran pengguna, seperti saat ingin cepat-cepat membaca pesan di WeChat tapi sinyal ponsel menunjukkan "mengambil". LongCat-Flash mengubah pengalaman ini, hampir tidak terasa ada delay pada token pertama.
Kecepatan generasi token berikutnya juga sangat cepat, jauh melampaui kecepatan baca mata manusia.
Selanjutnya, kami mengaktifkan "pencarian online", untuk melihat apakah kemampuan LongCat-Flash cukup cepat. Kami meminta LongCat-Flash merekomendasikan restoran enak di sekitar Wangjing.
Hasil pengujian menunjukkan, LongCat-Flash tidak perlu berpikir lama sebelum menjawab, melainkan hampir langsung memberikan jawaban. Pencarian online juga terasa "cepat". Selain itu, saat output cepat, model juga menyertakan sumber referensi, sehingga kredibilitas dan keterlacakan informasi tetap terjamin.
Pembaca yang bisa mengunduh model dapat mencoba menjalankan LongCat-Flash secara lokal, untuk melihat apakah kecepatannya juga mengesankan.
Saat model besar memasuki era praktis
Beberapa tahun terakhir, setiap kali muncul model besar, semua orang pasti bertanya: berapa skor benchmark-nya? Berapa banyak ranking yang dipecahkan? Apakah SOTA? Kini, situasinya telah berubah. Dengan kemampuan yang hampir setara, orang lebih peduli: apakah model ini mahal digunakan? Bagaimana kecepatannya? Di kalangan perusahaan dan pengembang yang menggunakan model open source, hal ini sangat terasa. Karena banyak pengguna memilih model open source untuk mengurangi ketergantungan dan biaya API closed source, sehingga lebih sensitif terhadap kebutuhan daya komputasi, kecepatan inferensi, dan hasil kompresi kuantisasi.
LongCat-Flash open source dari Meituan adalah contoh yang mengikuti tren ini. Mereka memfokuskan pada bagaimana membuat model besar benar-benar terjangkau dan berjalan cepat, ini adalah kunci adopsi teknologi secara luas.
Pilihan jalur praktis ini juga konsisten dengan kesan kami terhadap Meituan selama ini. Dulu, sebagian besar investasi teknologi mereka digunakan untuk menyelesaikan masalah bisnis nyata, misalnya pada 2022 memenangkan ICRA Best Navigation Paper dengan EDPLVO, yang sebenarnya untuk mengatasi berbagai kejadian tak terduga pada drone selama pengantaran (misal kehilangan sinyal karena gedung terlalu rapat); baru-baru ini ikut menyusun standar ISO global untuk penghindaran rintangan drone, yang merupakan akumulasi pengalaman teknis dari kasus drone menghindari benang layangan, tali pembersih kaca, dsb. Kali ini, LongCat-Flash open source sebenarnya adalah model di balik alat pemrograman AI "NoCode" mereka, alat ini melayani internal perusahaan sekaligus dibuka gratis ke publik, dengan harapan semua orang bisa menggunakan vibe coding untuk menurunkan biaya dan meningkatkan efisiensi.
Perubahan dari kompetisi performa ke orientasi praktis ini sebenarnya mencerminkan hukum alam perkembangan industri AI. Ketika kemampuan model mulai setara, efisiensi rekayasa dan biaya deployment menjadi faktor pembeda utama. Open source LongCat-Flash hanyalah satu contoh dari tren ini, namun memang memberikan jalur teknis yang bisa dijadikan referensi oleh komunitas: bagaimana menurunkan ambang penggunaan melalui inovasi arsitektur dan optimasi sistem tanpa mengorbankan kualitas model. Bagi pengembang dan perusahaan dengan anggaran terbatas namun ingin memanfaatkan kemampuan AI canggih, ini jelas sangat berharga.
Disclaimer: Konten pada artikel ini hanya merefleksikan opini penulis dan tidak mewakili platform ini dengan kapasitas apa pun. Artikel ini tidak dimaksudkan sebagai referensi untuk membuat keputusan investasi.
Kamu mungkin juga menyukai
ETH Mengambil Alih Panggung: Awal Sebenarnya Paruh Kedua Bull Market
Berdasarkan struktur pasar, aliran dana, data on-chain, serta lingkungan kebijakan, penilaian kami sangat jelas: Ethereum secara bertahap menggantikan Bitcoin dan menjadi aset inti pada paruh kedua bull market.

Strategi BTC di Era Blockchain Publik Berkinerja Tinggi: Transformasi Solana dan Modal On-chain
Persaingan di era public chain berkinerja tinggi pada akhirnya bukan semata-mata perlombaan TPS, melainkan siapa yang mampu membangun ekosistem ekonomi on-chain yang lebih aktif dan efisien.

WLFI secara strategis menginkubasi BlockRock, menciptakan mesin baru untuk derivatif keuangan RWA
Kerja sama ini tidak hanya menandai upaya mendalam WLFI di jalur RWA, tetapi juga menetapkan BlockRock sebagai platform inti RWA dalam ekosistemnya.

Ekspansi Perusahaan ke Luar Negeri: Pilihan Arsitektur dan Strategi Optimasi Pajak
Seberapa pentingkah arsitektur perusahaan yang sesuai?
