
Vitalik: Glue at co-processor architecture, bagong ideya para mapataas ang kahusayan at seguridad

Ang gluer ay dapat i-optimize upang maging isang mahusay na gluer, habang ang co-processor ay dapat ding i-optimize upang maging isang mahusay na co-processor.
Ang glue ay dapat i-optimize upang maging isang mahusay na glue, at ang coprocessor ay dapat ding i-optimize upang maging isang mahusay na coprocessor.
Orihinal na Pamagat: "Glue and coprocessor architectures"
May-akda: Vitalik Buterin, Tagapagtatag ng Ethereum
Pagsasalin: Deng Tong, Jinse Finance
Espesyal na pasasalamat kina Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra at iba't ibang Flashbots contributors para sa kanilang feedback at mga komento.
Kung susuriin mo nang may katamtamang detalye ang alinmang resource-intensive na computation sa modernong mundo, paulit-ulit mong makikita ang isang katangian: ang computation ay maaaring hatiin sa dalawang bahagi:
- Isang relatibong maliit na dami ng kumplikado ngunit hindi masyadong computation-heavy na "business logic";
- Malaking dami ng intensive ngunit highly structured na "mahal na trabaho".
Ang dalawang anyo ng computation na ito ay pinakamahusay na pinoproseso sa magkaibang paraan: ang una, na maaaring hindi ganoon kaepektibo ang arkitektura ngunit nangangailangan ng napakataas na generality; ang huli, na maaaring may mas mababang generality, ngunit nangangailangan ng napakataas na efficiency.
Ano ang mga halimbawa ng ganitong iba't ibang paraan sa praktika?
Una, tingnan natin ang environment na pinakakilala ko: ang Ethereum Virtual Machine (EVM). Ito ay isang geth debug trace ng isang kamakailang Ethereum transaction ko: pag-update ng IPFS hash ng aking blog sa ENS. Ang transaction na ito ay gumamit ng kabuuang 46924 gas, na maaaring ikategorya sa ganitong paraan:
- Pangunahing gastos: 21,000
- Call data: 1,556
- EVM execution: 24,368
- SLOAD opcode: 6,400
- SSTORE opcode: 10,100
- LOG opcode: 2,149
- Iba pa: 6,719

EVM trace ng ENS hash update. Ang pangalawang huling column ay ang gas consumption.
Ang aral ng kwentong ito ay: karamihan ng execution (kung EVM lang ang titingnan, mga 73%, kung isasama ang bahagi ng base cost na sumasaklaw sa computation, mga 85%) ay nakatuon sa iilang highly structured na mahal na operasyon: storage reads at writes, logs, at cryptography (ang base cost ay may kasamang 3000 para sa signature verification, at ang EVM ay may kasamang 272 para sa hash). Ang natitirang execution ay "business logic": pagpapalit ng calldata bits para kunin ang ID ng record na sinusubukan kong i-set at ang hash na itatakda ko dito, atbp. Sa token transfer, ito ay kinabibilangan ng pagdagdag at pagbabawas ng balanse, sa mas advanced na application, maaaring may kasamang loops, atbp.
Sa EVM, ang dalawang anyo ng execution na ito ay pinoproseso sa magkaibang paraan. Ang high-level business logic ay isinusulat sa mas mataas na antas na wika, kadalasan ay Solidity, na maaaring i-compile sa EVM. Ang mahal na trabaho ay pinapagana pa rin ng EVM opcodes (tulad ng SLOAD), ngunit mahigit 99% ng aktwal na computation ay ginagawa sa mga dedicated module na direkta nang isinulat sa client code (o kahit sa library).
Para mapalalim ang pag-unawa sa pattern na ito, tuklasin natin ito sa ibang konteksto: AI code na isinulat gamit ang torch sa python.
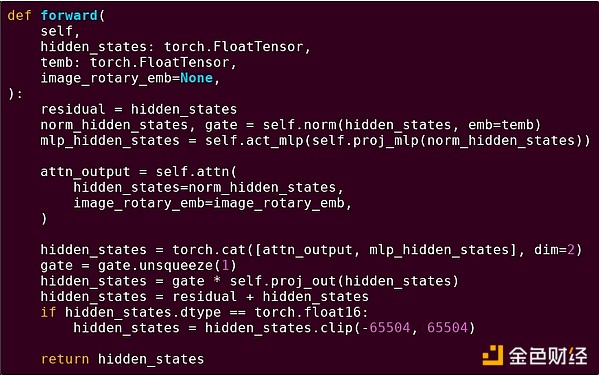
Isang forward pass ng isang block ng transformer model
Ano ang nakikita natin dito? Nakikita natin ang isang relatibong maliit na dami ng "business logic" na isinulat sa Python, na naglalarawan ng estruktura ng mga operasyon na isinasagawa. Sa aktwal na aplikasyon, may isa pang uri ng business logic na nagdedesisyon ng mga detalye gaya ng paano kunin ang input at anong gagawin sa output. Ngunit kung susuriin natin ang bawat indibidwal na operasyon (self.norm, torch.cat, +, *, mga hakbang sa loob ng self.attn...), makikita natin ang vectorized computation: parehong operasyon ang sabay-sabay na ginagawa sa maraming halaga. Katulad ng unang halimbawa, maliit na bahagi ng computation ang napupunta sa business logic, karamihan ay napupunta sa pagsasagawa ng malalaking structured matrix at vector operations — sa katunayan, karamihan ay matrix multiplication lang.
Tulad ng sa EVM na halimbawa, ang dalawang uri ng trabaho ay pinoproseso sa magkaibang paraan. Ang high-level business logic code ay isinulat sa Python, isang highly general at flexible na wika, ngunit napakabagal din — tinatanggap lang natin ang inefficiency dahil maliit lang ang bahagi nito sa kabuuang computation cost. Samantala, ang intensive operations ay isinulat sa highly optimized na code, kadalasan ay CUDA code na tumatakbo sa GPU. Nakikita na rin natin ngayon na ang LLM inference ay ginagawa na sa ASIC.
Ang modernong programmable cryptography, tulad ng SNARK, ay sumusunod muli sa katulad na pattern sa dalawang antas. Una, ang prover ay maaaring isulat sa high-level na wika, kung saan ang mabigat na trabaho ay ginagawa sa vectorized operations, tulad ng AI example sa itaas. Ang circular STARK code ko rito ay nagpapakita nito. Pangalawa, ang mismong program na isinasagawa sa loob ng cryptography ay maaaring isulat sa paraang nahahati sa general business logic at highly structured na mahal na trabaho.
Para maintindihan kung paano ito gumagana, tingnan natin ang isa sa mga pinakabagong trend sa STARK proofs. Para maging general at madaling gamitin, parami nang parami ang mga team na gumagawa ng STARK provers para sa widely adopted na minimal virtual machines gaya ng RISC-V. Anumang program na kailangang patunayan ang execution ay maaaring i-compile sa RISC-V, at pagkatapos ay mapapatunayan ng prover ang RISC-V execution ng code na iyon.
Chart mula sa RiscZero documentation
Napakakombinyente nito: nangangahulugan ito na kailangan lang nating isulat ang proof logic nang isang beses, at mula noon, anumang program na kailangang patunayan ay maaaring isulat sa anumang "tradisyonal" na programming language (halimbawa, sinusuportahan ng RiskZero ang Rust). Ngunit may isang problema: ang approach na ito ay nagdadala ng malaking overhead. Ang programmable cryptography ay napakamahal na; ang dagdag na overhead ng pagpapatakbo ng code sa loob ng RISC-V interpreter ay masyadong malaki. Kaya, nakaisip ang mga developer ng isang trick: tukuyin ang mga partikular na mahal na operasyon na bumubuo sa karamihan ng computation (karaniwan ay hashing at signatures), at pagkatapos ay gumawa ng mga dedicated module para napaka-epektibong patunayan ang mga operasyong ito. Pagkatapos, pagsamahin lang ang inefficient ngunit general na RISC-V proof system at ang efficient ngunit specialized na proof system para makuha ang best of both worlds.
Maliban sa ZK-SNARK, ang ibang programmable cryptography gaya ng multi-party computation (MPC) at fully homomorphic encryption (FHE) ay maaaring gumamit ng katulad na paraan ng optimization.
Sa kabuuan, ano ang phenomenon?
Ang modernong computation ay lalong sumusunod sa tinatawag kong glue at coprocessor architecture: mayroon kang ilang central na "glue" component, na may mataas na generality ngunit mababa ang efficiency, na responsable sa paglipat ng data sa isa o higit pang coprocessor components, na may mababang generality ngunit mataas ang efficiency.
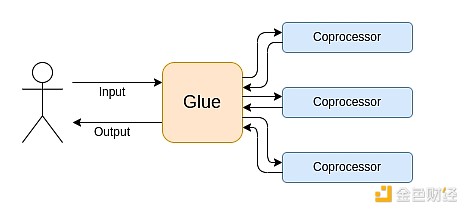
Isa itong simplification: sa praktika, ang tradeoff curve sa pagitan ng efficiency at generality ay halos palaging may higit sa dalawang layer. Ang GPU at iba pang chips na karaniwang tinatawag na "coprocessor" sa industriya ay hindi kasing-general ng CPU, ngunit mas general kaysa sa ASIC. Ang tradeoff ng specialization ay komplikado, depende sa prediksyon at intuition kung aling bahagi ng algorithm ang mananatiling pareho pagkalipas ng limang taon, at alin ang magbabago pagkalipas ng anim na buwan. Sa ZK proof architectures, madalas din nating makita ang katulad na multi-layer specialization. Ngunit para sa malawakang mental model, sapat na ang pag-isip ng dalawang layer. Sa maraming computation fields, may katulad na sitwasyon:
Mula sa mga halimbawa sa itaas, malinaw na maaaring hatiin ang computation sa ganitong paraan, na tila isang natural na batas. Sa katunayan, makakahanap ka ng mga halimbawa ng computation specialization sa loob ng mga dekada. Gayunpaman, naniniwala akong tumitindi ang separation na ito. Naniniwala akong may dahilan ito:
Kamakailan lang natin naabot ang limitasyon ng CPU clock speed improvements, kaya tanging sa pamamagitan ng parallelization lang makakakuha ng karagdagang benepisyo. Ngunit mahirap i-reason ang parallelization, kaya para sa mga developer, mas praktikal na magpatuloy sa sequential reasoning at hayaan ang parallelization na mangyari sa backend, na naka-wrap sa mga dedicated module na ginawa para sa partikular na operasyon.
Kamakailan lang naging napakabilis ng computation kaya ang computation cost ng business logic ay naging tunay na negligible. Sa mundong ito, may saysay na i-optimize ang VM na nagpapatakbo ng business logic para sa mga layunin bukod sa computation efficiency: developer-friendliness, familiarity, security, at iba pang katulad na layunin. Samantala, ang mga dedicated na "coprocessor" module ay maaaring patuloy na idisenyo para sa efficiency, at makakuha ng kanilang security at developer-friendliness mula sa kanilang relatively simple na "interface" sa glue.
Mas nagiging malinaw kung ano ang pinakamahalagang mahal na operasyon. Pinakamalinaw ito sa cryptography, kung saan malamang na gagamitin ang mga partikular na mahal na operasyon: modular arithmetic, elliptic curve linear combinations (kilala rin bilang multi-scalar multiplication), fast Fourier transforms, atbp. Sa AI, nagiging mas malinaw din ito, sa loob ng mahigit dalawampung taon, karamihan ng computation ay "pangunahin ay matrix multiplication" (bagaman iba-iba ang precision level). Sa ibang field, may katulad na trend. Kumpara sa 20 taon na ang nakalipas, mas kaunti na ang unknown unknowns sa (computation-intensive) computation.
Ano ang ibig sabihin nito?
Isang mahalagang punto ay, ang glue ay dapat i-optimize upang maging isang mahusay na glue, at ang coprocessor ay dapat ding i-optimize upang maging isang mahusay na coprocessor. Maaari nating tuklasin ang kahulugan nito sa ilang mahahalagang larangan.
EVM
Ang blockchain virtual machines (tulad ng EVM) ay hindi kailangang maging efficient, kailangan lang maging pamilyar. Basta't idagdag ang tamang coprocessors (kilala rin bilang "precompiles"), ang computation sa loob ng inefficient VM ay maaaring kasing-efficient ng computation sa native efficient VM. Halimbawa, ang overhead na dulot ng 256-bit registers ng EVM ay relatibong maliit, habang ang benepisyo ng familiarity ng EVM at ng umiiral na developer ecosystem ay napakalaki at pangmatagalan. Natuklasan pa ng mga team na nag-o-optimize ng EVM na ang kakulangan ng parallelization ay kadalasang hindi ang pangunahing hadlang sa scalability.
Ang pinakamahusay na paraan para i-improve ang EVM ay maaaring (i) magdagdag ng mas mahusay na precompiles o dedicated opcodes, halimbawa, isang kombinasyon ng EVM-MAX at SIMD ay maaaring makatwiran, at (ii) pagbutihin ang storage layout, halimbawa, ang pagbabago ng Verkle tree ay bilang side effect, malaki ang binababa ng cost ng pag-access sa magkatabing storage slots.
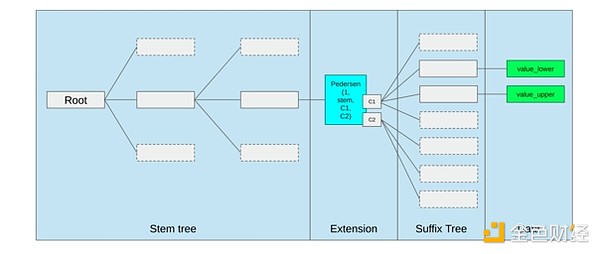
Storage optimization mula sa Ethereum Verkle tree proposal, pinagsasama ang magkatabing storage keys at ina-adjust ang gas cost para i-reflect ito. Ang mga optimization na tulad nito, kasama ang mas mahusay na precompiles, ay maaaring mas mahalaga kaysa sa pag-aadjust ng EVM mismo.
Secure computation at open hardware
Isang malaking hamon sa pagpapataas ng security ng modernong computation sa hardware level ay ang sobrang komplikado at proprietary nitong katangian: ang mga chip ay dinisenyo para sa efficiency, na nangangailangan ng proprietary optimization. Madaling maitago ang backdoors, at patuloy na nadidiskubre ang side-channel vulnerabilities.
Patuloy ang pagsisikap mula sa iba't ibang anggulo para itulak ang mas open at secure na alternatibo. Ang ilang computation ay lalong ginagawa sa trusted execution environments, kabilang na sa mga telepono ng user, na nagtaas na ng security ng user. Patuloy ang kilusan para sa mas open-source consumer hardware, na kamakailan ay nagkaroon ng ilang tagumpay, tulad ng RISC-V laptop na nagpapatakbo ng Ubuntu.
RISC-V laptop na nagpapatakbo ng Debian
Gayunpaman, nananatiling isyu ang efficiency. Ang may-akda ng artikulo sa link sa itaas ay nagsabi:
Ang mga mas bagong open-source chip design tulad ng RISC-V ay imposibleng makipagsabayan sa processor technology na umiiral na at pinabuti sa loob ng mga dekada. Laging may simula ang progreso.
Ang mas paranoid na ideya, tulad ng disenyo ng RISC-V computer sa FPGA, ay may mas malaking overhead. Ngunit paano kung, dahil sa glue at coprocessor architecture, hindi talaga mahalaga ang overhead na ito? Paano kung tanggapin natin na ang open at secure na chips ay magiging mas mabagal kaysa sa proprietary chips, at kung kinakailangan ay isuko ang mga karaniwang optimization tulad ng speculative execution at branch prediction, ngunit subukang bumawi sa pamamagitan ng pagdagdag ng (kung kinakailangan, proprietary) ASIC modules para sa pinaka-intensive na partikular na uri ng computation? Ang sensitibong computation ay maaaring gawin sa "main chip", na i-o-optimize para sa security, open-source design, at side-channel resistance. Ang mas intensive na computation (halimbawa, ZK proofs, AI) ay gagawin sa ASIC modules, na magkakaroon ng mas kaunting kaalaman tungkol sa computation na isinasagawa (maaaring, sa pamamagitan ng cryptographic blinding, sa ilang kaso ay zero-knowledge pa nga).
Cryptography
Isa pang mahalagang punto ay, ang lahat ng ito ay napaka-optimistic para sa cryptography, lalo na sa mainstream adoption ng programmable cryptography. Nakita na natin sa SNARK, MPC, at iba pang setup ang ilang partikular na highly structured computation na sobrang na-optimize: ang overhead ng ilang hash functions ay ilang daang beses lang na mas mahal kaysa sa direktang pagpapatakbo ng computation, at ang overhead ng AI (pangunahin ay matrix multiplication) ay napakababa rin. Ang mga karagdagang improvement tulad ng GKR ay maaaring magpababa pa nito. Ang fully general na VM execution, lalo na kapag pinapatakbo sa RISC-V interpreter, ay maaaring magpatuloy na may overhead na mga sampung libong beses, ngunit dahil sa mga dahilan na inilarawan sa artikulong ito, hindi ito mahalaga: basta't ang pinaka-intensive na bahagi ng computation ay pinoproseso gamit ang efficient na dedicated techniques, ang kabuuang overhead ay manageable.
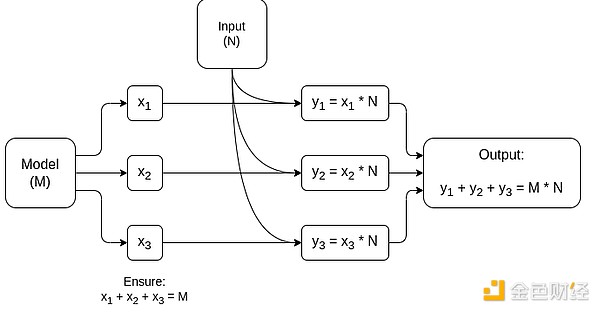
Isang simplified diagram ng matrix multiplication-specific MPC, ang pinakamalaking component sa AI model inference. Tingnan ang artikulong ito para sa karagdagang detalye, kabilang kung paano mapanatili ang privacy ng model at input.
Isang exception sa ideya na "ang glue layer ay kailangan lang maging pamilyar, hindi efficient" ay ang latency, at sa mas maliit na antas, ang data bandwidth. Kung ang computation ay kinabibilangan ng mabibigat na operasyon na inuulit ng dose-dosenang beses sa parehong data (tulad ng sa cryptography at AI), anumang latency na dulot ng inefficient glue layer ay maaaring maging pangunahing bottleneck ng runtime. Kaya, may efficiency requirements din ang glue layer, kahit na mas specific ang mga ito.
Konklusyon
Sa kabuuan, naniniwala akong ang mga trend na inilarawan sa itaas ay napakapositibong development mula sa maraming anggulo. Una, ito ay isang makatwirang paraan upang i-maximize ang computation efficiency habang pinapanatili ang developer-friendliness, na nagbibigay ng higit pa sa parehong benepisyo para sa lahat. Lalo na, sa pamamagitan ng specialization sa client side para sa efficiency, pinapataas nito ang kakayahan nating magpatakbo ng sensitibo at performance-critical na computation (halimbawa, ZK proofs, LLM inference) nang lokal sa user hardware. Pangalawa, lumilikha ito ng malaking window of opportunity upang matiyak na ang pursuit of efficiency ay hindi makokompromiso ang ibang values, pinakakilala ang security, openness, at simplicity: side-channel security at openness sa computer hardware, pagbawas ng circuit complexity sa ZK-SNARK, at pagbawas ng complexity sa virtual machine. Historically, ang pursuit of efficiency ay nagiging dahilan para maisantabi ang mga ibang factor na ito. Sa glue at coprocessor architecture, hindi na ito kailangan. Ang isang bahagi ng machine ay na-optimize para sa efficiency, ang isa pa para sa generality at ibang values, at nagtutulungan ang dalawa.
Napakabuti rin ng trend na ito para sa cryptography, dahil ang cryptography mismo ay isang pangunahing halimbawa ng "mahal na structured computation", at pinapabilis ng trend na ito ang pag-unlad nito. Nagbibigay ito ng isa pang pagkakataon para mapataas ang security. Sa blockchain world, posible ring mapataas ang security: mas kaunti ang kailangang alalahanin tungkol sa optimization ng virtual machine, at mas maraming focus sa optimization ng precompiles at iba pang function na coexisting sa virtual machine.
Pangatlo, ang trend na ito ay nagbibigay ng pagkakataon para sa mas maliliit at mas bagong participants. Kung ang computation ay nagiging hindi na monolithic kundi mas modular, malaki ang ibinababa nito sa entry barrier. Kahit ASIC para sa isang uri ng computation ay maaaring magkaroon ng impact. Ganoon din sa ZK proof field at EVM optimization. Ang pagsusulat ng code na halos frontier-level ang efficiency ay nagiging mas madali at accessible. Ang pag-audit at formal verification ng ganitong code ay nagiging mas madali at accessible. Sa huli, dahil ang mga napakaibang computation fields na ito ay nagko-converge sa ilang common patterns, mas marami ang space para sa collaboration at pagkatuto sa pagitan nila.
Disclaimer: Ang nilalaman ng artikulong ito ay sumasalamin lamang sa opinyon ng author at hindi kumakatawan sa platform sa anumang kapasidad. Ang artikulong ito ay hindi nilayon na magsilbi bilang isang sanggunian para sa paggawa ng mga desisyon sa investment.
Baka magustuhan mo rin
Sinabi nina Larry Fink at Rob Goldstein ng BlackRock na maaaring gawin ng tokenization para sa pananalapi ang ginawa ng maagang internet para sa impormasyon
Sinabi nina Larry Fink at Rob Goldstein ng BlackRock na ang tokenization ay pumapasok na sa isang yugto na parang maagang internet, na may potensyal na baguhin ang mga merkado nang mas mabilis kaysa inaasahan ng karamihan. Itinuro ng mga executive ang 300% na pagtaas sa real-world asset tokenization sa loob ng 20 buwan bilang ebidensya na ang pagbabagong ito ay nagpapabilis na.

Grayscale hinulaan ang bagong pinakamataas na presyo ng bitcoin sa 2026, tinatanggihan ang pananaw sa 4-taong siklo
Ayon sa Grayscale Research, maaaring umabot ang bitcoin sa bagong pinakamataas na halaga pagsapit ng 2026, na sumasalungat sa mga alalahanin na papasok ito sa isang pangmatagalang pagbagsak. Inaasahan din ng BitMine CEO na si Tom Lee na magtatakda ang bitcoin ng panibagong all-time high pagsapit ng Enero sa susunod na taon.

Nasa Ilalim na ba ang Solana (SOL)? Kumpletong Pagsusuri ng Presyo at Susunod na mga Target
Ang pinakamalaking social platform sa mundo na Telegram ay may malaking update: Maaari mo nang gamitin ang iyong GPU upang magmina ng TON.
Ambisyon ng Telegram para sa Privacy AI
