
2026年初登場、黄仁勲が2.5トンの「核爆弾」を投下|CES2026

原文を表示
著者:爱范儿
*最後にちょっとしたサプライズ動画があります。 これはNVIDIAが5年ぶりにCESでコンシューマ向けGPUを発表しなかった初めての出来事です。 CEOのJensen Huang(黄仁勋)がNVIDIA Liveの舞台中央に堂々と歩いて登場。去年と同じ光沢のあるワニ皮ジャケットを着ていました。  昨年の単独基調講演とは異なり、2026年のJensen Huangはスケジュールが過密です。NVIDIA LiveからSiemensのインダストリアルAIディスカッション、そしてLenovo TechWorldカンファレンスまで、48時間で3つのイベントを駆け抜けました。 前回はCESでRTX 50シリーズGPUを発表しました。今回は、物理AI、ロボティクス、そして重さ2.5トンの「 エンタープライズ級の核兵器 」が真の主役となりました。 Vera Rubinコンピューティングプラットフォームが登場、買えば買うほどお得 発表会中、エンターテイナーとしても知られるJensen Huangは、2.5トンのAIサーバーラックをステージに直接持ち込み、今回の発表の目玉である「Vera Rubinコンピューティングプラットフォーム」を紹介しました。このプラットフォームは、ダークマターを発見した天文学者にちなんで名付けられており、目標はただ一つ: AIトレーニングのスピードを加速し、次世代モデルの到来を早めることです。
昨年の単独基調講演とは異なり、2026年のJensen Huangはスケジュールが過密です。NVIDIA LiveからSiemensのインダストリアルAIディスカッション、そしてLenovo TechWorldカンファレンスまで、48時間で3つのイベントを駆け抜けました。 前回はCESでRTX 50シリーズGPUを発表しました。今回は、物理AI、ロボティクス、そして重さ2.5トンの「 エンタープライズ級の核兵器 」が真の主役となりました。 Vera Rubinコンピューティングプラットフォームが登場、買えば買うほどお得 発表会中、エンターテイナーとしても知られるJensen Huangは、2.5トンのAIサーバーラックをステージに直接持ち込み、今回の発表の目玉である「Vera Rubinコンピューティングプラットフォーム」を紹介しました。このプラットフォームは、ダークマターを発見した天文学者にちなんで名付けられており、目標はただ一つ: AIトレーニングのスピードを加速し、次世代モデルの到来を早めることです。  通常、NVIDIAの社内ルールでは、各世代の製品で変更できるチップは1~2個までとされています。 しかし、今回のVera Rubinはこの常識を打破し、一度に6種類のチップを再設計し、すでに量産体制に入っています。
通常、NVIDIAの社内ルールでは、各世代の製品で変更できるチップは1~2個までとされています。 しかし、今回のVera Rubinはこの常識を打破し、一度に6種類のチップを再設計し、すでに量産体制に入っています。
その理由は、ムーアの法則の鈍化に伴い、従来の性能向上のやり方ではAIモデルの年10倍の成長速度についていけなくなったからです。そこでNVIDIAは「究極の協調設計」を選択しました——すべてのチップとプラットフォームの各レイヤーで同時にイノベーションを行うのです。 この6つのチップは以下の通りです: 1. Vera CPU: - 88個のNVIDIAカスタムOlympusコア - NVIDIA空間マルチスレッディング技術を採用し、176スレッド対応 - NVLink C2C帯域幅1.8TB/s - システムメモリ1.5TB(Graceの3倍) - LPDDR5X帯域幅1.2TB/s - 2270億トランジスタ
この6つのチップは以下の通りです: 1. Vera CPU: - 88個のNVIDIAカスタムOlympusコア - NVIDIA空間マルチスレッディング技術を採用し、176スレッド対応 - NVLink C2C帯域幅1.8TB/s - システムメモリ1.5TB(Graceの3倍) - LPDDR5X帯域幅1.2TB/s - 2270億トランジスタ  2. Rubin GPU: - NVFP4推論性能50PFLOPS、前世代Blackwellの5倍 - 3360億トランジスタを搭載、Blackwell比1.6倍増 - 第三世代Transformerエンジンを搭載し、Transformerモデルの要求に応じて精度を動的に調整可能
2. Rubin GPU: - NVFP4推論性能50PFLOPS、前世代Blackwellの5倍 - 3360億トランジスタを搭載、Blackwell比1.6倍増 - 第三世代Transformerエンジンを搭載し、Transformerモデルの要求に応じて精度を動的に調整可能  3. ConnectX-9 ネットワークカード: - 200G PAM4 SerDesベースの800Gb/sイーサネット - プログラマブルRDMAとデータパスアクセラレーター - CNSAとFIPS認証取得 - 230億トランジスタ
3. ConnectX-9 ネットワークカード: - 200G PAM4 SerDesベースの800Gb/sイーサネット - プログラマブルRDMAとデータパスアクセラレーター - CNSAとFIPS認証取得 - 230億トランジスタ  4. BlueField-4 DPU: - 次世代AIストレージプラットフォーム向けに構築されたエンドツーエンドエンジン - SmartNICとストレージプロセッサー向け800G Gb/s DPU - ConnectX-9と組み合わせた64コアGrace CPU - 1260億トランジスタ
4. BlueField-4 DPU: - 次世代AIストレージプラットフォーム向けに構築されたエンドツーエンドエンジン - SmartNICとストレージプロセッサー向け800G Gb/s DPU - ConnectX-9と組み合わせた64コアGrace CPU - 1260億トランジスタ  5. NVLink-6 スイッチチップ: - 18のコンピュートノードを接続し、最大72個のRubin GPUを一体として協調動作可能 - NVLink 6アーキテクチャ下では、各GPUが3.6TB/秒のall-to-all通信帯域を獲得 - 400G SerDes採用、In-Network SHARP Collectives対応、スイッチネットワーク内部でコレクティブ通信を完結
5. NVLink-6 スイッチチップ: - 18のコンピュートノードを接続し、最大72個のRubin GPUを一体として協調動作可能 - NVLink 6アーキテクチャ下では、各GPUが3.6TB/秒のall-to-all通信帯域を獲得 - 400G SerDes採用、In-Network SHARP Collectives対応、スイッチネットワーク内部でコレクティブ通信を完結  6. Spectrum-6 光イーサネットスイッチチップ - 512チャネル、各チャネル200Gbpsでより高速なデータ転送を実現 - TSMCのCOOPプロセスによるシリコンフォトニクス技術を集積 - 共封装光学インターフェース(copackaged optics)を装備 - 3520億トランジスタ
6. Spectrum-6 光イーサネットスイッチチップ - 512チャネル、各チャネル200Gbpsでより高速なデータ転送を実現 - TSMCのCOOPプロセスによるシリコンフォトニクス技術を集積 - 共封装光学インターフェース(copackaged optics)を装備 - 3520億トランジスタ  6種のチップの深い統合により、Vera Rubin NVL72システムの性能は前世代Blackwellに比べて全方位で向上しました。 NVFP4推論タスクでは、同チップは3.6EFLOPSという驚異的な計算力を達成し、前世代Blackwellアーキテクチャ比で5倍向上。NVFP4トレーニングでは2.5EFLOPSを達成し、3.5倍の性能アップです。 ストレージ容量面では、NVL72は54TBのLPDDR5Xメモリを搭載し、前世代の3倍。HBM(高帯域幅メモリ)容量は20.7TBで1.5倍増。帯域性能はHBM4で1.6PB/s、2.8倍向上。スケールアップ帯域は260TB/sと2倍増です。 これほどの性能向上にもかかわらず、トランジスタ数は1.7倍増の220兆個にとどまり、半導体製造技術の革新力を示しています。
6種のチップの深い統合により、Vera Rubin NVL72システムの性能は前世代Blackwellに比べて全方位で向上しました。 NVFP4推論タスクでは、同チップは3.6EFLOPSという驚異的な計算力を達成し、前世代Blackwellアーキテクチャ比で5倍向上。NVFP4トレーニングでは2.5EFLOPSを達成し、3.5倍の性能アップです。 ストレージ容量面では、NVL72は54TBのLPDDR5Xメモリを搭載し、前世代の3倍。HBM(高帯域幅メモリ)容量は20.7TBで1.5倍増。帯域性能はHBM4で1.6PB/s、2.8倍向上。スケールアップ帯域は260TB/sと2倍増です。 これほどの性能向上にもかかわらず、トランジスタ数は1.7倍増の220兆個にとどまり、半導体製造技術の革新力を示しています。  エンジニアリング設計面でも、Vera Rubinは技術的ブレイクスルーをもたらしました。 これまでスーパーコンピュータノードは43本のケーブル接続が必要で、組立に2時間かかり、ミスも起こりやすかったのですが、Vera Rubinノードはケーブルゼロ、液冷パイプ6本だけで5分で完了。 さらに驚くべきは、ラックの裏側には総延長約3.2kmの銅線が張り巡らされ、5000本の銅線でNVLinkのバックボーンネットワークを構成、400Gbpsの伝送速度を実現。Jensen Huang曰く:「数百ポンドあるかもしれないので、体格のいいCEOじゃないと務まらないよ」とのこと。 AI業界では「時間=金」。重要なデータとして、100兆パラメータのモデルをトレーニングする場合、RubinはBlackwellシステムの1/4台数で済み、Token生成コストはBlackwellの約1/10です。
エンジニアリング設計面でも、Vera Rubinは技術的ブレイクスルーをもたらしました。 これまでスーパーコンピュータノードは43本のケーブル接続が必要で、組立に2時間かかり、ミスも起こりやすかったのですが、Vera Rubinノードはケーブルゼロ、液冷パイプ6本だけで5分で完了。 さらに驚くべきは、ラックの裏側には総延長約3.2kmの銅線が張り巡らされ、5000本の銅線でNVLinkのバックボーンネットワークを構成、400Gbpsの伝送速度を実現。Jensen Huang曰く:「数百ポンドあるかもしれないので、体格のいいCEOじゃないと務まらないよ」とのこと。 AI業界では「時間=金」。重要なデータとして、100兆パラメータのモデルをトレーニングする場合、RubinはBlackwellシステムの1/4台数で済み、Token生成コストはBlackwellの約1/10です。 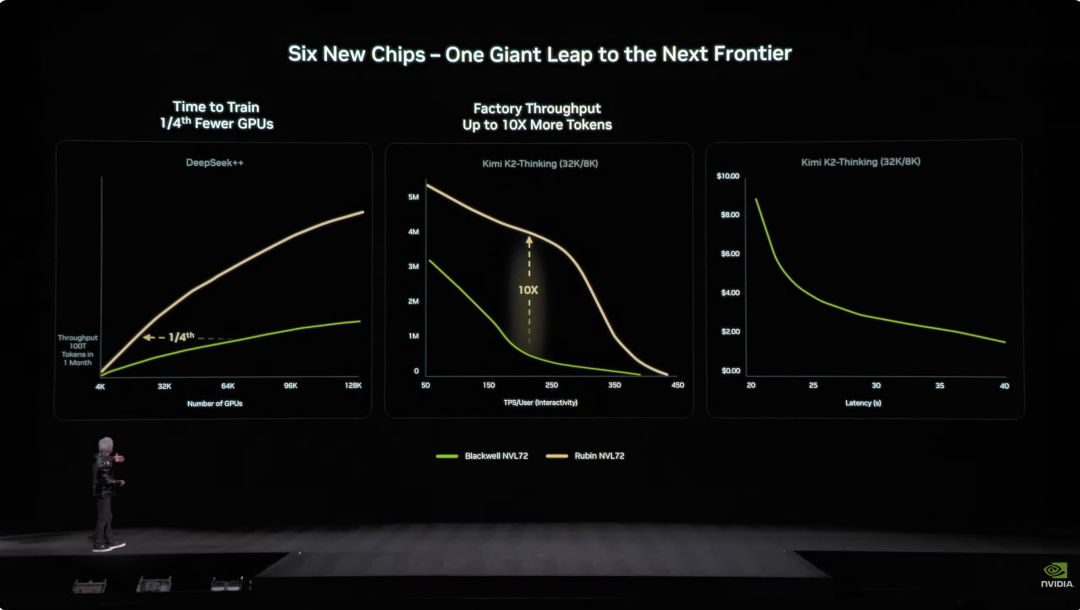 さらに、Rubinの消費電力はGrace Blackwellの2倍ですが、性能向上は消費電力増加を大きく上回り、推論性能は5倍、トレーニング性能は3.5倍向上しています。 より重要なのは、RubinはBlackwellと比べてスループット(1ワット・1ドルあたりのAI Token生成数)が10倍に向上していることです。コストが500億ドルのギガワット級データセンターにとって、これは収益力が直接倍増することを意味します。 これまでAI業界の最大の課題は、コンテキストメモリの不足でした。具体的には、AIは動作中に「KV Cache」(キー・バリューキャッシュ)を生成するのですが、これはAIの「ワーキングメモリ」です。会話が長くなったりモデルが大きくなるにつれ、HBMメモリが足りなくなっていました。
さらに、Rubinの消費電力はGrace Blackwellの2倍ですが、性能向上は消費電力増加を大きく上回り、推論性能は5倍、トレーニング性能は3.5倍向上しています。 より重要なのは、RubinはBlackwellと比べてスループット(1ワット・1ドルあたりのAI Token生成数)が10倍に向上していることです。コストが500億ドルのギガワット級データセンターにとって、これは収益力が直接倍増することを意味します。 これまでAI業界の最大の課題は、コンテキストメモリの不足でした。具体的には、AIは動作中に「KV Cache」(キー・バリューキャッシュ)を生成するのですが、これはAIの「ワーキングメモリ」です。会話が長くなったりモデルが大きくなるにつれ、HBMメモリが足りなくなっていました。  昨年NVIDIAはGrace-Blackwellアーキテクチャでメモリ拡張を発表しましたが、それでも不足。Vera Rubinの解決策は、ラック内にBlueField-4プロセッサを配備し、KV Cache専用に管理させることです。 各ノードに4つのBlueField-4があり、それぞれの背後に150TBのコンテキストメモリを持ち、GPUに割り当て。GPU1枚あたり追加で16TBメモリを獲得できます——GPU自体のメモリは約1TBしかないので、その差は大きい。しかも帯域は200Gbpsを維持し、速度も落ちません。 ただし容量だけでは不十分です。数十ラック、1万枚以上のGPUに分散した「付箋」が、あたかも一つのメモリのように協調動作するには、ネットワークが「大きく、速く、安定」している必要があります。そこでSpectrum-Xの出番です。 Spectrum-XはNVIDIAが世界初「生成AI専用」として開発したエンドツーエンドのイーサネットネットワークプラットフォームで、最新世代はTSMC COOPプロセスとシリコンフォトニクス技術を集積、512チャネル×200Gbpsの速度を実現。 Jensen Huangの試算によると、ギガワットデータセンター1棟の建設費は500億ドルですが、Spectrum-Xによって25%のスループット向上、50億ドルの節約になります。「このネットワークシステムはほぼ『タダ』みたいなものだ」とも。 セキュリティ面では、Vera RubinはConfidential Computing(機密計算)にも対応。すべてのデータは転送、保存、計算の全過程で暗号化され、PCIe、NVLink、CPU-GPU通信など全てのバスも含まれます。 企業は自社モデルを外部システムに安心してデプロイでき、データ漏洩の心配もありません。 DeepSeekが世界を驚かせ、オープンソースとエージェントがAIの主流に 本題が終わり、冒頭に戻ります。Jensen Huangは登壇後すぐに驚きの数字を披露。過去10年間で約10兆ドルが計算リソースに投入され、これが完全にモダナイズされつつあると述べました。 しかし、これは単なるハードウェアのアップグレードにとどまりません。より重要なのはソフトウェアパラダイムの転換です。彼は特に自主行動能力(Agentic)を備えたエージェントモデルに言及し、Cursorを名指しで取り上げ、NVIDIA社内のプログラミング方法を根本から変えたと紹介。
昨年NVIDIAはGrace-Blackwellアーキテクチャでメモリ拡張を発表しましたが、それでも不足。Vera Rubinの解決策は、ラック内にBlueField-4プロセッサを配備し、KV Cache専用に管理させることです。 各ノードに4つのBlueField-4があり、それぞれの背後に150TBのコンテキストメモリを持ち、GPUに割り当て。GPU1枚あたり追加で16TBメモリを獲得できます——GPU自体のメモリは約1TBしかないので、その差は大きい。しかも帯域は200Gbpsを維持し、速度も落ちません。 ただし容量だけでは不十分です。数十ラック、1万枚以上のGPUに分散した「付箋」が、あたかも一つのメモリのように協調動作するには、ネットワークが「大きく、速く、安定」している必要があります。そこでSpectrum-Xの出番です。 Spectrum-XはNVIDIAが世界初「生成AI専用」として開発したエンドツーエンドのイーサネットネットワークプラットフォームで、最新世代はTSMC COOPプロセスとシリコンフォトニクス技術を集積、512チャネル×200Gbpsの速度を実現。 Jensen Huangの試算によると、ギガワットデータセンター1棟の建設費は500億ドルですが、Spectrum-Xによって25%のスループット向上、50億ドルの節約になります。「このネットワークシステムはほぼ『タダ』みたいなものだ」とも。 セキュリティ面では、Vera RubinはConfidential Computing(機密計算)にも対応。すべてのデータは転送、保存、計算の全過程で暗号化され、PCIe、NVLink、CPU-GPU通信など全てのバスも含まれます。 企業は自社モデルを外部システムに安心してデプロイでき、データ漏洩の心配もありません。 DeepSeekが世界を驚かせ、オープンソースとエージェントがAIの主流に 本題が終わり、冒頭に戻ります。Jensen Huangは登壇後すぐに驚きの数字を披露。過去10年間で約10兆ドルが計算リソースに投入され、これが完全にモダナイズされつつあると述べました。 しかし、これは単なるハードウェアのアップグレードにとどまりません。より重要なのはソフトウェアパラダイムの転換です。彼は特に自主行動能力(Agentic)を備えたエージェントモデルに言及し、Cursorを名指しで取り上げ、NVIDIA社内のプログラミング方法を根本から変えたと紹介。 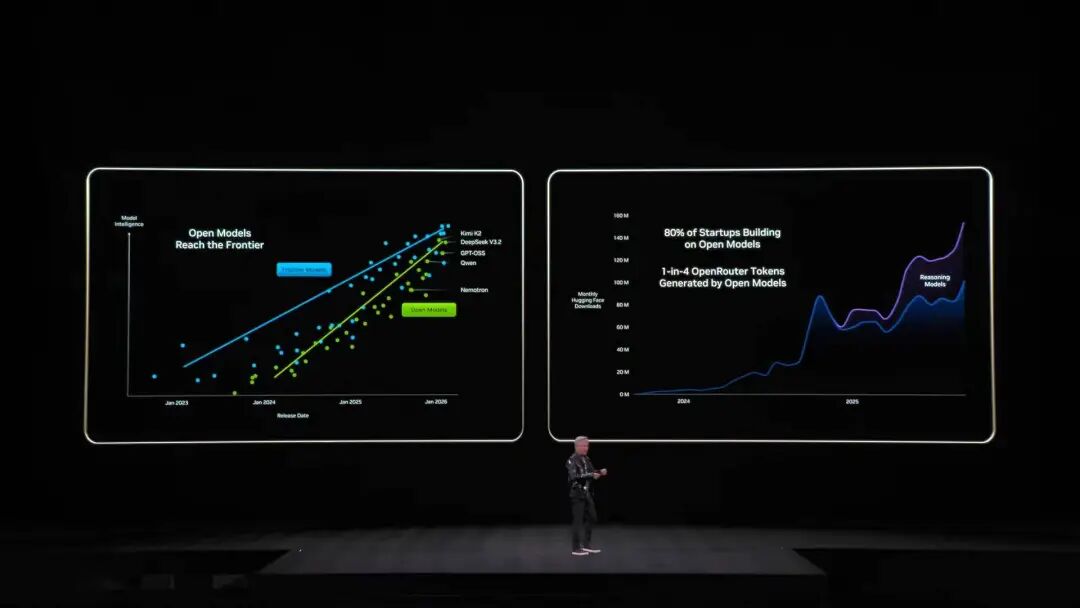 会場が最も沸いたのは、オープンソースコミュニティへの高評価。Jensen Huangは、昨年のDeepSeek V1のブレークスルーが世界中を驚かせ、世界初のオープンソース推論システムとして業界全体の発展の波を引き起こしたと直言。PPTでは、我々になじみのある国産プレイヤーKimi k2とDeepSeek V3.2が、それぞれオープンソース分野で第一位、第二位です。 Jensen Huangは、オープンソースモデルは現時点で最先端モデルに約6カ月遅れているかもしれませんが、6カ月ごとに新しいモデルが登場しており、 このイテレーションスピードにより、スタートアップから巨大企業、研究者まで誰もが見逃せない状況で、NVIDIAも例外ではありません。 そのため、今回はGPUだけを売るのではなく、NVIDIAは数十億ドル規模のDGX Cloudスーパーコンピュータを構築し、La Proteina(タンパク質合成)やOpenFold 3などの先端モデルも開発しています。
会場が最も沸いたのは、オープンソースコミュニティへの高評価。Jensen Huangは、昨年のDeepSeek V1のブレークスルーが世界中を驚かせ、世界初のオープンソース推論システムとして業界全体の発展の波を引き起こしたと直言。PPTでは、我々になじみのある国産プレイヤーKimi k2とDeepSeek V3.2が、それぞれオープンソース分野で第一位、第二位です。 Jensen Huangは、オープンソースモデルは現時点で最先端モデルに約6カ月遅れているかもしれませんが、6カ月ごとに新しいモデルが登場しており、 このイテレーションスピードにより、スタートアップから巨大企業、研究者まで誰もが見逃せない状況で、NVIDIAも例外ではありません。 そのため、今回はGPUだけを売るのではなく、NVIDIAは数十億ドル規模のDGX Cloudスーパーコンピュータを構築し、La Proteina(タンパク質合成)やOpenFold 3などの先端モデルも開発しています。  NVIDIAのオープンソースモデルエコシステムは、バイオ医薬、物理AI、エージェントモデル、ロボット、そして自動運転など幅広い分野をカバーしています。 また、NVIDIA Nemotronモデルファミリーの複数のオープンソースモデルも今回の講演のハイライトとなりました。音声、マルチモーダル、検索生成強化、安全性など多方面のオープンソースモデルが含まれており、Nemotronオープンソースモデルは多くのテストランキングで優秀な成績を収め、すでに多くの企業が採用しています。 物理AIとは何か、一気に数十種のモデルを発表 大規模言語モデルが「デジタル世界」の問題を解決したとすれば、NVIDIAの次なる野望は明らかに「物理世界」を制覇することです。Jensen Huangは、AIが物理法則を理解し現実で生きるにはデータが極めて希少だと述べました。 エージェントオープンソースモデルNemotronに続き、物理AI(Physical AI)構築のための「三台のコンピュータ」コアアーキテクチャを提案。
NVIDIAのオープンソースモデルエコシステムは、バイオ医薬、物理AI、エージェントモデル、ロボット、そして自動運転など幅広い分野をカバーしています。 また、NVIDIA Nemotronモデルファミリーの複数のオープンソースモデルも今回の講演のハイライトとなりました。音声、マルチモーダル、検索生成強化、安全性など多方面のオープンソースモデルが含まれており、Nemotronオープンソースモデルは多くのテストランキングで優秀な成績を収め、すでに多くの企業が採用しています。 物理AIとは何か、一気に数十種のモデルを発表 大規模言語モデルが「デジタル世界」の問題を解決したとすれば、NVIDIAの次なる野望は明らかに「物理世界」を制覇することです。Jensen Huangは、AIが物理法則を理解し現実で生きるにはデータが極めて希少だと述べました。 エージェントオープンソースモデルNemotronに続き、物理AI(Physical AI)構築のための「三台のコンピュータ」コアアーキテクチャを提案。 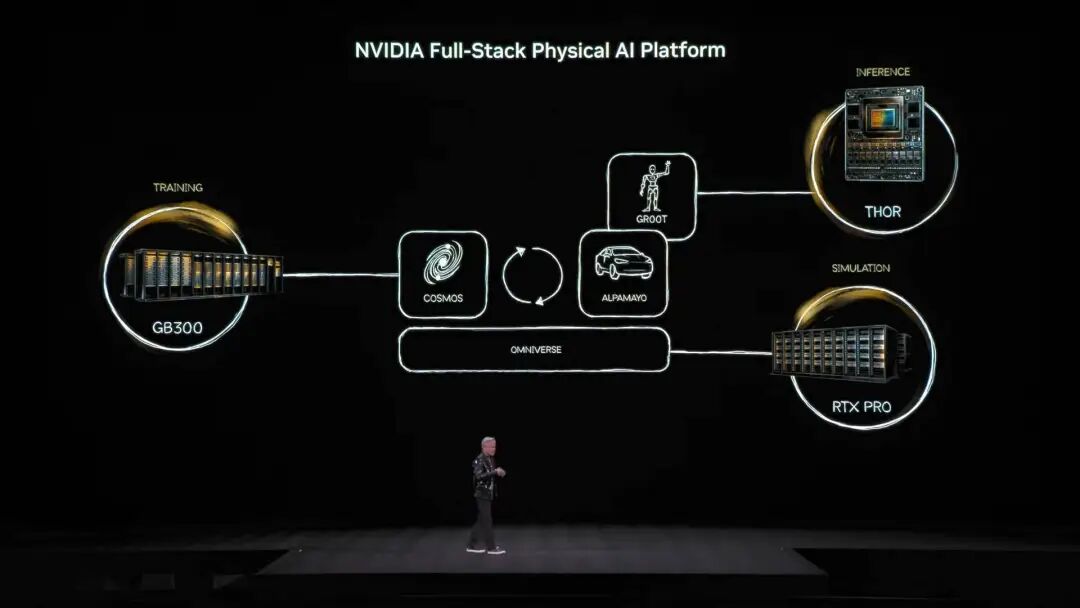
トレーニングコンピュータ、つまり私たちがよく知るトレーニング用GPUで構築された計算機(画像中のGB300アーキテクチャなど)。
推論コンピュータは、ロボットや車載エッジ端末で動作する「小脳」で、リアルタイム実行を担当。
シミュレーションコンピュータはOmniverseやCosmosを含み、AIに仮想トレーニング環境を提供し、シミュレーションで物理フィードバックを学習させます。 Cosmosシステムは大量の物理世界AIトレーニング環境を生成できます このアーキテクチャをもとに、Jensen Huangは世界初の思考・推論能力を持つ自動運転モデル「Alpamayo」を正式発表し、会場を驚かせました。
Cosmosシステムは大量の物理世界AIトレーニング環境を生成できます このアーキテクチャをもとに、Jensen Huangは世界初の思考・推論能力を持つ自動運転モデル「Alpamayo」を正式発表し、会場を驚かせました。  従来の自動運転と異なり、Alpamayoはエンドツーエンドでトレーニングされたシステムです。最大のブレークスルーは「ロングテール問題」を解決したこと。未知の複雑な道路状況でも、Alpamayoは単なるコードの実行だけでなく、人間の運転手のように推論ができるのです。 「次に何をするか、なぜその判断をしたかを説明してくれる」。デモでは車の運転が非常に自然で、極めて複雑なシーンも常識レベルに分解して処理していました。 デモだけでなく、これは実際に導入されます。Jensen HuangはAlpamayo技術スタックを搭載したメルセデスベンツCLAが今年第1四半期に米国で正式リリースされ、その後ヨーロッパやアジア市場にも順次展開されると発表しました。
従来の自動運転と異なり、Alpamayoはエンドツーエンドでトレーニングされたシステムです。最大のブレークスルーは「ロングテール問題」を解決したこと。未知の複雑な道路状況でも、Alpamayoは単なるコードの実行だけでなく、人間の運転手のように推論ができるのです。 「次に何をするか、なぜその判断をしたかを説明してくれる」。デモでは車の運転が非常に自然で、極めて複雑なシーンも常識レベルに分解して処理していました。 デモだけでなく、これは実際に導入されます。Jensen HuangはAlpamayo技術スタックを搭載したメルセデスベンツCLAが今年第1四半期に米国で正式リリースされ、その後ヨーロッパやアジア市場にも順次展開されると発表しました。  この車はNCAPで世界一安全な車と評価され、その自信はNVIDIA独自の「デュアルセーフティスタック」設計によるものです。エンドツーエンドAIモデルが状況に自信を持てない場合、システムは即座に従来の、より堅実な安全保護モードに切り替わり、絶対的な安全を確保します。 発表会ではJensen HuangがNVIDIAのロボット戦略も特別に披露しました。
この車はNCAPで世界一安全な車と評価され、その自信はNVIDIA独自の「デュアルセーフティスタック」設計によるものです。エンドツーエンドAIモデルが状況に自信を持てない場合、システムは即座に従来の、より堅実な安全保護モードに切り替わり、絶対的な安全を確保します。 発表会ではJensen HuangがNVIDIAのロボット戦略も特別に披露しました。 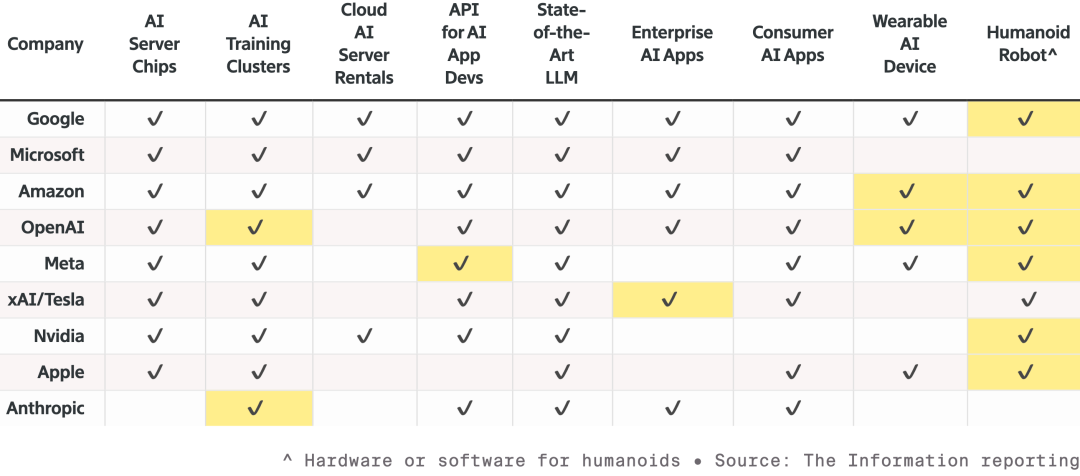 9大AIおよび関連ハードウェアメーカー間の競争状況。各社は製品ラインを拡大中で、特にロボット分野を狙っています。ハイライトされたセルは昨年以降の新製品です。 すべてのロボットはJetson小型コンピュータを搭載し、OmniverseプラットフォームのIsaacシミュレーターでトレーニングされます。NVIDIAはこの技術をSynopsys、Cadence、Siemensなど工業系プラットフォームにも統合中です。
9大AIおよび関連ハードウェアメーカー間の競争状況。各社は製品ラインを拡大中で、特にロボット分野を狙っています。ハイライトされたセルは昨年以降の新製品です。 すべてのロボットはJetson小型コンピュータを搭載し、OmniverseプラットフォームのIsaacシミュレーターでトレーニングされます。NVIDIAはこの技術をSynopsys、Cadence、Siemensなど工業系プラットフォームにも統合中です。  Jensen HuangはBoston Dynamics、Agilityなどのヒューマノイド・四足ロボットを「ステージ」に招待し、最も大きなロボットは実は工場そのものだと強調しました。 下から上まで、NVIDIAのビジョンは、将来のチップ設計、システム設計、工場シミュレーションまで、NVIDIA物理AIで加速するというものです。発表会ではDisneyロボットも登場し、Jensen Huangはこの可愛いロボットたちに向かって冗談を言いました: 「君たちはコンピュータの中で設計され、コンピュータの中で作られ、重力を体験する前にコンピュータの中でテストされ、検証されるんだ。」
Jensen HuangはBoston Dynamics、Agilityなどのヒューマノイド・四足ロボットを「ステージ」に招待し、最も大きなロボットは実は工場そのものだと強調しました。 下から上まで、NVIDIAのビジョンは、将来のチップ設計、システム設計、工場シミュレーションまで、NVIDIA物理AIで加速するというものです。発表会ではDisneyロボットも登場し、Jensen Huangはこの可愛いロボットたちに向かって冗談を言いました: 「君たちはコンピュータの中で設計され、コンピュータの中で作られ、重力を体験する前にコンピュータの中でテストされ、検証されるんだ。」  Jensen Huangでなければ、講演全体がまるでモデルメーカーの新製品発表会のように見えたかもしれません。 AIバブル論が渦巻く今日、ムーアの法則の鈍化に加え、Jensen HuangもAIが何を成し遂げられるかを示し、私たち一人一人のAIへの信頼を高める必要があるようです。 新しいAIスーパーコンピュータープラットフォーム「Vera Rubin」の強力なパフォーマンス発表だけでなく、応用やソフトウェアにもこれまで以上に力を入れ、AIがもたらす直感的な変化を私たちに最大限伝えようとしています。 そして、Jensen Huang自身が言うように、過去は仮想世界のためにチップを作り、今は自ら実演し、自動運転やヒューマノイドロボットに代表される物理AIに注力し、より競争の激しいリアルな物理世界へと乗り出しています。 結局のところ、戦争が始まらなければ武器は売れ続けません。 *最後にサプライズ動画:CESの講演時間制限のため、Jensen Huangは多くのPPTページを話しきれませんでした。そこで、未公開のPPTを使ったユーモラスなショート動画を作成。ぜひご覧ください⬇️
Jensen Huangでなければ、講演全体がまるでモデルメーカーの新製品発表会のように見えたかもしれません。 AIバブル論が渦巻く今日、ムーアの法則の鈍化に加え、Jensen HuangもAIが何を成し遂げられるかを示し、私たち一人一人のAIへの信頼を高める必要があるようです。 新しいAIスーパーコンピュータープラットフォーム「Vera Rubin」の強力なパフォーマンス発表だけでなく、応用やソフトウェアにもこれまで以上に力を入れ、AIがもたらす直感的な変化を私たちに最大限伝えようとしています。 そして、Jensen Huang自身が言うように、過去は仮想世界のためにチップを作り、今は自ら実演し、自動運転やヒューマノイドロボットに代表される物理AIに注力し、より競争の激しいリアルな物理世界へと乗り出しています。 結局のところ、戦争が始まらなければ武器は売れ続けません。 *最後にサプライズ動画:CESの講演時間制限のため、Jensen Huangは多くのPPTページを話しきれませんでした。そこで、未公開のPPTを使ったユーモラスなショート動画を作成。ぜひご覧ください⬇️ 
昨年の単独基調講演とは異なり、2026年のJensen Huangはスケジュールが過密です。NVIDIA LiveからSiemensのインダストリアルAIディスカッション、そしてLenovo TechWorldカンファレンスまで、48時間で3つのイベントを駆け抜けました。 前回はCESでRTX 50シリーズGPUを発表しました。今回は、物理AI、ロボティクス、そして重さ2.5トンの「 エンタープライズ級の核兵器 」が真の主役となりました。 Vera Rubinコンピューティングプラットフォームが登場、買えば買うほどお得 発表会中、エンターテイナーとしても知られるJensen Huangは、2.5トンのAIサーバーラックをステージに直接持ち込み、今回の発表の目玉である「Vera Rubinコンピューティングプラットフォーム」を紹介しました。このプラットフォームは、ダークマターを発見した天文学者にちなんで名付けられており、目標はただ一つ: AIトレーニングのスピードを加速し、次世代モデルの到来を早めることです。 通常、NVIDIAの社内ルールでは、各世代の製品で変更できるチップは1~2個までとされています。 しかし、今回のVera Rubinはこの常識を打破し、一度に6種類のチップを再設計し、すでに量産体制に入っています。 その理由は、ムーアの法則の鈍化に伴い、従来の性能向上のやり方ではAIモデルの年10倍の成長速度についていけなくなったからです。そこでNVIDIAは「究極の協調設計」を選択しました——すべてのチップとプラットフォームの各レイヤーで同時にイノベーションを行うのです。
この6つのチップは以下の通りです: 1. Vera CPU: - 88個のNVIDIAカスタムOlympusコア - NVIDIA空間マルチスレッディング技術を採用し、176スレッド対応 - NVLink C2C帯域幅1.8TB/s - システムメモリ1.5TB(Graceの3倍) - LPDDR5X帯域幅1.2TB/s - 2270億トランジスタ 2. Rubin GPU: - NVFP4推論性能50PFLOPS、前世代Blackwellの5倍 - 3360億トランジスタを搭載、Blackwell比1.6倍増 - 第三世代Transformerエンジンを搭載し、Transformerモデルの要求に応じて精度を動的に調整可能 3. ConnectX-9 ネットワークカード: - 200G PAM4 SerDesベースの800Gb/sイーサネット - プログラマブルRDMAとデータパスアクセラレーター - CNSAとFIPS認証取得 - 230億トランジスタ 4. BlueField-4 DPU: - 次世代AIストレージプラットフォーム向けに構築されたエンドツーエンドエンジン - SmartNICとストレージプロセッサー向け800G Gb/s DPU - ConnectX-9と組み合わせた64コアGrace CPU - 1260億トランジスタ 5. NVLink-6 スイッチチップ: - 18のコンピュートノードを接続し、最大72個のRubin GPUを一体として協調動作可能 - NVLink 6アーキテクチャ下では、各GPUが3.6TB/秒のall-to-all通信帯域を獲得 - 400G SerDes採用、In-Network SHARP Collectives対応、スイッチネットワーク内部でコレクティブ通信を完結 6. Spectrum-6 光イーサネットスイッチチップ - 512チャネル、各チャネル200Gbpsでより高速なデータ転送を実現 - TSMCのCOOPプロセスによるシリコンフォトニクス技術を集積 - 共封装光学インターフェース(copackaged optics)を装備 - 3520億トランジスタ 6種のチップの深い統合により、Vera Rubin NVL72システムの性能は前世代Blackwellに比べて全方位で向上しました。 NVFP4推論タスクでは、同チップは3.6EFLOPSという驚異的な計算力を達成し、前世代Blackwellアーキテクチャ比で5倍向上。NVFP4トレーニングでは2.5EFLOPSを達成し、3.5倍の性能アップです。 ストレージ容量面では、NVL72は54TBのLPDDR5Xメモリを搭載し、前世代の3倍。HBM(高帯域幅メモリ)容量は20.7TBで1.5倍増。帯域性能はHBM4で1.6PB/s、2.8倍向上。スケールアップ帯域は260TB/sと2倍増です。 これほどの性能向上にもかかわらず、トランジスタ数は1.7倍増の220兆個にとどまり、半導体製造技術の革新力を示しています。 エンジニアリング設計面でも、Vera Rubinは技術的ブレイクスルーをもたらしました。 これまでスーパーコンピュータノードは43本のケーブル接続が必要で、組立に2時間かかり、ミスも起こりやすかったのですが、Vera Rubinノードはケーブルゼロ、液冷パイプ6本だけで5分で完了。 さらに驚くべきは、ラックの裏側には総延長約3.2kmの銅線が張り巡らされ、5000本の銅線でNVLinkのバックボーンネットワークを構成、400Gbpsの伝送速度を実現。Jensen Huang曰く:「数百ポンドあるかもしれないので、体格のいいCEOじゃないと務まらないよ」とのこと。 AI業界では「時間=金」。重要なデータとして、100兆パラメータのモデルをトレーニングする場合、RubinはBlackwellシステムの1/4台数で済み、Token生成コストはBlackwellの約1/10です。 さらに、Rubinの消費電力はGrace Blackwellの2倍ですが、性能向上は消費電力増加を大きく上回り、推論性能は5倍、トレーニング性能は3.5倍向上しています。 より重要なのは、RubinはBlackwellと比べてスループット(1ワット・1ドルあたりのAI Token生成数)が10倍に向上していることです。コストが500億ドルのギガワット級データセンターにとって、これは収益力が直接倍増することを意味します。 これまでAI業界の最大の課題は、コンテキストメモリの不足でした。具体的には、AIは動作中に「KV Cache」(キー・バリューキャッシュ)を生成するのですが、これはAIの「ワーキングメモリ」です。会話が長くなったりモデルが大きくなるにつれ、HBMメモリが足りなくなっていました。 昨年NVIDIAはGrace-Blackwellアーキテクチャでメモリ拡張を発表しましたが、それでも不足。Vera Rubinの解決策は、ラック内にBlueField-4プロセッサを配備し、KV Cache専用に管理させることです。 各ノードに4つのBlueField-4があり、それぞれの背後に150TBのコンテキストメモリを持ち、GPUに割り当て。GPU1枚あたり追加で16TBメモリを獲得できます——GPU自体のメモリは約1TBしかないので、その差は大きい。しかも帯域は200Gbpsを維持し、速度も落ちません。 ただし容量だけでは不十分です。数十ラック、1万枚以上のGPUに分散した「付箋」が、あたかも一つのメモリのように協調動作するには、ネットワークが「大きく、速く、安定」している必要があります。そこでSpectrum-Xの出番です。 Spectrum-XはNVIDIAが世界初「生成AI専用」として開発したエンドツーエンドのイーサネットネットワークプラットフォームで、最新世代はTSMC COOPプロセスとシリコンフォトニクス技術を集積、512チャネル×200Gbpsの速度を実現。 Jensen Huangの試算によると、ギガワットデータセンター1棟の建設費は500億ドルですが、Spectrum-Xによって25%のスループット向上、50億ドルの節約になります。「このネットワークシステムはほぼ『タダ』みたいなものだ」とも。 セキュリティ面では、Vera RubinはConfidential Computing(機密計算)にも対応。すべてのデータは転送、保存、計算の全過程で暗号化され、PCIe、NVLink、CPU-GPU通信など全てのバスも含まれます。 企業は自社モデルを外部システムに安心してデプロイでき、データ漏洩の心配もありません。 DeepSeekが世界を驚かせ、オープンソースとエージェントがAIの主流に 本題が終わり、冒頭に戻ります。Jensen Huangは登壇後すぐに驚きの数字を披露。過去10年間で約10兆ドルが計算リソースに投入され、これが完全にモダナイズされつつあると述べました。 しかし、これは単なるハードウェアのアップグレードにとどまりません。より重要なのはソフトウェアパラダイムの転換です。彼は特に自主行動能力(Agentic)を備えたエージェントモデルに言及し、Cursorを名指しで取り上げ、NVIDIA社内のプログラミング方法を根本から変えたと紹介。 会場が最も沸いたのは、オープンソースコミュニティへの高評価。Jensen Huangは、昨年のDeepSeek V1のブレークスルーが世界中を驚かせ、世界初のオープンソース推論システムとして業界全体の発展の波を引き起こしたと直言。PPTでは、我々になじみのある国産プレイヤーKimi k2とDeepSeek V3.2が、それぞれオープンソース分野で第一位、第二位です。 Jensen Huangは、オープンソースモデルは現時点で最先端モデルに約6カ月遅れているかもしれませんが、6カ月ごとに新しいモデルが登場しており、 このイテレーションスピードにより、スタートアップから巨大企業、研究者まで誰もが見逃せない状況で、NVIDIAも例外ではありません。 そのため、今回はGPUだけを売るのではなく、NVIDIAは数十億ドル規模のDGX Cloudスーパーコンピュータを構築し、La Proteina(タンパク質合成)やOpenFold 3などの先端モデルも開発しています。 NVIDIAのオープンソースモデルエコシステムは、バイオ医薬、物理AI、エージェントモデル、ロボット、そして自動運転など幅広い分野をカバーしています。 また、NVIDIA Nemotronモデルファミリーの複数のオープンソースモデルも今回の講演のハイライトとなりました。音声、マルチモーダル、検索生成強化、安全性など多方面のオープンソースモデルが含まれており、Nemotronオープンソースモデルは多くのテストランキングで優秀な成績を収め、すでに多くの企業が採用しています。 物理AIとは何か、一気に数十種のモデルを発表 大規模言語モデルが「デジタル世界」の問題を解決したとすれば、NVIDIAの次なる野望は明らかに「物理世界」を制覇することです。Jensen Huangは、AIが物理法則を理解し現実で生きるにはデータが極めて希少だと述べました。 エージェントオープンソースモデルNemotronに続き、物理AI(Physical AI)構築のための「三台のコンピュータ」コアアーキテクチャを提案。 トレーニングコンピュータ、つまり私たちがよく知るトレーニング用GPUで構築された計算機(画像中のGB300アーキテクチャなど)。
推論コンピュータは、ロボットや車載エッジ端末で動作する「小脳」で、リアルタイム実行を担当。
シミュレーションコンピュータはOmniverseやCosmosを含み、AIに仮想トレーニング環境を提供し、シミュレーションで物理フィードバックを学習させます。
Cosmosシステムは大量の物理世界AIトレーニング環境を生成できます このアーキテクチャをもとに、Jensen Huangは世界初の思考・推論能力を持つ自動運転モデル「Alpamayo」を正式発表し、会場を驚かせました。 従来の自動運転と異なり、Alpamayoはエンドツーエンドでトレーニングされたシステムです。最大のブレークスルーは「ロングテール問題」を解決したこと。未知の複雑な道路状況でも、Alpamayoは単なるコードの実行だけでなく、人間の運転手のように推論ができるのです。 「次に何をするか、なぜその判断をしたかを説明してくれる」。デモでは車の運転が非常に自然で、極めて複雑なシーンも常識レベルに分解して処理していました。 デモだけでなく、これは実際に導入されます。Jensen HuangはAlpamayo技術スタックを搭載したメルセデスベンツCLAが今年第1四半期に米国で正式リリースされ、その後ヨーロッパやアジア市場にも順次展開されると発表しました。 この車はNCAPで世界一安全な車と評価され、その自信はNVIDIA独自の「デュアルセーフティスタック」設計によるものです。エンドツーエンドAIモデルが状況に自信を持てない場合、システムは即座に従来の、より堅実な安全保護モードに切り替わり、絶対的な安全を確保します。 発表会ではJensen HuangがNVIDIAのロボット戦略も特別に披露しました。 9大AIおよび関連ハードウェアメーカー間の競争状況。各社は製品ラインを拡大中で、特にロボット分野を狙っています。ハイライトされたセルは昨年以降の新製品です。 すべてのロボットはJetson小型コンピュータを搭載し、OmniverseプラットフォームのIsaacシミュレーターでトレーニングされます。NVIDIAはこの技術をSynopsys、Cadence、Siemensなど工業系プラットフォームにも統合中です。 Jensen HuangはBoston Dynamics、Agilityなどのヒューマノイド・四足ロボットを「ステージ」に招待し、最も大きなロボットは実は工場そのものだと強調しました。 下から上まで、NVIDIAのビジョンは、将来のチップ設計、システム設計、工場シミュレーションまで、NVIDIA物理AIで加速するというものです。発表会ではDisneyロボットも登場し、Jensen Huangはこの可愛いロボットたちに向かって冗談を言いました: 「君たちはコンピュータの中で設計され、コンピュータの中で作られ、重力を体験する前にコンピュータの中でテストされ、検証されるんだ。」 Jensen Huangでなければ、講演全体がまるでモデルメーカーの新製品発表会のように見えたかもしれません。 AIバブル論が渦巻く今日、ムーアの法則の鈍化に加え、Jensen HuangもAIが何を成し遂げられるかを示し、私たち一人一人のAIへの信頼を高める必要があるようです。 新しいAIスーパーコンピュータープラットフォーム「Vera Rubin」の強力なパフォーマンス発表だけでなく、応用やソフトウェアにもこれまで以上に力を入れ、AIがもたらす直感的な変化を私たちに最大限伝えようとしています。 そして、Jensen Huang自身が言うように、過去は仮想世界のためにチップを作り、今は自ら実演し、自動運転やヒューマノイドロボットに代表される物理AIに注力し、より競争の激しいリアルな物理世界へと乗り出しています。 結局のところ、戦争が始まらなければ武器は売れ続けません。 *最後にサプライズ動画:CESの講演時間制限のため、Jensen Huangは多くのPPTページを話しきれませんでした。そこで、未公開のPPTを使ったユーモラスなショート動画を作成。ぜひご覧ください⬇️ 0
0
免責事項:本記事の内容はあくまでも筆者の意見を反映したものであり、いかなる立場においても当プラットフォームを代表するものではありません。また、本記事は投資判断の参考となることを目的としたものではありません。
PoolX: 資産をロックして新しいトークンをゲット
最大12%のAPR!エアドロップを継続的に獲得しましょう!
今すぐロック
こちらもいかがですか?
トランプのグリーンランドへの関税がEUの宥和戦略を完全に頓挫させた
101 finance•2026/01/18 22:38
欧州理事会がトランプの関税およびEUの報復措置に関する緊急会議を招集
Cointelegraph•2026/01/18 22:32
AppleがGoogleと協力してSiriにAIを強化、今はAAPL株に投資する絶好のタイミングか?
101 finance•2026/01/18 22:05
米国・EUの緊張激化で仮想通貨市場が波乱の時期に備える
Cointurk•2026/01/18 21:26
暗号資産価格
もっと見るBitcoin
BTC
$95,472.66
+0.40%
Ethereum
ETH
$3,348.55
+1.40%
Tether USDt
USDT
$0.9997
+0.01%
BNB
BNB
$950.79
+0.39%
XRP
XRP
$2.06
-0.20%
Solana
SOL
$142.63
-0.71%
USDC
USDC
$0.9999
+0.02%
TRON
TRX
$0.3202
+0.55%
Dogecoin
DOGE
$0.1376
-0.05%
Cardano
ADA
$0.3958
-0.11%
PIの売却方法
BitgetがPIを上場 - BitgetでPIを簡単に売買しよう!
今すぐ取引する
まだBitgetに登録していませんか?Bitget新規ユーザー向けの6,200 USDTウェルカムパック!
今すぐ登録する