要点まとめ
- DeepSeek V4は数週間以内にリリースされ、エリートレベルのコーディング性能を目指している可能性がある。
- 関係者によれば、長文のコードタスクにおいてClaudeやChatGPTを上回る可能性があるという。
- 開発者たちは、近い将来の大きな変革に向けてすでに期待を高めている。
Decryptのアート、ファッション、エンターテインメントハブ。
SCENEを発見 DeepSeekは、2月中旬ごろにV4モデルをリリースする計画を立てていると報じられており、社内テストの結果が事実であれば、シリコンバレーの大手AI企業は警戒すべきだろう。
杭州を拠点とするこのAIスタートアップは、2月17日(旧正月)前後のリリースを狙っており、コーディングタスクに特化したモデルを展開する可能性があるという。
プロジェクトに直接関わる人物によれば、V4はAnthropicのClaudeやOpenAIのGPTシリーズを社内ベンチマークで上回っており、特に非常に長いコードプロンプトの扱いでその傾向が顕著だという。
もちろん、モデルに関するベンチマークや情報は公表されていないため、これらの主張を直接検証することはできない。DeepSeekも噂について正式なコメントはしていない。
それでも、開発者コミュニティは公式な発表を待っていない。Redditのr/DeepSeekやr/LocalLLaMAはすでに盛り上がりを見せており、ユーザーはAPIクレジットを蓄え、X(旧Twitter)の熱心なファンたちはV4がDeepSeekをシリコンバレーの何十億ドルものルールに従わないアンダードッグとして確立する可能性を早くも語っている。
AnthropicはOpenCodeのようなサードパーティアプリでClaudeのサブスクリプションをブロックし、xAIやOpenAIのアクセスも遮断したとのこと。
ClaudeやClaude Codeは素晴らしいが、まだ10倍優れているとは言い難い。これは他のラボにもコーディングモデルやエージェントの開発を加速させる動機となるだろう。
DeepSeek V4のリリースが噂されている…
— Yuchen Jin (@Yuchenj_UW) 2026年1月9日
これがDeepSeek初の大きなインパクトというわけではない。2025年1月にR1推論モデルをリリースした際には、世界の市場で1兆ドル規模の売りが発生した。
その理由は、DeepSeekのR1がOpenAIのo1モデルと同等の数学・推論ベンチマークを達成しながら、開発コストがわずか600万ドルだったとされているためだ。これは競合他社の約68分の1のコストである。さらにV3モデルはMATH-500ベンチマークで90.2%を達成し、Claudeの78.3%を大きく上回った。「V3.2 Speciale」のアップデートでさらに性能が向上した。
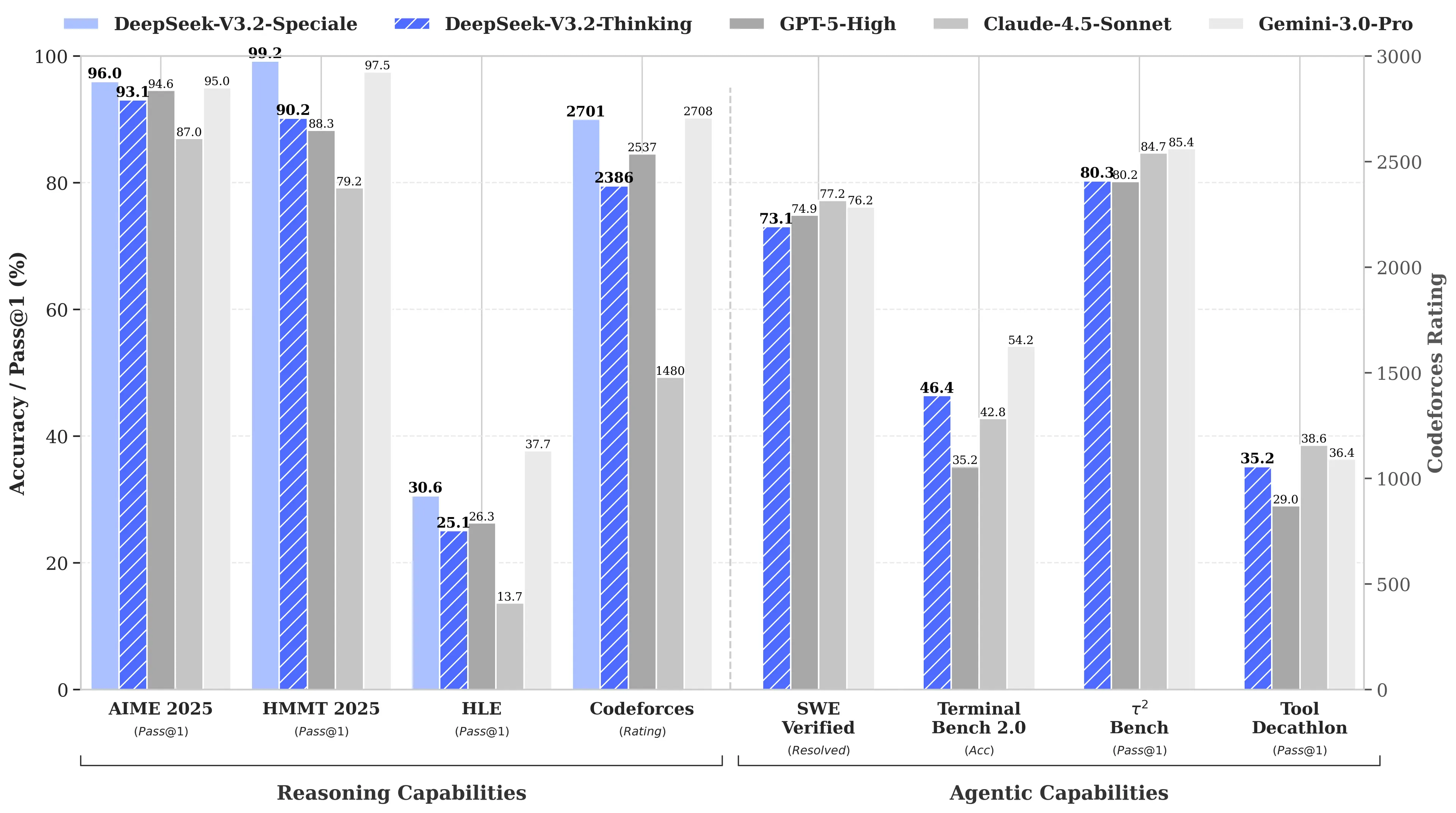
Image: DeepSeek
V4のコーディング重視は戦略的な転換となる。R1が純粋な推論(論理、数学、形式的証明)に重点を置いたのに対し、V4は推論と非推論タスクのハイブリッドモデルであり、高精度なコード生成が直接収益に結びつくエンタープライズ開発者市場をターゲットとしている。
覇権を握るためには、V4は現在SWE-bench Verified記録80.9%を持つClaude Opus 4.5を上回る必要がある。しかし、DeepSeekのこれまでのリリース実績を考えれば、中国のAIラボが直面する様々な制約があっても、不可能ではないかもしれない。
あまりにも有名な秘密のソース
仮に噂が本当だとすれば、この小規模ラボはどうやってそんな偉業を成し遂げているのだろうか?
同社の秘密兵器は、1月1日付の研究論文「Manifold-Constrained Hyper-Connections(mHC)」にあるかもしれない。創業者のLiang Wenfengが共著したこの新しいトレーニング手法は、大規模言語モデルのスケーリングにおける根本的な課題―モデルの容量を拡大しつつ、不安定化や学習崩壊を防ぐ―に取り組んでいる。
従来のAIアーキテクチャは、全ての情報を1本の狭い経路に通していた。mHCでは、その経路を複数のストリームに広げ、相互に情報をやりとりしながら学習崩壊を防ぐことができる。
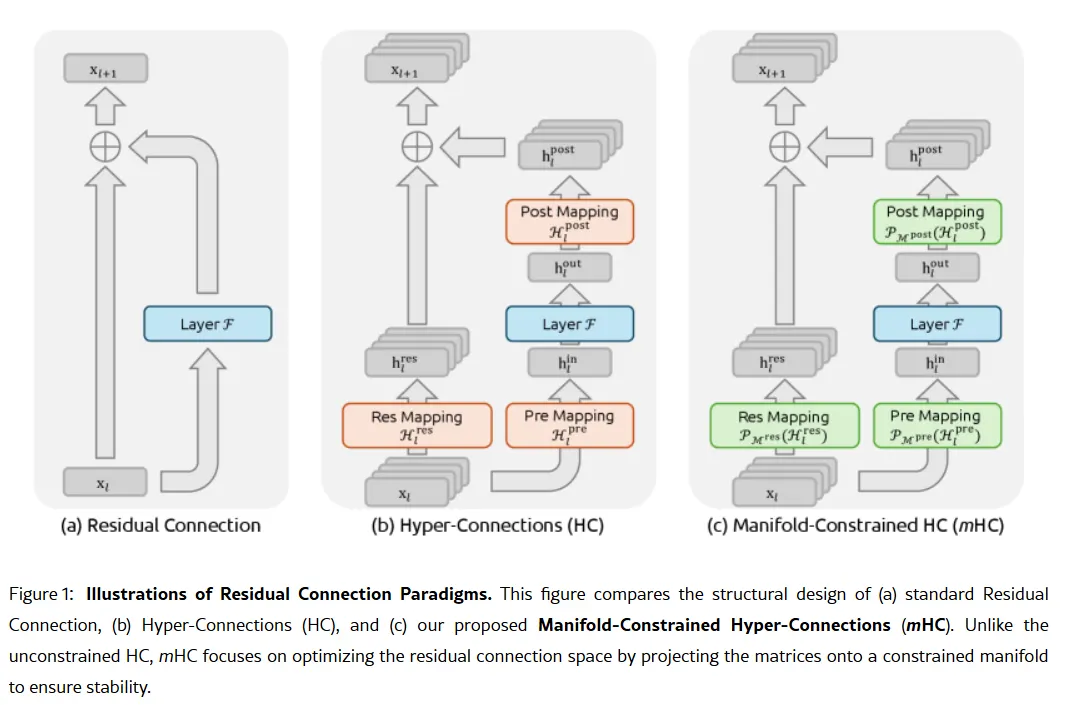
Image: DeepSeek
Counterpoint ResearchのAI主任アナリストであるWei Sun氏は、
でこの手法を「際立ったブレイクスルー」と評価した。彼女は、米国の輸出規制により先進的なチップへのアクセスが限られていても、DeepSeekが「計算ボトルネックを回避し、知能の飛躍を実現できる」と述べている。
Omdiaの主任アナリストであるLian Jye Su氏は、DeepSeekが自社の手法を公開していることは「中国AI業界の新たな自信の表れ」だと指摘する。同社のオープンソースアプローチは、かつてのOpenAIがそうであったように、開発者たちに支持されている。
すべての人が納得しているわけではない。Redditの一部開発者は、DeepSeekの推論モデルが単純なタスクに計算資源を浪費していると不満を漏らし、批判者は同社のベンチマークが実世界の複雑さを反映していないと主張する。2025年4月には「DeepSeekはひどい―もう良いふりはしない」というタイトルのMedium記事がバイラルになり、「バグだらけの定型文ナンセンス」や「幻覚ライブラリ」を生み出していると非難した。
DeepSeekには課題もある。プライバシーへの懸念から、いくつかの政府がDeepSeekのネイティブアプリを禁止している。同社の中国とのつながりや、モデル内の検閲に関する疑問は、技術的議論に地政学的な摩擦を加えている。
それでも勢いは明らかだ。DeepSeekはアジアで広く採用されており、V4がコーディング性能の約束を果たせば、西側企業での導入も進むだろう。
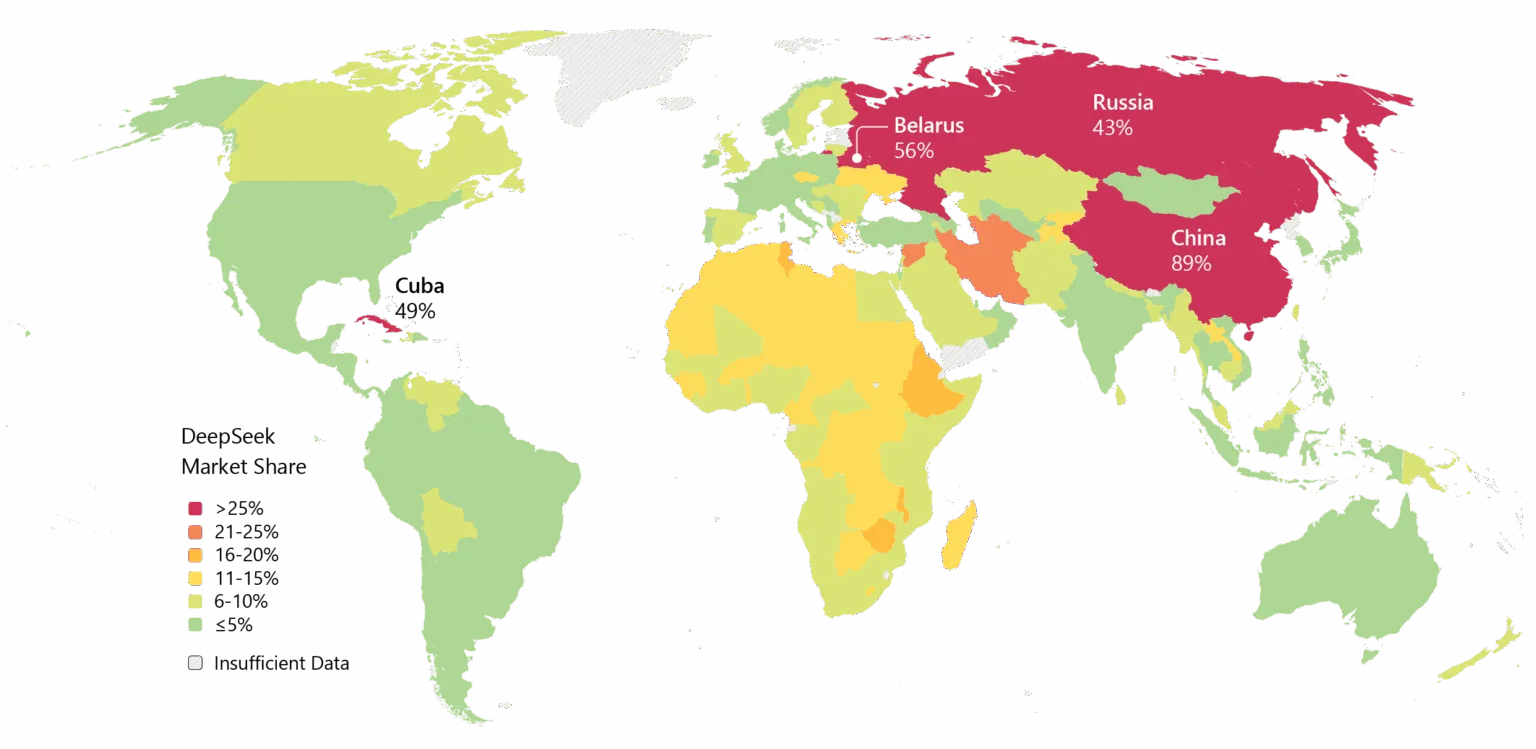
Image: Microsoft
タイミングも重要だ。
によれば、DeepSeekはもともと2025年5月にR2モデルをリリースする計画だったが、創業者のLiang氏がその性能に満足できなかったため、開発期間を延長した。現在、V4が2月リリースを目指し、R2が8月に続く可能性がある中、同社は急を要するのか、それとも自信の表れなのか、どちらとも取れるスピードで動いている。


