Sa madaling sabi
- Maaaring ilabas ang DeepSeek V4 sa loob ng ilang linggo, na may layuning makamit ang mataas na antas ng pagganap sa pag-code.
- Ayon sa mga insider, maaaring malampasan nito ang Claude at ChatGPT sa mga gawain na nangangailangan ng mahabang code contexts.
- Ang mga developer ay abala na sa paghahanda bago pa man ang posibleng malaking pagbabago.
Ayon sa mga ulat, ang DeepSeek ay nagpaplanong ilabas ang V4 model nito sa kalagitnaan ng Pebrero, at kung pagbabatayan ang mga panloob na pagsubok, dapat kabahan ang mga AI giants ng Silicon Valley.
Ang AI startup na nakabase sa Hangzhou ay maaaring naglalayong maglabas sa paligid ng Pebrero 17—Lunar New Year, syempre—ng isang modelong partikular na dinisenyo para sa mga gawain sa pag-code, ayon sa
. Ayon sa mga taong may direktang kaalaman sa proyekto, ang V4 ay nalalampasan ang parehong Claude ng Anthropic at ang GPT series ng OpenAI sa mga panloob na benchmark, partikular pagdating sa napakahabang code prompts.
Siyempre, walang benchmark o impormasyon tungkol sa model na naibahagi sa publiko, kaya hindi direktang mapatutunayan ang mga ganitong pahayag. Hindi rin kinumpirma ng DeepSeek ang mga tsismis.
Gayunpaman, hindi naghihintay ang developer community ng opisyal na anunsyo. Ang r/DeepSeek at r/LocalLLaMA sa Reddit ay mainit na, nagsasagawa na ng pag-iipon ng API credits ang mga user, at mabilis na nagbabahagi ng prediksyon ang mga mahihilig sa X na maaaring ilatag ng V4 ang posisyon ng DeepSeek bilang mapangahas na underdog na ayaw sumunod sa bilyon-dolyar na mga patakaran ng Silicon Valley.
Hinarang ng Anthropic ang Claude subs sa mga third-party apps gaya ng OpenCode, at sinasabing pinutol ang access ng xAI at OpenAI.
Magaling ang Claude at Claude Code, pero hindi pa 10x na mas magaling. Ito ay magtutulak lamang sa ibang labs na pabilisin ang pag-unlad ng kanilang mga coding models/agents.
DeepSeek V4 ay pinaniniwalaang ilalabas…
— Yuchen Jin (@Yuchenj_UW) Enero 9, 2026
Hindi ito ang unang malaking pagbabago mula sa DeepSeek. Nang inilabas ng kumpanya ang R1 reasoning model nito noong Enero 2025, nagdulot ito ng $1 trilyong pagbebenta sa pandaigdigang mga merkado.
Ang dahilan? Ang R1 ng DeepSeek ay tumapat sa o1 model ng OpenAI sa mga benchmark ng math at reasoning kahit na iniulat na $6 milyon lamang ang ginastos sa pag-develop nito—humigit-kumulang 68 beses na mas mura kaysa sa ginastos ng mga kakumpitensya. Ang V3 model nito ay nakakuha ng 90.2% sa MATH-500 benchmark, na nalampasan ang 78.3% ni Claude, at ang kamakailang update na “V3.2 Speciale” ay lalo pang pinahusay ang performance nito.
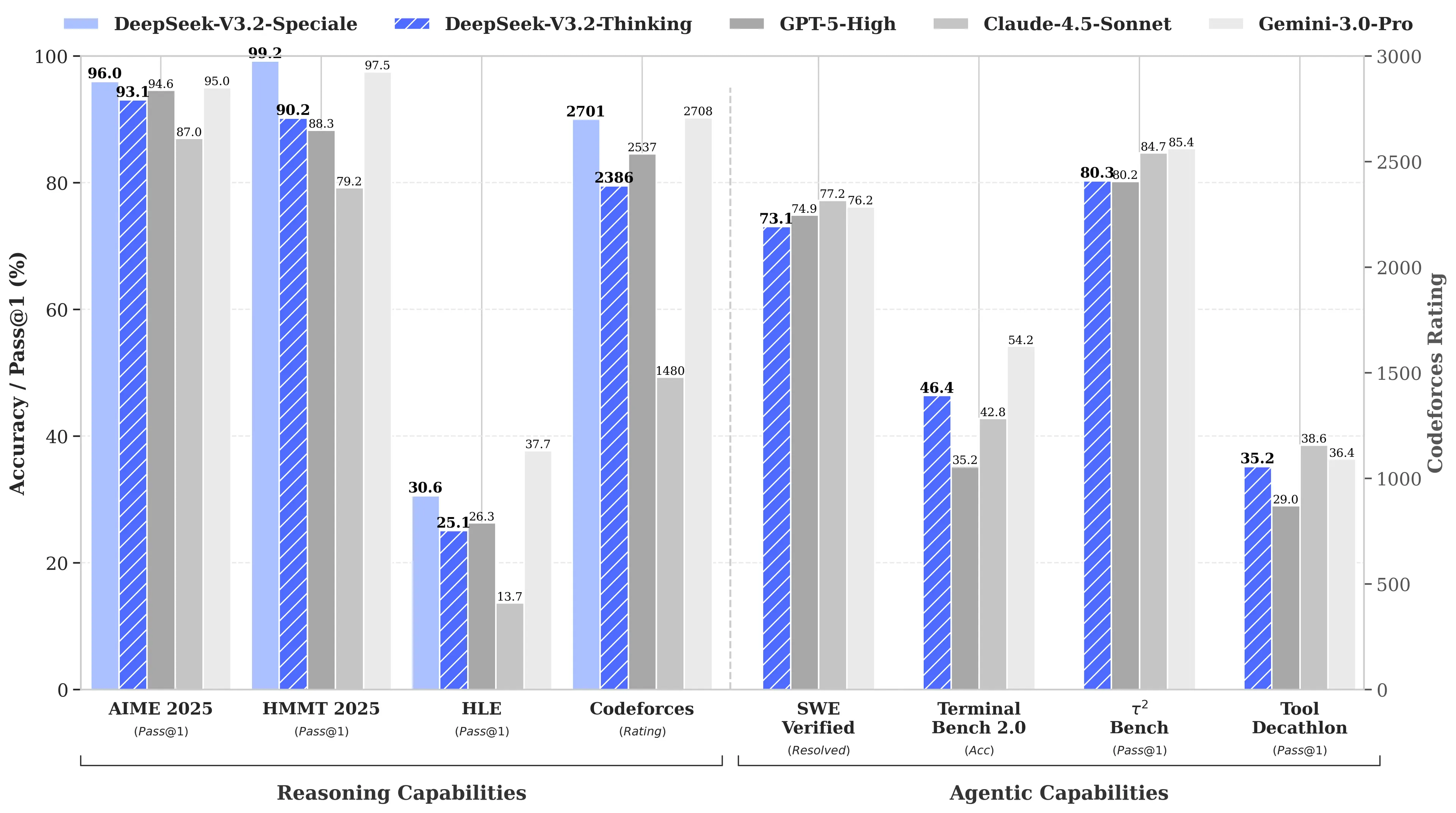
Image: DeepSeek
Ang pokus sa pag-code ng V4 ay magiging isang estratehikong pagbabago. Habang ang R1 ay nagbigay-diin sa purong reasoning—lohika, math, formal proofs—ang V4 ay isang hybrid na modelo (reasoning at non-reasoning tasks) na layong targetin ang enterprise developer market kung saan ang mataas na katumpakan sa code generation ay direktang nagreresulta sa kita.
Upang magtagumpay, kailangang malampasan ng V4 ang Claude Opus 4.5, na kasalukuyang may hawak ng SWE-bench Verified record na 80.9%. Ngunit kung pagbabatayan ang mga naunang paglulunsad ng DeepSeek, maaaring posible itong makamit kahit pa may mga limitasyong hinaharap ng isang Chinese AI lab.
Ang hindi na lihim na sangkap
Kung totoo ang mga tsismis, paano nagagawa ng maliit na laboratoryong ito ang ganitong tagumpay?
Ang lihim na sandata ng kumpanya ay maaaring nasa kanilang research paper noong Enero 1: Manifold-Constrained Hyper-Connections, o mHC. Kasama ang tagapagtatag na si Liang Wenfeng bilang may-akda, ang bagong training method na ito ay tumutugon sa pangunahing problema sa pag-scale ng malalaking language model—kung paano palawakin ang kakayahan ng modelo nang hindi ito nagiging unstable o sumasabog habang sinasanay.
Ang mga tradisyunal na AI architecture ay pinipilit ang lahat ng impormasyon sa iisang makipot na daanan. Pinapalawak ng mHC ang daanang iyon sa maraming stream na maaaring magpalitan ng impormasyon nang hindi nagdudulot ng training collapse.
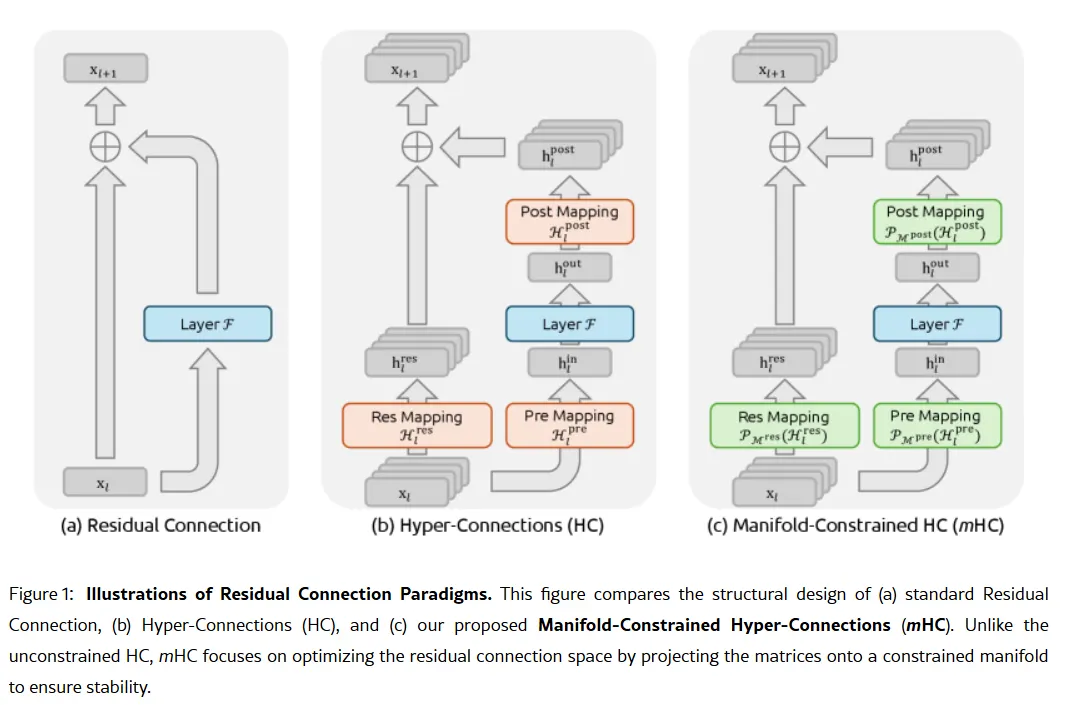
Image: DeepSeek
Tinawag ni Wei Sun, principal analyst para sa AI sa Counterpoint Research, ang mHC bilang isang "kapansin-pansing breakthrough" sa komentaryo sa
. Ayon sa kanya, ipinapakita ng teknik na ito na maaaring "lampasan ng DeepSeek ang mga compute bottleneck at makamit ang malalaking pag-angat sa intelligence," kahit na may limitadong access sa mga advanced na chips dulot ng mga restriksyon sa pag-export ng U.S.
Ipinunto ni Lian Jye Su, chief analyst sa Omdia, na ang kahandaang ibahagi ng DeepSeek ang kanilang mga pamamaraan ay nagpapakita ng "bagong kumpiyansa sa industriyang AI ng Tsina." Ang open-source na pamamaraan ng kumpanya ay naging paborito ng mga developer na nakikita ito bilang pagsasabuhay ng kung ano ang dating OpenAI, bago ito lumipat sa closed models at bilyon-dolyar na fundraising rounds.
Hindi lahat ay kumbinsido. May ilang developer sa Reddit ang nagrereklamo na ang reasoning models ng DeepSeek ay nasasayang ang compute sa mga simpleng gawain, habang ang mga kritiko ay nagsasabing hindi sumasalamin ang mga benchmark ng kumpanya sa kaguluhan ng totoong mundo. Isang Medium post na pinamagatang "DeepSeek Sucks—At Tapos Na Akong Magkunwari Na Hindi" ang naging viral noong Abril 2025, na nagpaparatang na ang mga modelo ay gumagawa ng "boilerplate nonsense na may bugs" at "hinallucinate na mga library."
May dinadala ring isyu ang DeepSeek. Ang mga alalahanin sa privacy ay palaging nakakabit sa kumpanya, kung saan ipinagbawal ng ilang gobyerno ang native app ng DeepSeek. Ang koneksyon ng kumpanya sa Tsina at ang mga tanong tungkol sa censorship sa mga modelo nito ay nagdadagdag ng geopolitical na tensyon sa mga teknikal na diskusyon.
Gayunpaman, hindi mapipigilan ang momentum. Malawak nang ginagamit ang DeepSeek sa Asya, at kung matutupad ng V4 ang mga pangako nito sa pag-code, maaaring sumunod ang enterprise adoption sa Kanluran.
Image: Microsoft
May isyu rin sa timing. Ayon sa
, orihinal na planong ilabas ng DeepSeek ang R2 model nito noong Mayo 2025, ngunit pinalawig ang timeline nang hindi nasiyahan ang founder na si Liang sa performance nito. Ngayon, kapag na-target ng V4 ang Pebrero at posibleng sumunod ang R2 sa Agosto, mabilis na gumagalaw ang kumpanya na nagpapahiwatig ng pagkaapurahan—o kumpiyansa. Marahil pareho.